In early 2024, a mid-sized SaaS company in Austin ran an internal audit of their AI costs. What they found was humbling.
Their engineers had wired GPT-4 into nearly every customer touchpoint — support tickets, onboarding flows, internal documentation retrieval, even routine form validation. The architecture looked impressive on a whiteboard. In practice, they were spending over $40,000 a month on API calls, with roughly 60% of those calls doing work that could have been handled by a $0.002-per-1,000-token model instead of a $0.03 one. Nobody had made a bad decision. Each team had optimized for speed of implementation. The result was a system that worked perfectly and cost absurdly.
They cut their bill by 68% in six weeks. Not by switching providers. Not by reducing functionality. By thinking differently about what required intelligence and what didn’t.
This story is playing out thousands of times across the industry right now. Quietly. Expensively.
The Illusion of More Is Better
There’s a seductive logic to throwing your best model at every problem. If GPT-4o is smarter than GPT-3.5, why wouldn’t you use it everywhere? If Claude Opus is more capable than Haiku, shouldn’t you maximize capability?
This is the wrong mental model.
Token consumption isn’t just a cost problem. It’s a systems design problem.
The engineers who truly understand AI — the ones building at Cohere, Anthropic’s internal tools teams, at serious AI-native startups like Cognition and Magic — don’t think in terms of “which model.” They think in terms of: what is the minimum sufficient intelligence for this specific task, given this context, at this moment?
That’s a fundamentally different question. And answering it well is the difference between a profitable AI product and a money pit that scales costs faster than revenue.
What “Advanced” Actually Means
Here’s the uncomfortable truth: most people using AI at an “advanced” level are still thinking like power users, not systems architects.
Advanced AI usage isn’t about writing longer prompts. It isn’t about using the biggest model. It isn’t even about chaining five agents together in a fancy workflow.
Advanced AI usage is precision. It’s knowing when to use a hammer and when to use a scalpel. It’s designing systems where intelligence is deployed surgically — at exactly the moments it creates value — and automation handles everything else.
The researchers at Stanford’s HAI (Human-Centered AI Institute) have been studying this since 2022. Their findings, published across multiple working papers, point to a consistent pattern: the most effective AI implementations treat language models as specialized components in a larger system, not as universal problem-solvers.
That distinction sounds simple. In practice, it requires rethinking almost everything.
A Technical Breakdown (In Plain English)
Let’s get into the mechanics without the jargon spiral.
Every interaction with an AI model consumes tokens — the fundamental unit of text that models process. Input tokens (what you send) and output tokens (what you receive back) both cost money and add latency. With most frontier models, output tokens cost 3–5x more than input tokens. This alone changes how you should think about prompt design.
Here’s what most people miss about token economics:
Context is not free. When you send a 10,000-token document to GPT-4o and ask a question that could have been answered with a 500-token excerpt, you just spent 20x more than necessary. The model doesn’t get “smarter” because it saw more context. It gets slower and more expensive.
Model capability has a ceiling per task. For classification tasks — routing a support ticket, extracting a date, detecting sentiment — a fine-tuned small model outperforms a frontier model at 1/50th the cost. This has been demonstrated repeatedly in academic benchmarks and real-world deployments. A 2023 study from Databricks showed that fine-tuned 7B parameter models matched GPT-4 on specific domain tasks with less than 100 training examples.
Repetition kills margins. Every time your system re-explains the same context — your product features, your company’s tone guidelines, your data schema — to a model that has no memory of previous calls, you’re paying for that context again. And again. And again.
These three dynamics — context waste, model-task mismatch, and repetition overhead — account for the majority of unnecessary token spend across most production AI systems.
The Architecture of Efficiency: Four Principles
Top AI teams operate with a mental framework that most people never articulate explicitly. Here it is:
1. The Intelligence Routing Principle
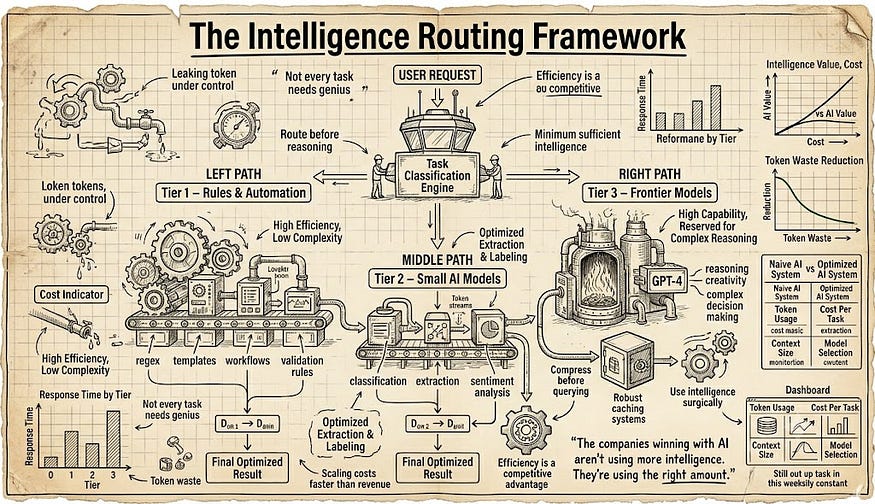
Not all tasks require the same cognitive overhead. Map your workflows into three tiers:
- Tier 1 — Rule-based or structured extraction: regex, templates, deterministic logic. Zero AI needed.
- Tier 2 — Pattern recognition and classification: small models, fine-tuned or prompted with tight constraints.
- Tier 3 — Genuine reasoning, synthesis, creativity: frontier models, used sparingly.
The mistake most teams make is treating everything as Tier 3. The wisdom is knowing what’s actually Tier 1.
2. The Context Compression Principle
Before sending anything to a model, ask: what is the minimum sufficient context for this task?
A retrieval-augmented generation (RAG) pipeline that sends 5 relevant paragraphs instead of a full 200-page document doesn’t just save tokens — it often produces better outputs because the model isn’t distracted by irrelevant text. Research from Anthropic’s interpretability team and external audits of RAG systems consistently show that relevance-filtered context outperforms full-document context on precision metrics, even when the full document technically contains the answer.
Compression isn’t about being cheap. It’s about being precise.
3. The Caching Principle
If you’re sending the same system prompt — or the same product context, or the same rubric — on every API call, you’re leaving significant money on the table. Most major providers now offer prompt caching (Anthropic introduced it in mid-2024 at up to 90% cost reduction on cached input tokens). OpenAI followed with similar functionality shortly after.
The teams using this well aren’t just caching system prompts. They’re designing their entire context architecture around what can be pre-computed and reused. It’s the AI equivalent of CDN caching for web assets.
4. The Output Constraints Principle
Longer outputs cost more. Obvious, right? And yet most prompts implicitly encourage verbose responses.
The fix is surprisingly simple: be explicit. “Respond in under 100 words” or “Return only the JSON object, no explanation” are not rude instructions — they’re engineering constraints that dramatically reduce output token spend. An output that’s 40% shorter but equally correct is strictly better in any production context.
Case Studies: Who’s Getting This Right
Klarna went public with their AI implementation stats in early 2024 — their AI assistant handled 2.3 million conversations in its first month, doing work equivalent to 700 full-time customer service agents. The hidden story in their architecture: they use tiered model routing, with simple intent classification happening at low cost before routing complex cases to more capable models. The economics only work because they didn’t build a monolithic “use the best model everywhere” system.
Cursor, the AI-powered code editor that became the fastest-growing developer tool of 2024, has built their entire UX around context efficiency. Their “context window” UI makes the problem visible to users — you see what’s being sent to the model. That transparency was a product decision that also turned out to be an efficiency forcing function.
Notion AI quietly redesigned their pipeline in late 2023 after early cost projections didn’t match reality. They shifted from single-shot large model calls to a cascade architecture where simple operations (summarization of short text, tone adjustment) use smaller models, while complex operations (generating structured content from scratch) use frontier models. Engineering blog posts from their team indicate 40%+ cost reductions with no measurable drop in user satisfaction scores.
These aren’t unicorn exceptions. They’re examples of systematic thinking applied to a problem most teams treat as inevitable.
The Prompt Engineering Layer: Where Most Efficiency Gains Hide
Here’s a contrarian observation that most AI consultants won’t tell you: prompt engineering isn’t primarily about getting better outputs. It’s about getting sufficient outputs with less.
Consider few-shot prompting. Adding 2–3 examples of correct outputs to a prompt often eliminates the need for verbose instructions — which are token-heavy — and dramatically improves output consistency. You’re spending 150 tokens on examples to save 400 tokens of explanation. Net positive.
Or consider chain-of-thought prompting. Counterintuitively, asking a model to “think step by step” can reduce total tokens when it prevents multiple retry calls due to incorrect first attempts. One longer correct response beats three shorter wrong ones.
Or structured output formats. Asking for JSON instead of prose cuts output tokens by 30–60% for information extraction tasks, while making downstream processing more reliable. This is not just a style preference — it’s an efficiency multiplier.
The best prompt engineers think like compilers, not writers. They’re optimizing for a target behavior with minimum instruction overhead.
The Human Dimension: What Efficiency Really Costs
Let’s be honest about the tension here.
Aggressive token optimization can hurt the user experience if done carelessly. A support chatbot that’s constrained to 50-word responses saves money. It also alienates users who need nuanced help. The efficiency-first mindset, taken to its logical extreme, produces systems that are cheap and bad.
The actual skill is knowing where efficiency creates no tradeoff and where it does. Caching a system prompt saves money with zero user impact. Truncating the model’s reasoning about a complex medical or legal question to save output tokens is dangerous.
There’s also a developer experience tax. More sophisticated routing systems are more complex to build, debug, and maintain. A startup with three engineers probably shouldn’t build a five-tier model routing architecture — they should use a mid-tier model for everything and optimize later. Premature efficiency optimization is just as real as premature code optimization.
The industry hasn’t fully reckoned with this tension yet. There’s a growing body of blog posts celebrating token efficiency without adequately weighing the engineering complexity costs. The honest framework is: optimize efficiency where the cost-complexity tradeoff is clearly positive, and leave sophistication on the shelf until you have the data to justify it.
What the Next 18 Months Look Like
Several trends are converging that will reshape this entire conversation.
Model costs are falling fast. GPT-4-level capability cost roughly $0.06 per 1,000 tokens in early 2023. By mid-2024, similar capability was available at $0.005 per 1,000 tokens from various providers. The economic pressure driving aggressive optimization today will partially relax as frontier model costs approach commodity levels.
Context windows are getting enormous. Gemini 1.5 Pro launched with a 1 million token context window in 2024. The RAG-vs-long-context debate is very much alive. If models can reliably process millions of tokens cheaply, some of today’s efficiency architectures become unnecessary. If cost per token stays significant even at scale, they remain essential.
Speculative decoding and model compression are becoming mainstream. Techniques that allow large models to run faster and cheaper by using small models to “draft” outputs for large models to verify are moving from research into production. Companies like Together AI and Groq are building infrastructure around these ideas. This changes the efficiency calculus significantly.
The real frontier won’t be capability — it will be efficiency. The teams that understand how to extract maximum value per token will have structural advantages as AI becomes commoditized. This is the moat that doesn’t get discussed enough.
Key Takeaways
- Route by task, not by default. Map every AI use case to the minimum model required, not the most impressive one available.
- Compress before you query. Relevance-filtered context almost always outperforms full-document context in both cost and quality.
- Cache aggressively. System prompts, product context, and any fixed instruction set should be cached wherever your provider supports it.
- Constrain outputs explicitly. Don’t ask for what you don’t need. Format, length, and structure constraints are efficiency tools.
- Fine-tune for repetitive tasks. If you’re sending thousands of similar classification or extraction requests, a fine-tuned small model pays for itself quickly.
- Measure, then optimize. Build logging into your AI pipeline from day one. You cannot optimize what you cannot measure.
- Balance efficiency with experience. Not every token saved is worth saving. Know which optimizations are zero-tradeoff and which aren’t.
The Real Lesson
The Austin company that cut its AI bill by 68% didn’t do it by using less AI. They did it by using AI correctly.
That’s the insight worth sitting with.
Most of the conversation around AI efficiency is framed as a cost problem. But it’s really a clarity problem. When you understand what each model is actually good at — when you understand what a token represents, what context does, what compression preserves and what it loses — you stop treating AI like a vending machine and start treating it like an engineering system.
The companies winning at AI right now aren’t the ones with the biggest model budgets. They’re the ones with the best mental models.
Intelligence, it turns out, is most impressive when it knows what it doesn’t need to do.
That’s true of systems. And it’s probably true of the people building them.
Comments
Loading comments…