
A few years ago, while interning at an advertising firm in Lagos, Nigeria, I had the opportunity to work on a fascinating web application. During that period, Nigeria was gearing up for its National Sports Festival, and the Unity Torch Movement had just commenced. The Unity Torch, symbolizing the peace and unity of the nation, was set to traverse all states in Nigeria, aiming to raise awareness of the festival both within the country and globally.
As an advertising company, we aimed to contribute to this awareness by regularly updating people on the torch’s current location through our blog page. To achieve this, I, being a software novice at the time, resorted to manually updating the torch’s location at intervals, unaware of the concept of web scraping. It’s a moment of reflection for me now. If I had been aware of web scraping back then, I could have utilized an automated script to continually extract the latest torch location from the national news page and keep our company’s blog page updated.
In the spirit of sharing knowledge, today, I will guide you through the ins and outs of web scraping and even provide a bonus by creating a sample script.
What is web scraping?
Suppose you’re interested in the latest deals on eBay’s e-commerce website. Instead of manually checking each product listing, web scraping enables a computer program to visit those pages, extract the relevant information, and present it to you in a consolidated format. In essence, web scraping serves as a digital method for efficiently collecting specific data from the expansive realm of the internet without the need to individually visit each website.
What are the use cases of web scraping?
Web scraping has a wide range of applications across various industries. Here are some common use cases:
- Market Research: Businesses can use web scraping to gather data on market trends, competitor prices, and customer reviews. This helps in making informed business decisions.
- Price Comparison: Consumers and businesses can use web scraping to compare prices of products across different online retailers, ensuring they get the best deals.
- Job Market Analysis: Job seekers and recruiters can utilize web scraping to analyze job postings, skills in demand, and salary information to make more informed career decisions.
- Social Media Monitoring: Companies use web scraping to monitor social media platforms for mentions of their brand, products, or competitors. This helps in managing their online reputation.
- Financial Data Aggregation: Investors and financial analysts use web scraping to gather and analyze financial data, stock prices, and economic indicators to make investment decisions.
- Real Estate Market Analysis: Real estate professionals can use web scraping to collect data on property prices, rental rates, and market trends to guide their investment decisions.
- Healthcare Data Analysis: Researchers can use web scraping to collect data from medical journals, healthcare forums, and other sources for analysis and staying updated on the latest medical information.
What we will be building
Today, we will concentrate on extracting information from a reputable e-commerce platform, eBay. This platform hosts a wealth of data and maintains a satisfactory level of security. We will be utilizing powerful scraping tools such as Python and BeautifulSoup. To unlock the full potential of this process, our script will incorporate proxies to address significant challenges commonly encountered in web scraping, such as rate limits, throttling, and captchas.
Installing Necessary Packages
Confirm that Python is successfully installed by running this code below on your terminal
python3 — version which will display the current Python version that you just installed. You can download Python from here.
Setting up a virtual environment
To promote better organization, avoid conflicts between projects, and enhance the portability and reusability of your code across different environments it’s advisable to always create a virtual environment.
Step 1:
You can download VS Code from here.
Step 2:
Open the directory you want to work with on your VS Code and run the command below on your terminal.
python3 -m venv .venv
Step 3:
Confirm that the environment has changed when you see the .venv directory created on your root folder. VS Code will also indicate it as seen below:

Installation of BeautifulSoup and other essential packages
Run the command below to install the rest of the required package for our script:
pip install beautifulsoup4: It helps you parse the HTML content.pip install requests: It helps your Python code send requests to a websitepip install lxml: BeautifulSoup4 uses it under the hood for faster and more efficient parsing.
Building a Simple Web Scraper with BeautifulSoup
As previously mentioned, our objective is to perform web scraping on the eBay website. We aim to extract information on various products, including their names, prices, shipping costs, images, and titles.
Step 1:
Install the Python extension on your VSCode. This extension enhances productivity by providing features such as automatic linting and formatting, debugging, testing, and various other capabilities.
Step 2:
Create a main.py file on the root directory and add the code below:
from bs4 import BeautifulSoup
import requests
def find_apple_products():
html_text = requests.get(''https://orla.africa/'')
soup = BeautifulSoup(html_text.content, ''lxml'')
print(soup.title)
if __name__ == ''__main__'':
find_apple_products()
In this instance, our initial goal is to attempt web scraping on a website with lower security regarding cross-site scripting vulnerabilities.
Step 3:
Run the Python script by clicking the play button at the top right of your VSCode.
Confirm a response of 200 on your terminal just as seen below.
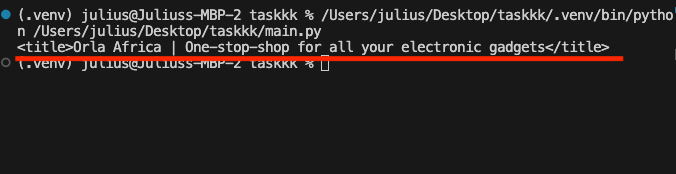
This output shows we have access to the page and we can perform more scraping work on this site. Now, let us replace the site URL with that of the eBay URL as seen in the next step.
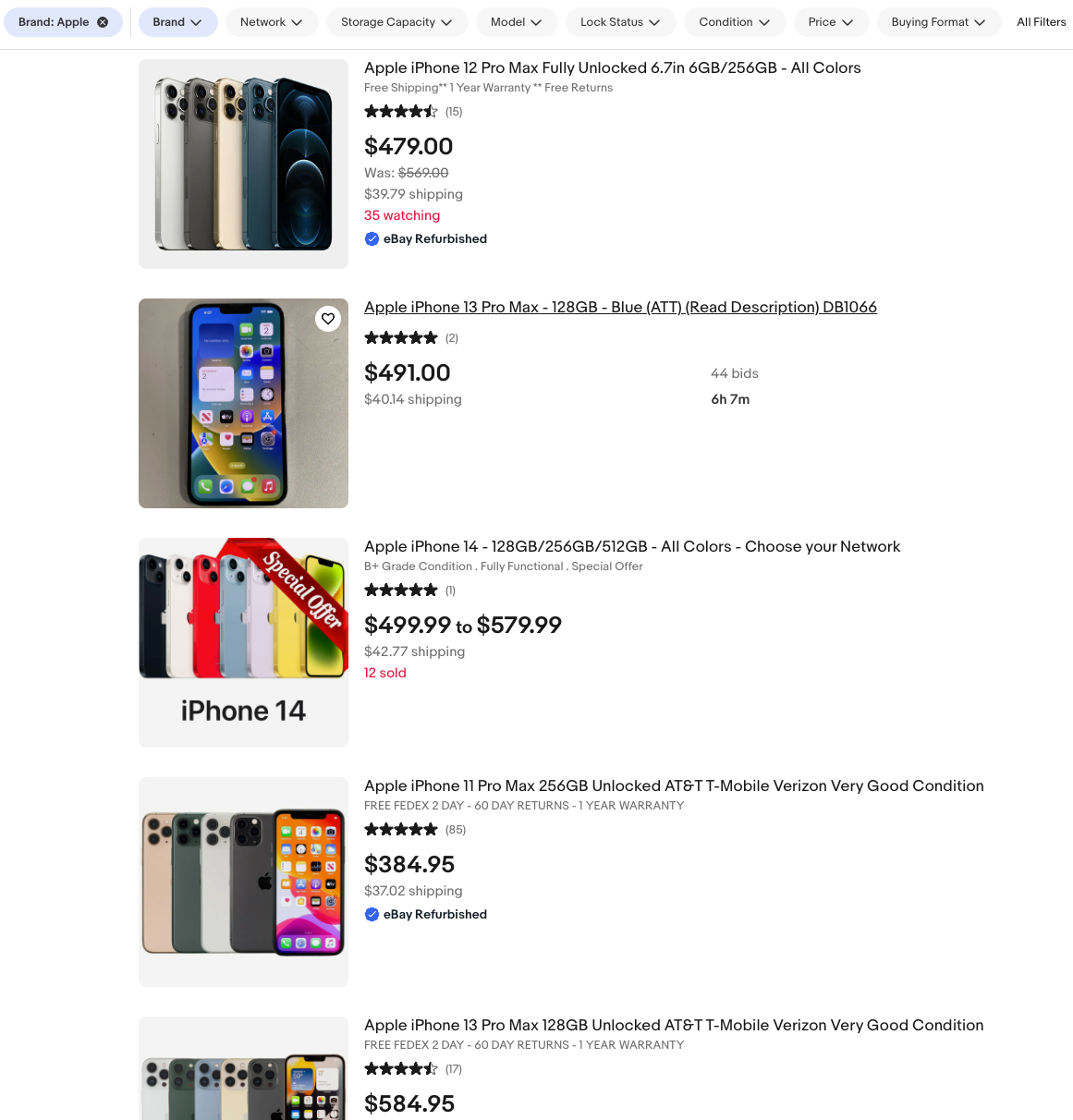
This is the URL that will undergo scraping: https://www.ebay.com/b/Apple-Cell-Phones-Smartphones/9355/bn_319682?mag=1
Here is a screenshot displaying the list of Apple phones whose data we will extract.
Step 4:
Update your code on main.py as seen below and run your script again.
from bs4 import BeautifulSoup
import requests
def find_apple_products():
html_text = requests.get(''https://www.ebay.com/b/Apple-Cell-Phones-Smartphones/9355/bn_319682?mag=1'')
soup = BeautifulSoup(html_text.content, ''lxml'')
print(soup)
if __name__ == ''__main__'':
find_apple_products()
After a prolonged wait, you may encounter the same error in your terminal.
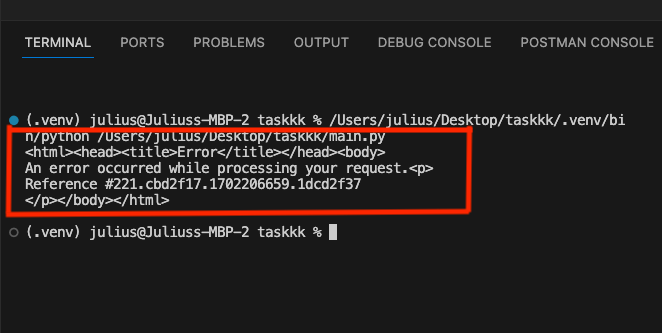
There could be various reasons for this output, leading us to explore some challenges one might encounter when scraping the internet. Let’s delve into a few of them.
Potential Issues in Web Scraping
Robots.txt Restrictions: Some websites specify rules in a file called “robots.txt” to control web crawlers’ access.
IP Blocking and Rate Limiting: Excessive requests from the same IP may lead to IP blocking or rate limiting.
Website Structure Changes: Websites frequently update their structure, breaking the scraping code.
Captcha Challenges: Some websites use captchas to prevent automated scraping.
Authentication Requirements: Accessing certain parts of a website may require authentication.
Handling Common Scraping Challenges
Now, it’s time to bring in the magician. Recall my earlier mention of proxies. They serve as a solution to overcome these challenges. While numerous proxy server providers exist, including free ones, for the purpose of this guide we’ll be using BrightData’s residential proxies.
We have strictly avoided using free proxies because they are often unreliable and we can never be sure if they follow proper protocols. Bright Data’s residential proxies, in contrast, are ethically sourced and adhere to major data protection regulations like the GDPR and CCPA. This makes Bright Data’s proxy network highly reliable and trustworthy — something that can not only make the data extraction process seamless with minimal interruptions but also ensure you don’t end up in any legal trouble.
Residential Proxies - 72M Residential IPs - Free Trial
Here are some of the benefits you can expect from Bright Data’s proxies.
Some benefits of Bright Data’s proxies compared to traditional free proxies:
- Reliability and Stability: Bright Data are more reliable and stable compared to free proxies. They offer dedicated, high-quality IP addresses that are less likely to be blocked or restricted.
- Performance: Bright Data provides better performance, offering faster speeds and lower latency. This is crucial for efficient and timely web scraping.
- Large Proxy Network: Bright Data has a vast proxy network with IPs in many locations worldwide. This allows users to access geographically restricted content and avoid IP blocking.
- Security and Privacy: Bright Data offers better security and privacy features, including encryption. This is essential when dealing with sensitive data or when you want to protect your online activities.
- Customer Support: Bright Data services typically offer dedicated customer support, helping users resolve issues and optimize their scraping efforts.
- Flexible Proxy Tools: Bright Data gives you a complete view of your proxy network’s logs and statistics, IP rotation and session management, and a real-time preview of the whole traffic. The proxy manager also gives you total control over who can access your proxy network, which countries to target, and more.
- Extension: Bright Data’s proxies from your browser with minimum setup. The browser extension supports both residential and data center IP browsing, allowing you to search and gain access to public websites from any country.
👉 Learn more about Bright Data’s Proxies and Scraping Infra.
Configuring Bright Data Proxies
Step 1:
The first step is to sign up to access the Bright Data control panel. If you haven’t yet signed up for Bright Data, you can sign up for free, and when adding your payment method, you’ll receive a $5 credit to get you started!
Step 2:
Create your new Residential Proxies. Navigate to ‘My Proxies’ page, and under ‘Residential Proxies’ click ‘Get started’
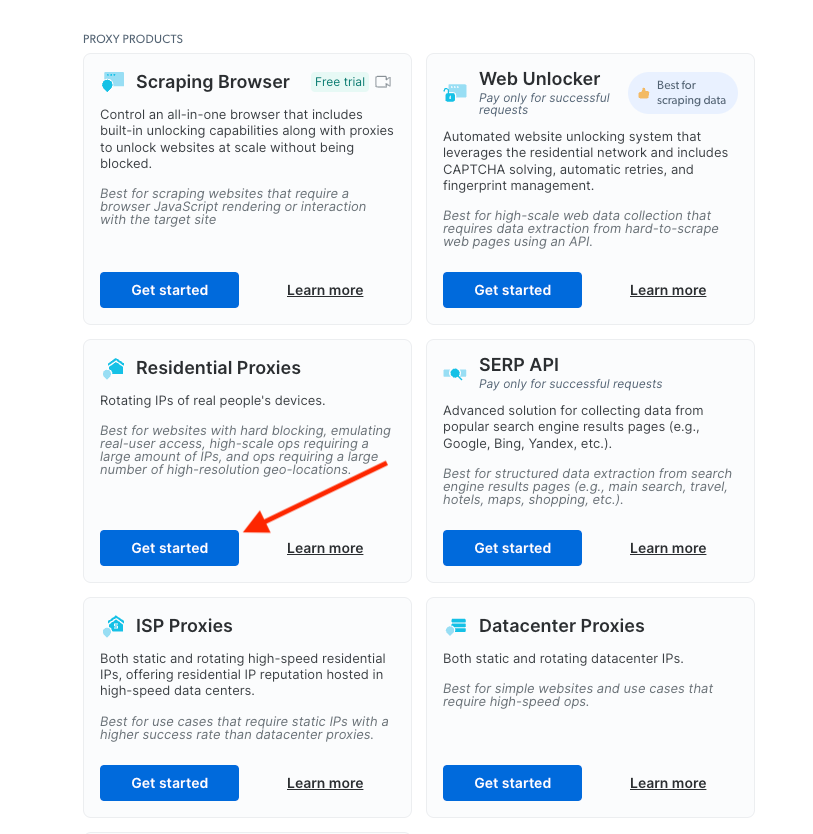
If you already have an active proxy, simply choose ‘Add proxy’ at the top right
Step 3:
In the “Create a new proxy” page, choose and input a name for your new Residential Proxies. Choose the IP type and the Geolocation you are targeting.
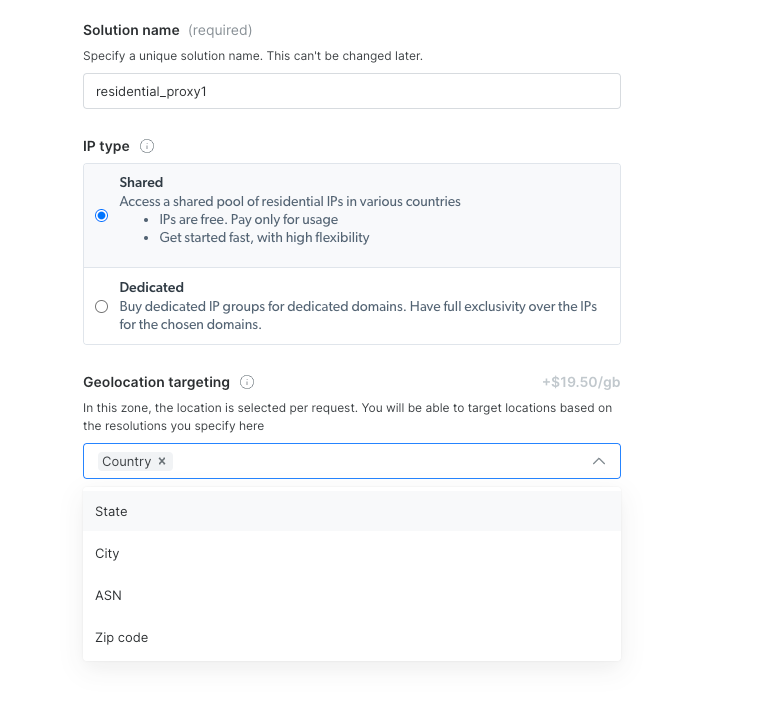
Step 4:
To create and save your proxy, click ‘Add proxy’
A note on Account verification:
If you haven’t yet added a payment method, you’ll be prompted to add one at this point in order to verify your account.
Be advised: You will not be charged anything at this point and this is solely for verification purposes.
Step 5:
Obtaining your API credentials
After verifying your account above, you can now view your API credentials.
In your proxy zone’s ‘Access parameters’ tab, you’ll find your API credentials which include your Host, Username, and Password.
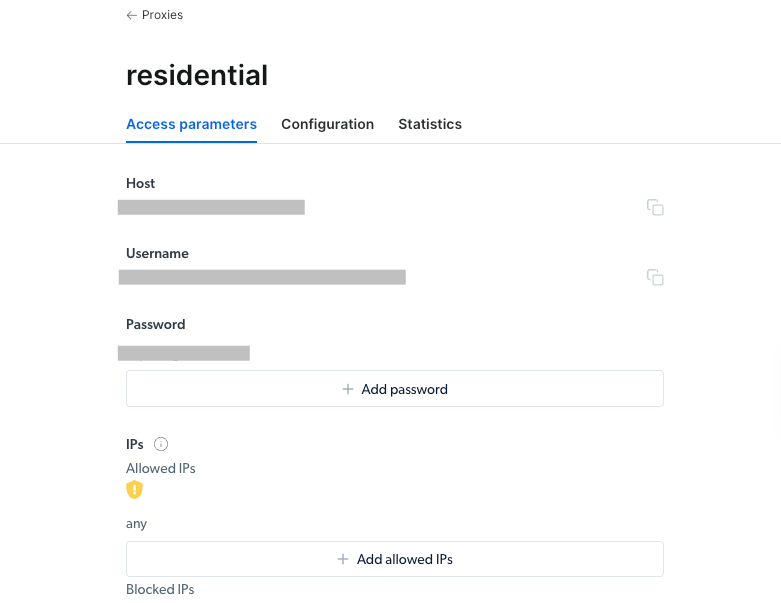
Step 6:
Add the solution and view your default host, username, and password. Keep them very private.
Integrating BrightData to Our Script
Step 1:
Back to VS Code, create a .env file on the root folder, and add the default credentials from Bright Data as seen below:
export BRIGHTDATA_RESIDENTIAL_HOST=<replace with Brighdata host:port>
export BRIGHTDATA_RESIDENTIAL_USERNAME=<replace with Brighdata username>
export BRIGHTDATA_RESIDENTIAL_PASSWORD=<replace with Brighdata password>
Step 2:
Read the environment variables from an environment file by using a library like python-dotenv
You can install it by running: pip install python-dotenv
Step 3:
Update the main.py file as shown below to integrate BrightData proxies.
from bs4 import BeautifulSoup
import requests
import os
from dotenv import load_dotenv
load_dotenv()
# Fetching residential proxy details from environment variables
residential_host = os.getenv("BRIGHTDATA_RESIDENTIAL_HOST")
residential_username = os.getenv("BRIGHTDATA_RESIDENTIAL_USERNAME")
residential_password = os.getenv("BRIGHTDATA_RESIDENTIAL_PASSWORD")
# Creating the proxy URL using the fetched details
proxy_url = f"http://{residential_username}:{residential_password}@{residential_host}/"
# Target eBay URL for Apple products
eBay_url = ''https://www.ebay.com/b/Apple-Cell-Phones-Smartphones/9355/bn_319682?mag=1''
# Setting custom User-Agent in the headers to mimic a specific user agent
headers = requests.utils.default_headers()
headers.update(
{
''User-Agent'': ''My User Agent 1.0'',
}
)
# Function to scrape Apple products from eBay
def find_apple_products():
# Sending a GET request to eBay with the specified proxy and headers
html_text = requests.get(eBay_url,proxies={"http": proxy_url}, headers=headers)
# Parsing the HTML content using BeautifulSoup
soup = BeautifulSoup(html_text.content, ''lxml'')
# Finding all Apple phones on the eBay page
apple_phones = soup.find_all(''div'', class_=''s-item__wrapper clearfix'')
# Iterating through each Apple phone and extracting relevant information
for phone in apple_phones:
phone_image = phone.find(''img'', class_=''s-item__image-img'')[''src'']
phone_title = phone.find(''div'', class_=''s-item__info'').h3.text
phone_price = phone.find(''div'', class_=''s-item__detail s-item__detail - primary'').span.text
shiping_cost = phone.find(''span'', class_=''s-item__shipping s-item__logisticsCost'').text
# Printing the extracted information for each phone
print(f"title: {phone_title}")
print(f"image_url: {phone_image}")
print(f"price: {phone_price}")
print(f"shipping: {shiping_cost.split()[0]}")
print('')
# Entry point of the script
if __name__ == ''__main__'':
# Calling the function to find and print Apple products on eBay
find_apple_products()
👉 Learn more about Bright Data’s residential proxies in the official documentation.
Step 4:
Confirm the output on your terminal as seen below:
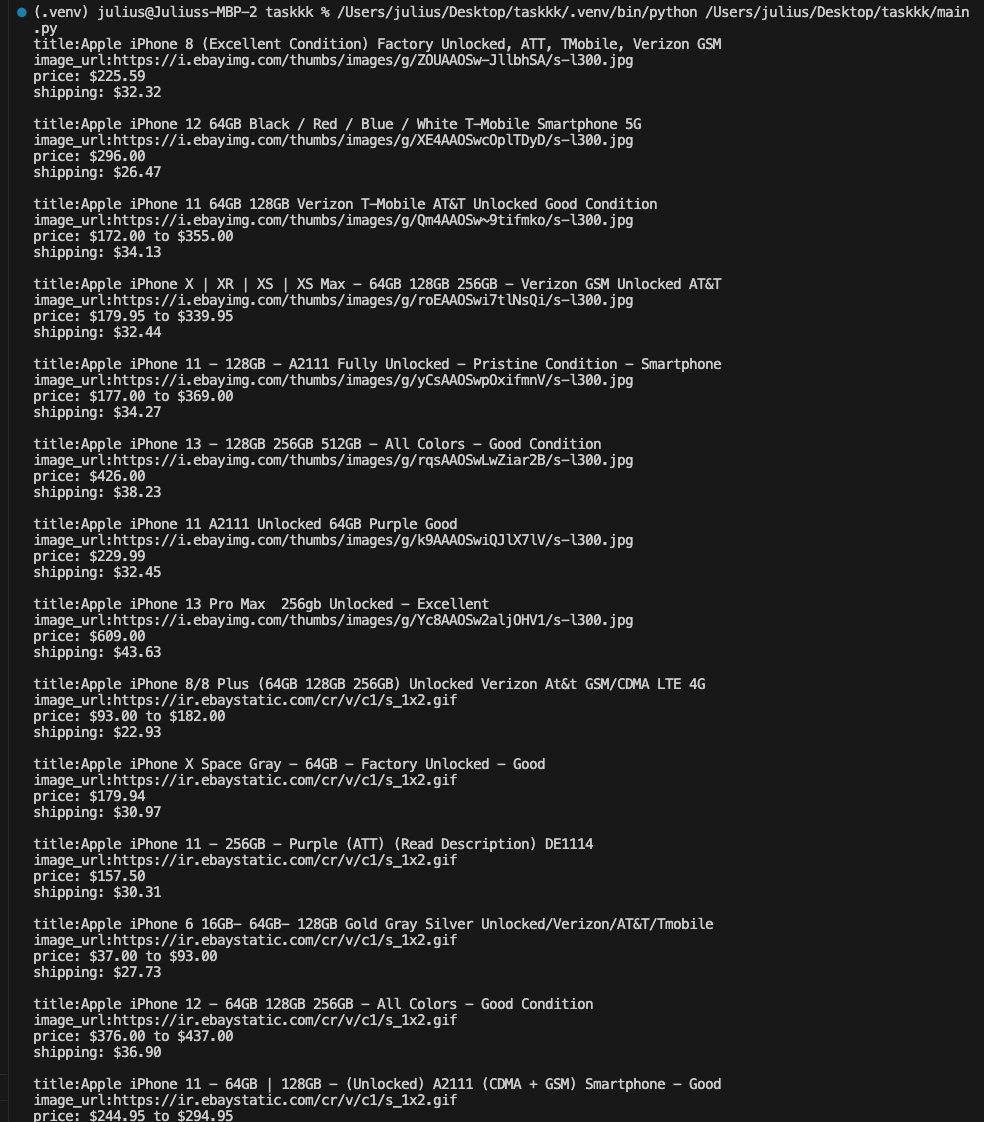
As evident, the proxy has effectively addressed the challenges we previously outlined. We’ve successfully scraped the eBay website, overcoming obstacles such as location restrictions, robot securities, captchas, rate limiters, and various other vulnerability measures. This highlights the prowess of proxies, showcasing how Bright Data enables you to surpass limitations and excel in web scraping.
Conclusion
We’ve successfully utilized BeautifulSoup to navigate the intricate code of the web page, extracting specific information of interest. Additionally, we overcame common web scraping challenges such as captchas, robots.txt restrictions, and IP bans by making effective use of proxies.
We have also seen how Bright Data provides a reliable and ethically compliant proxy network for your project, spread over 195+ countries, covering almost every city in the world. They offer diverse options for obtaining the required data, including various types of proxies and specialized tools tailored to meet your specific web scraping needs.
Whether your objective is to compile market research data, monitor online reviews or track competitor pricing, Bright Data offers the essential resources to accomplish your tasks swiftly and efficiently.
Currently, Bright Data is offering a 40% discount on all proxies, so you can take the free trial to try it out for yourself.
Comments
Loading comments…