Masking helps you filter or handle unwanted, missing, or invalid data in your data science projects or, in general, Python programming.

NumPy mask
Masked arrays are arrays that may have missing or invalid entries. The numpy.ma module provides a nearly work-alike replacement for NumPy that supports data arrays with masks.
1-d Arrays
Suppose we have the following NumPy array:
import numpy as np
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
If we want to compute the sum of elements smaller < 4 and > 6.
total = 0 # Variable to store the sum
for num in arr:
if (num<4) or (num>6):
total += num
print(total)
>>> 21
One line list:
total = sum([num for num in arr if (num<4) or (num>6)])
>>> 21
The same task can be achieved using the concept of Masking. It essentially works with a list of Booleans (True/False), which when applied to the original array returns the elements of interest. Here, True refers to the elements that satisfy the condition (smaller than 4 and larger than 6 in our case), and False refers to the elements that do not satisfy the condition.
mask = [True, True, True, False, False, False, True, True]
Next, we apply this mask (list of Booleans) to our array using indexing. This will return only the elements that satisfy this condition.
arr[mask]
>>> array([1, 2, 3, 7, 8])
arr[mask].sum()
>>> 21
💡 Speed up your blog creation with DifferAI.
Available for free exclusively on the free and open blogging platform, Differ.
Numpy’s MaskedArray Module
Caution: when the mask=False or mask=0, it literally means label this value as valid. Simply put, include it during the computation. Similarly, mask=True or mask=1 means label this value as invalid.
By contrast, earlier you saw that False value was excluded when we used indexing.
mask = [False, False, False, True, True, True, False, False]
import numpy.ma as ma
"""First create a normal Numpy array"""
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
ma_arr = ma.masked_array(arr, mask=[False, False, False, True,
True, True, False, False])
>>> masked_array(data=[1, 2, 3, --, --, --, 7, 8],
mask=[False, False, False, True, True, True, False,
False], fill_value=999999)
ma_arr.sum()
>>> 21
The masked (invalid) values are now represented by --.
The shape/size of the resulting masked_array is the same as the original array.
Previously, when we used arr[mask], the resulting array was not of the same length as the original array because the invalid elements were not in the output. This feature allows easy arithmetic operations on arrays of equal length but with different maskings.
Like before, you can also create the mask using list comprehension. However, because you want to swap the True and False values, you can use the tilde operator **~** to reverse the Booleans.
"""Using Tilde operator to reverse the Boolean"""
ma_arr = ma.masked_array(arr, mask=[~((a<4) or (a>6)) for a in arr])
ma_arr.sum()
>>> 21
You can also use a mask consisting of 0 and 1.
ma_arr = ma.masked_array(arr, mask=[0, 0, 0, 1, 1, 1, 0, 0])
NumPy offers several other in-built masks that avoid your manual task of specifying the Boolean mask.
- less than (or less than equal to) a number
- greater than (or greater than equal to) a number
- within a given range
- outside a given range
Less than (or less than equal to) a number
The function masked_less() will mask/filter the values less than a number.
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
ma_arr = ma.masked_less(arr, 4)
>>> masked_array(data=[--, --, --, 4, 5, 6, 7, 8],
mask=[True, True, True, False, False, False,
False, False], fill_value=999999)ma_arr.sum()
>>> 30
To filter the values less than or equal to a number,masked_less_equal().
Greater than (or greater than equal to) a number
We use the function masked_greater() to filter the values greater than 4.
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
ma_arr = ma.masked_greater(arr, 4)
>>> masked_array(data=[1, 2, 3, 4, --, --, --, --],
mask=[False, False, False, False, True, True,
True, True], fill_value=999999)ma_arr.sum()
>>> 10
Likewise, masked_greater_equal()filters value greater than or equal to 4.
Within a given range
The function masked_inside() will mask/filter the values lying between two given numbers (both inclusive). The following filter values are between 4 and 6.
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
ma_arr = ma.masked_inside(arr, 4, 6)
>>> masked_array(data=[1, 2, 3, --, --, --, 7, 8],
mask=[False, False, False, True, True, True,
False, False], fill_value=999999)ma_arr.sum()
>>> 21
Outside a given range
The function masked_inside() will mask/filter the values lying between two given numbers (both inclusive). The following filter values outside 4-6.
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
ma_arr = ma.masked_outside(arr, 4, 6)
>>> masked_array(data=[--, --, --, 4, 5, 6, --, --],
mask=[True, True, True, False, False, False,
True, True], fill_value=999999)ma_arr.sum()
>>> 15
Neglecting NaN and/or infinite values during arithmetic operations
This is a cool feature! Often a realistic dataset has lots of missing values (NaNs) or some weird, infinity values. Such values create problems in computations and, therefore, are either neglected or imputed.
For example, the sum or the mean of this 1-d NumPy array will benan.
arr = np.array([1, 2, 3, np.nan, 5, 6, np.inf, 8])
arr.sum()
>>> nan
You can easily exclude the NaN and infinite values using masked_invalid() that will exclude these values from the computations. These invalid values will now be represented as --. This feature is extremely useful in dealing with missing data in large datasets in data science problems.
ma_arr = ma.masked_invalid(arr)
>>> masked_array(data=[1.0, 2.0, 3.0, --, 5.0, 6.0, --, 8.0],
mask=[False, False, False, True, False, False,
True, False], fill_value=1e+20)ma_arr.mean()
>>> 4.166666666666667
Let’s say you want to impute or fill these NaNs or inf values with the mean of the remaining, valid values. You can do this easily using filled() as:
ma_arr.filled(ma_arr.mean())
>>> [1., 2., 3., 4.16666667, 5., 6., 4.16666667, 8.]
Masking 2-d arrays (matrices)
Often your big data is in the form of a large 2-d matrix. Let’s see how you can use masking for matrices. Consider the following 3 x 3 matrix.
arr = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
Suppose we want to compute the column-wise sum excluding the numbers that are larger than 4. Now, we have to use a 2-d mask. As mentioned earlier, you can also use a 2-d mask of True/False in the following.
ma_arr = ma.masked_array(arr, mask=[[0, 0, 0],
[0, 1, 1],
[1, 1, 1]])>>> masked_array(data=[[1, 2, 3],
[4, --, --],
[--, --, --]],
mask=[[False, False, False],
[False, True, True],
[True, True, True]], fill_value=999999)"""Column-wise sum is computed using the argument axis=0"""
ma_arr.sum(axis=0)>>> masked_array(data=[5, 2, 3], mask=[False, False, False],
fill_value=999999)
In the above code, we created a 2-d mask manually using 0 and 1. You can make your life easier by using the same functions as earlier for a 1-d case. Here, you can use masked_greater() to exclude the values greater than 4.
ma_arr = ma.masked_greater(arr, 4)ma_arr.sum(axis=0)
>>> masked_array(data=[5, 2, 3], mask=[False, False, False],
fill_value=999999)
NOTE: You can use all the functions, earlier shown for 1-d, and also for 2-d arrays.
Use of masking in a data science problem
A routine task of any data science project is exploratory data analysis (EDA). One key step in this direction is to visualize the statistical relationship (correlation) between the input features. For example, Pearson’s correlation coefficient provides a measure of linear correlation between two variables.
Let’s consider the Boston Housing Dataset and compute the correlation matrix which results in coefficients ranging between -1 and 1.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_bostonboston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
Let’s now plot the correlation matrix using the Seaborn library.
correlation = df.corr()ax = sns.heatmap(data=correlation, cmap='coolwarm',
linewidths=2, cbar=True)
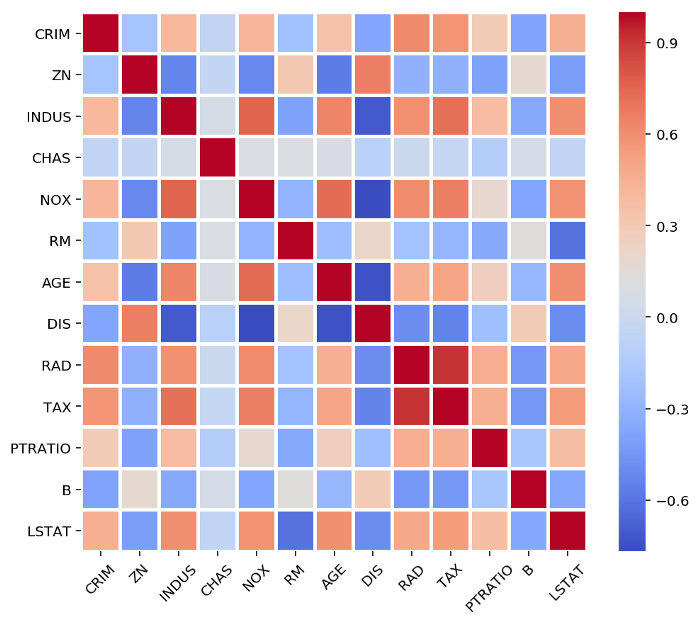 A correlation matrix
A correlation matrix
Now, suppose you want to highlight or easily distinguish the values which are having an absolute correlation of over 70%, i.e. 0.7. The above-introduced concepts of Masking come into play here. You can use the masked_outside() function, explained earlier, to mask your required values and highlight them using a special color in your Seaborn plot.
correlation = df.corr()"""Create a mask for abs(corr) > 0.7"""
corr_masked = ma.masked_outside(np.array(correlation), -0.7, 0.7)"""Set gold color for the masked/bad values"""
cmap = plt.get_cmap('coolwarm')
cmap.set_bad('gold')ax = sns.heatmap(data=correlation, cmap=cmap,
mask=corr_masked.mask,
linewidths=2, cbar=True)
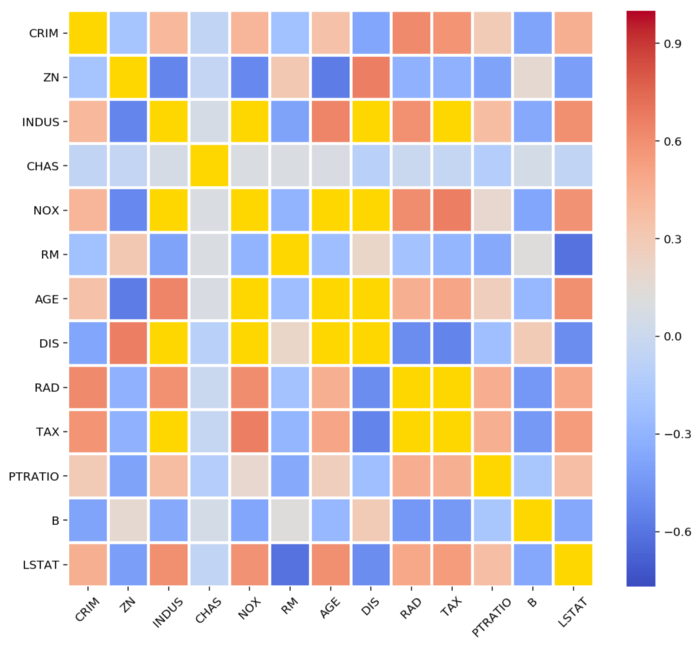 A correlation matrix
A correlation matrix
Thanks for reading.
Comments
Loading comments…