
Why do I need a bank statement parser?
Managing multiple bank accounts can be a hassle, especially when each bank provides statements in different formats.
If you’re tired of manually sifting through these statements every month, a bank statement parser could be what you need, saving you time and effort.
Enter the “bank statement parser” — a software that extracts and organizes unstructured text data from statements. It can identify transaction details, dates, and amounts, and convert them into a standard/structured format for better readability.
If you’re lucky, your bank provides a way to download your statement as a CSV file. If you’re incredibly lucky, your bank might even support Open Banking with some kind of API (but if you’re like me, you’re probably not that lucky).
So instead of copy-pasting from a PDF every month, why not create your own bank statement parser instead? In this post, I’ll go through how to use Python to convert your PDF to text, extract the transactions, and ultimately create a parser you can use across different bank statements.
Converting your PDF to text
The first and most obvious route is to use an open-source Python package, similar to the likes of PyPDF, PyMuPDF, pdftotext, or pdfminer. I’m not going to get into the nitty-gritty details of how they differ — there’s a great article that already covers that.
To briefly summarize the article, pdftotext is a really good option since it faithfully represents the layout of each page. This means that your transactions will remain on the same line, and won’t be broken up.
Caveat: You can also use an optical character recognition (OCR) library like PyTesseract or OpenOCR, but this is only necessary if your PDF doesn’t come with embedded text (i.e. it isn’t searchable). There’s a relatively high-performance overhead that comes with higher levels of accuracy. Otherwise, training your own model could also be a feasible approach if you have enough time and compute.
For example — let’s say you have this bank statement:
Sample bank statement from the author:

If you use pdftotext and print the results:
pdftotext -layout .../example_statement.pdf out.txt cat out.txt
You’ll get back something like this, with transactions neatly separated per line.
Raw output from pdftext:
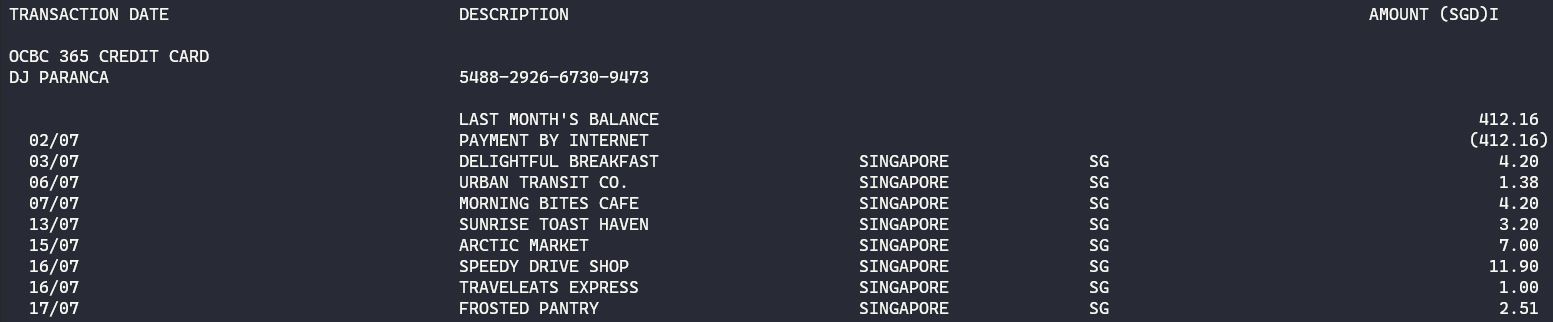
If you open this file with Python, you’ll see that lines are neatly demarcated by newline \n characters, which means you can easily split the text and process it line by line, which is really useful for parsing.
So, how do we do this with Python?
There’s a nice Python wrapper of Poppler’s pdftotext that you can use for this:
import pdftotext
with open(".../example_statement.pdf", "rb") as file:
pdf = pdftotext.PDF(file, physical=True)\
first_page = pdf[0]
lines = first_page.split("\n")
for line in lines:
print(line.lstrip())
We’re using the physical argument to make sure that the original physical layout of the text is maintained, so that transactions are not split up by column or page.
You can then iterate over the PDF while stripping away any redundant whitespaces.
Extracting Transactions from Text
So at this point, hopefully, you have your transactions ready for extraction.
Let’s say our first page looks something like this:
example_first_page = [
"random text, foo bar baz ",
"01-07-2023 statement date random date 23-07-2023",
"06/07 URBAN TRANSIT CO. SINGAPORE SG 1.38",
"07/07 MORNING BITES CAFE SINGAPORE SG 4.20",
"13/07 SUNRISE TOAST HAVEN SINGAPORE SG 3.20",
];
Annoyingly, there seems to be a bunch of redundant text and dates that we don’t want. Since transactions may not always appear on the same line and may start at different positions on each page, it isn’t possible to simply filter them out with something like transactions = example_first_page[2:]
To get the transactions, we can instead use regular expressions i.e. regex.
import re
transactions = []
transaction_pattern = (
r"(?P<transaction_date>\d+/\d+)\s*"
r"(?P<description>.*?)\s*"
r"(?P<amount>[\d.,]+)$"
)
for line in example_first_page:
match = re.search(pattern=transaction_pattern, string=line)
if match:
transactions.append(match.groupdict())
Here’s a brief explanation of the transaction pattern if you’re not familiar with regex:
1. (?P<transaction_date>\d/\d+): Captures the transaction date in the format dd/dd e.g. 06/07
2. \s*: Matches zero or more whitespace characters.
3. (?P<description>.*?): Captures the transaction description.
4. \s*: Matches zero or more whitespace characters.
5. (?P<amount>[\d.,]+$: Captures the transaction amount, allowing digits, commas, and periods, ensuring it’s at the end of the line.
This becomes a lot easier to see and understand with regex101:

The rest of the code is relatively simple — if the pattern matches the string, print the combined text as output, and append a dictionary representation of the match to a list.
The dictionary should look something like this:
{
'transaction_date': '13/07',
'description': 'SUNRISE TOAST HAVEN SINGAPORE SG',
'amount': '3.20'
}
You’ve now effectively created a list of dictionary objects, which can be used by something like Pandas.
import pandas as pd
df = pd.DataFrame(transactions)
>>> | transaction_date | description | amount |
|-------------------|----------------------------------|--------|
| 06/07 | URBAN TRANSIT CO. SINGAPORE SG | 1.38 |
| 07/07 | MORNING BITES CAFE SINGAPORE SG | 4.20 |
| 13/07 | SUNRISE TOAST HAVEN SINGAPORE SG | 3.20 |
Since regex doesn’t handle type coercion, the date and amount columns need to be manually converted to their appropriate types.
df["transaction_date"] = pd.to_datetime(
df["transaction_date"],
(format = "%d/%m")
);
df["amount"] = df["amount"].astype(float);
df.to_csv("processed_statement.csv");
Once this is done, you can save your processed statement as a CSV file, or combine multiple DataFrames together for a more comprehensive view of your spending.
But wait, why are the dates wrong?
At this point, if you’ve taken a closer look at your DataFrame, you’ll notice that the transaction dates are inaccurate. This is an obvious no-go for data cleanliness and accuracy.
The reason for this is because of the short-form date (e.g. 06/07). Pandas doesn’t have any information about what year it is, and so the date defaults to 1900–07–06.
To fix this, you’ll need to figure out the statement date. If you take a look at the example data, you’ll see something that suspiciously looks like a statement date.
...
"01-07-2023 statement date random date 23-07-2023",
...
Using regex once again:
statement_date_pattern = r"\d{2}\-\d{2}\-\d{4}"
statement_date = None
for line in example_first_page:
if not statement_date:
match = re.findall(pattern=statement_date_pattern, string=line)
if match:
statement_date = match[0]
print(statement_date)
You can then convert the dates with a lambda function, and some neat f-string manipulation
from datetime import datetime
def convert_date(row, statement_date: str):
statement_date = datetime.strptime(statement_date, "%d-%m-%Y")
row_year = statement_date.year
row_date = datetime.strptime(row["transaction_date"], "%d/%m")
row_day, row_month = row_date.day, row_date.month
return f"{statement_date.year}-{row_month:02d}-{row_day:02d}"
df["transaction_date"] = df.apply(convert_date, statement_date=statement_date, axis=1)
To avoid cross-year datetime issues, you’ll also need the following condition within the function:
if statement_date.month == 1 and row_month == 12:
row_year = statement_date.year - 1
else:
row_year = statement_date.year
And that’s it — you should now have a simple script you can use to process your bank statements each month.
Creating a parser
A script is great, but a single script isn't ideal if you have multiple cards/statements.
Instead, why not create something with a bit more reusability and modularity? If you think about it, you’ll notice a lot is going on — you’re reading the statement, parsing it, and transforming it.
To make things easier, you can take an object-oriented approach, which means treating each component as a unique class, with different properties and methods.
Let’s start simple, with a neat way to store all your configuration data.
from dataclasses import dataclass
@dataclass
class BankConfig:
bank_name: str
statement_date_pattern: str
statement_date_format: str
transaction_pattern: str
transaction_date_format: str
You can then pass in the same regex/date patterns from earlier:
example_bank_config = BankConfig(
bank_name="example-bank",
statement_date_pattern=r"\d{2}-\d{2}-\d{4}",
statement_date_format=r"%d-%m-%Y",
transaction_pattern=(
r"(?P<transaction_date>\d+/\d+)\s*"
r"(?P<description>.*?)\s*"
r"(?P<amount>[\d.,]+)$"
),
transaction_date_format=r"%d/%m",
)
Next, you’ll need to create the parser i.e. the part of your code that reads the PDF and extracts transactions.
from datetime import datetime
from functools import cached_property
class PdfParser:
"""Parses a bank statement PDF and extracts transactions and the
statement date
"""
def __init__(self, file_path: str, bank_config: BankConfig):
self.file_path = file_path
self.bank_config = bank_config
@cached_property
def pdf(self) -> list[str]:
with open(self.file_path, "rb") as f:
pdf = pdftotext.PDF(f, physical=True)
return pdf
@cached_property
def transactions(self) -> list[dict]:
transactions = []
for page in self.pdf:
for line in page.split("\n"):
pattern = self.bank_config.transaction_pattern
if match := re.search(pattern, line):
transactions.append(match.groupdict())
return transactions
@cached_property
def statement_date(self) -> datetime:
first_page = self.pdf[0]
for line in first_page.split("\n"):
date_format = self.bank_config.statement_date_format
pattern = self.bank_config.statement_date_pattern
if match := re.search(pattern, line):
statement_date = datetime.strptime(
match.group(),
date_format
)
return statement_date
This is the same code from before, albeit with some slight adjustments. We’re accepting the BankConfig class as an argument along with a file path, and defining several properties to store statement-specific information like the statement date.
Cached properties are also now being used instead of functions (or regular properties), since they provide lazy evaluation, and will help us avoid performance issues if they are called more than once. They also provide a consistent interface, which will come in handy when we begin to transform our data.
Extracting transactions to a DataFrame
With the “parser” completed, it’s now time to create the statement “processor” which is responsible for cleaning and transforming the transactions.
One way to do this is by treating the “processor” as a child class, and the “parser” as a parent class.
To do this, we’ll tap on Python inheritance by calling the super() method, which grants the “processor” class access to the properties and methods in the “parser” class.
Here’s what that might look like:
import pandas as pd
class StatementProcessor(PdfParser):
def __init__(self, file_path: str, bank_config: BankConfig):
self.file_path = file_path
self.bank_config = bank_config
super().__init__(file_path, bank_config)
def extract(self) -> pd.DataFrame:
"""Extracts transactions from a PDF, and represents
them in a Pandas DataFrame
"""
return pd.DataFrame(self.transactions)
def transform(self, df: pd.DataFrame) -> pd.DataFrame:
"""
Transforms the column types of a Pandas DataFrame
"""
date_format = self.bank_config.transaction_date_format
df["transaction_date"] = df.apply(
self._convert_date,
statement_date=self.statement_date,
transaction_date_format=date_format,
axis=1
)
df["transaction_date"] = pd.to_datetime(df["transaction_date"])
df["amount"] = df["amount"].astype(float)
return df
@staticmethod
def _convert_date(row, statement_date: datetime, transaction_date_format: str) -> str:
row_year = statement_date.year
if statement_date.month == 1 and row_month == 12:
row_year = statement_date.year - 1
row_date = datetime.strptime(row["transaction_date"], transaction_date_format)
row_day, row_month = row_date.day, row_date.month
return f"{row_year}-{row_month:02d}-{row_day:02d}"
def load(self, df: pd.DataFrame):
"""
Writes the input DataFrame to a CSV file
"""
df.to_csv(
f"{self.bank_config.bank_name}-"
f"{self.statement_date.month:02d}.csv",
index=False
)
This class takes the same arguments as the parser, and passes these arguments to the constructor of the parser itself. Besides that, this class contains the extract, transform and load (ETL) logic for the bank statement.
You can try tweaking the configuration and running the processor on your own statement, or you can use this sample statement.
pdf_file_path = ".../example_statement.pdf";
processor = StatementProcessor(pdf_file_path, example_bank_config);
df = processor.extract();
transformed_df = processor.transform(df);
processor.load(transformed_df);
Putting it all together:
To test this out, you can save this script, and run it with python3 statement_parser.py (if you’re using your statement, you’ll need to update the pdf_file_path and various regex/date patterns).
There’s a lot further you can go with in terms of abstracting the code and config, or making it more performant, though unless you’re parsing thousands of PDFs you probably won’t need to worry about speed.
To make this truly interchangeable between banks will also take a bit more work, since you’ll need to deal with different transaction formats, and types of debit/credit syntax (e.g. cashback and refunds).
If you’re wondering what a more fleshed-out version of this looks like, you can visit my repository, which implements the parser as a command-line tool called Monopoly.
Taking to the Cloud
If having a local parser isn’t enough, you can also try to implement it in the cloud. In an ideal world, as soon as your statement hits your email, you can process it and send yourself the raw transactions.
This enters a bit into the realm of data engineering, where you need to set up a type of “data pipeline”. This might entail setting up auto-forwarding rules from your primary email address to a service email account, or by getting your bank to send the statements to your address.
Here’s an example of what that might look like:
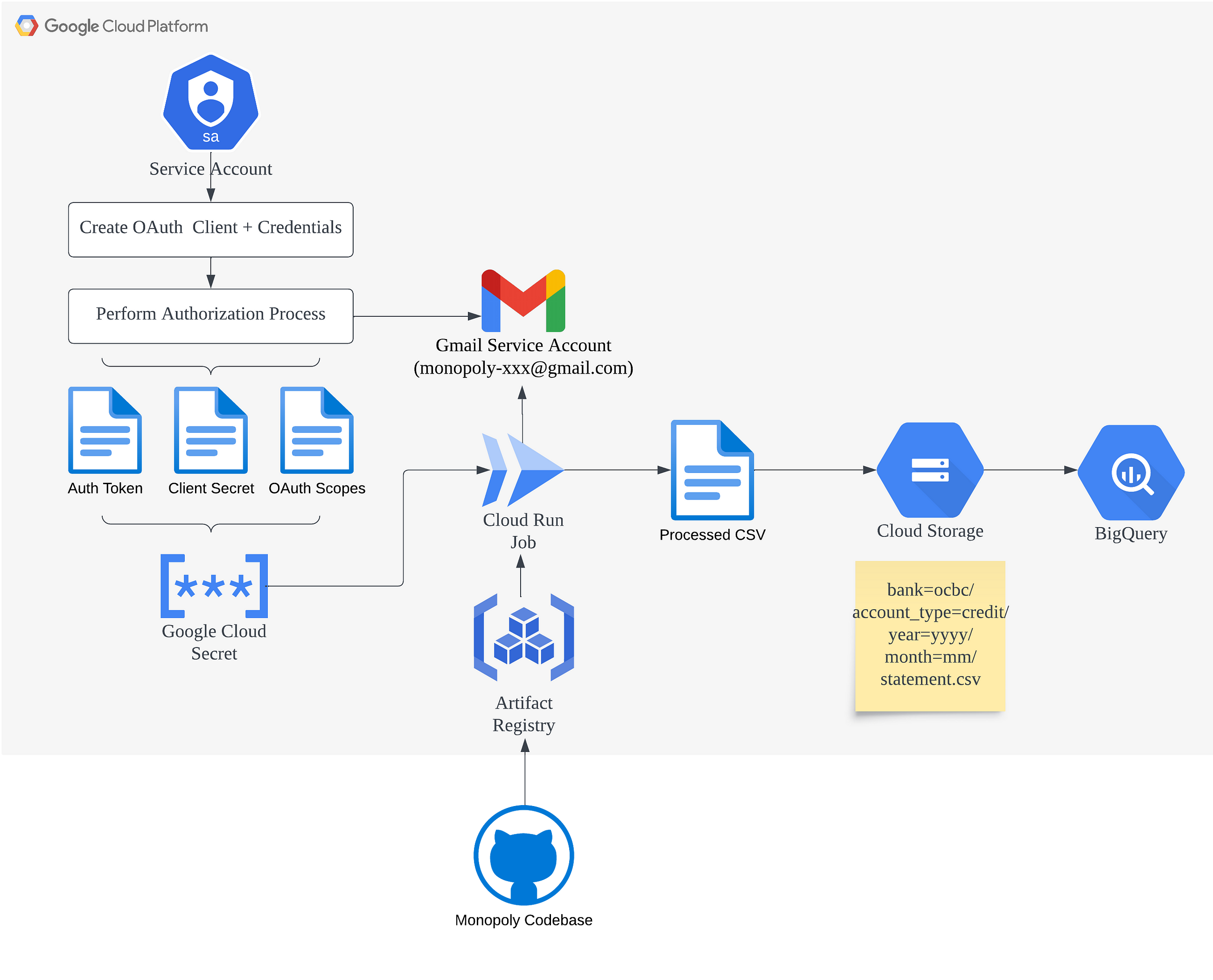
This is pretty tough, since you’ll need to set up the infrastructure and containerized version of the parser. Terraform + Docker works pretty well for this.
You’ll also need to work with the Gmail API, and handle permissions/secrets for any PDFs that might be password encrypted.
As a starting point, you can use this repository, which runs a containerized version of Monopoly as a Google Cloud Run job on a daily schedule.
That’s it for this article! I hope it was helpful for you. If you have any feedback or questions, feel free to hit me up on LinkedIn.
Comments
Loading comments…