One of the most common ways to format data is as a CSV file. It is a convenient form of storage because spreadsheet applications such as Excel and Google Sheets can easily display CSV-format data in the form of a table. In this article, I will talk about how to format data as a CSV in Python without using Pandas. There are two primary reasons for this:
- Python programmers who are unfamiliar with Pandas may still need to work with Pandas.
- Understanding how to manually format CSV files provides an important insight into how your data is actually formatted below the surface. This deeper understanding can be helpful for a programmer who needs to manipulate and process this data.
I will split the remainder of the article into two parts: 1) the structure of CSV files and 2) defining this structure in Python.
How does a CSV file actually look under the hood?
Before trying to build our own CSV file in Python, we need to understand what a CSV actually looks like. The acronym CSV stands for comma-separated values. In other words, if you think of a data table as a CSV file, you can imagine that the entries of the table are delineated by commas.
Let's take a look at a concrete example. Say I type out the following text using the Windows Desktop app Notepad (generally used to make basic text files):
name, age, color
Tom, 22, gold
Todd, 34, blue
Kelly, 21, green
Avril, 27, purple
Okay, this doesn't seem too complicated, but it's kind of unclear what's happening when typed out this way. However, if we then save this file with the .csv extension and proceed to open it in Excel, we get the following spreadsheet:
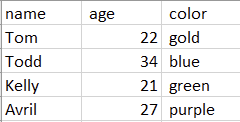
The color preferences of various humans.
Kinda cool, right? Each value separated by a comma defines a new column, and each set of values separated by a new line defines a new row. Now you know how to write your very own CSV files from scratch! Next, let's consider how we might do this with code.
How can you build a CSV file in Python?
Python has a couple of built-in ways to deal with CSV files (includes Pandas, mentioned above, as well as a csv module); however, those are topics for another article. Today, I'd like to show you how to programmatically build your own file from scratch. There are a couple of reasons for this:
- Using Pandas to define your CSV requires an understanding of data processing and manipulation using Pandas data structures, and I'd like to keep this article accessible to readers who need to work with CSV files but might not know Pandas.
- Other modules (like csv) have lots of built-in functions and specifications that can be helpful in specific cases, but today I want to show you how to make your own, simple CSV file without the need to use any fancy functions or operations.
Now then, let's get into it.
For consistency, let's build the same table we saw above. Let's break the problem down as follows:
- We know that each column is separated by a comma. Therefore, we can structure our data as Python strings, where our columns are delineated by commas.
- We know that each row is separated by a newline character. Therefore, we can define a new string (separated by commas for the columns) for each row.
- We need to write these strings into a file. Python has simple built-in functions which let you write lines one by one into a file — exactly what we need.
Let's do this step-by-step. First, let's define all of our comma-separated strings. We also put them into a list for easy access.
>>> header = 'name, age, color'
>>> row0 = 'Tom, 22, gold'
>>> row1 = 'Todd, 34, blue'
>>> row2 = 'Kelly, 21, green'
>>> row3 = 'Avril, 27, purple'
>>> data_list = [header, row0, row1, row2, row3]
>>> data_list
['name, age, color', 'Tom, 22, gold', 'Todd, 34, blue', 'Kelly, 21, green', 'Avril, 27, purple']
Now, we open a new file in “write” mode (meaning we can write into it). The syntax for this is as follows (note if you don't specify a path, it will be saved into the same directory as your Python file):
>>> my_file = open('data.csv', 'w')
Now, we can write our lines into the file one by one using the following code. Be sure to note how we manually write in a newline character after each row:
>>> for row in data_list:
... my_file.write(row)
... my_file.write('\n')
...
16
1
13
1
14
1
16
1
17
1
The numbers we see printed are the output of the write function, which returns the number of characters returned. When we're done, we need to close the file:
>>> my_file.close()
And voila! Now, we can open this file in Excel, and see the same display as before:
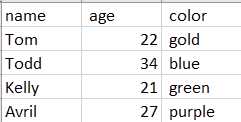
The color preferences of various humans, but this time defined in Python.
Final Thoughts
At this point, you should have a solid idea of how CSV files are formatted under the hood, and how you can define them manually in Python. Being able to do this has been helpful for me in formatting and processing my data, and I hope it is for you also.
Until next time, folks!
Comments
Loading comments…