
Most of the applications built today need a scheduling mechanism in some way or the other. Common examples are polling an API or a Database, check for system health frequently, dump logs into archives, etc. Auto-scaling software such as Kubernetes and Apache Mesos need to check the status of applications deployed, for which they use liveliness probes ran periodically. Scheduled tasks need to be decoupled from the business logic hence, one can use decoupled execution queues such as Redis queues.
Python has a few ways in which we can schedule a job, that's what we are going to learn in this article. I am going to discuss scheduling tasks using the following ways:
-
Simple Loops
-
Simple Loops but Threaded
-
Schedule Library
-
Python Crontab
-
RQ Scheduler as decoupled queues
Simple loops
This is a no-brainer. Using infinitely running while loops to periodically call a function can be used to schedule a job, not the best way but hey it works. Time delay can be given using the sleep function of the in-built time module. This is not exactly how most jobs are scheduled because first, it looks ugly and second, it’s less readable compared to other methods.
import time
def task():
print("Job Completed!")
while 1:
task()
time.sleep(10)
When it comes to scheduling routines like at 9:00 am every day or 7:45 pm every Wednesday, things get tricky.
import datetime
def task():
print("Job Completed!")
while 1:
now = datetime.datetime.now()
# schedule at every wednesday,7:45 pm
if now.weekday() == 3 and now.strftime("%H:%m") == "19:45":
task()
# sleep for 6 days
time.sleep(6 * 24 * 60 * 60)
My first reaction? Nope thank you! A problem with this approach is that the logic here is blocking i.e., once python discovers this piece of code in a project, it will get stuck in while 1 loop hence, blocking the execution of other code.
Simple loops but threaded
Threading is a concept in computer science where threads, small programs with their own instructions, are executed by a process and are managed independently. This can resolve the blocking nature of our 1st approach, let’s see how.
import time
import threading
def task():
print("Job Completed!")
def schedule():
while 1:
task()
time.sleep(10)
# makes our logic non blocking
thread = threading.Thread(target=schedule)
thread.start()
After a thread is started, its underlying logic cannot be modified by the main thread, therefore, we may need to add resources through which the program can check for specific scenarios and execute logic based on them.
Schedule Library
Earlier, I said scheduling using while loop looks ugly, schedule library takes care of that.
import schedule
import time
def task():
print("Job Executing!")
# for every n minutes
schedule.every(10).minutes.do(task)
# every hour
schedule.every().hour.do(task)
# every daya at specific time
schedule.every().day.at("10:30").do(task)
# schedule by name of day
schedule.every().monday.do(task)
# name of day with time
schedule.every().wednesday.at("13:15").do(task)
while True:
schedule.run_pending()
time.sleep(1)
As you can see, Multiple schedules can be created effortlessly. I especially like the way of creating jobs, the method chaining, on the other hand, this snippet has a while loop which means the code is blocking and you already know what can help us here.

Python Crontab
The crontab utility in Linux is an easy-to-use and widely accepted scheduling solution. A Python library, python-crontab, provides an API to use the CLI tool from Python. In crontab, a schedule is described using the unix-cron string format ( ), which is a set of five values in a line, indicating when the job should be executed. python-crontab transforms writing the crontab schedule in a file to a programmatic approach.
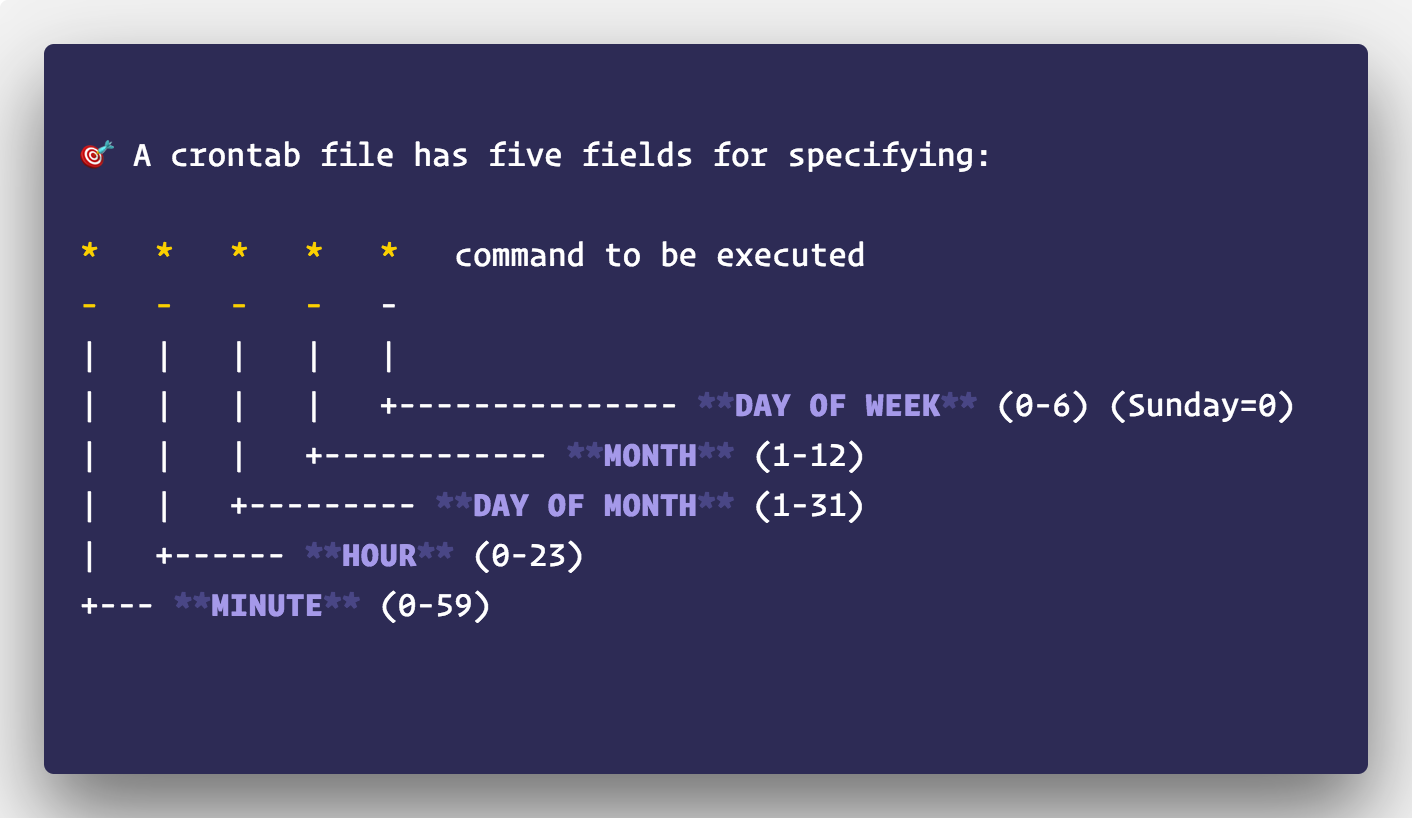 Image by Linux hint
Image by Linux hint
from crontab import CronTab
cron = CronTab(user='root')
job = cron.new(command='my_script.sh')
job.hour.every(1)
cron.write()
python-crontab doesn’t auto-save the schedules, the write() method needs to be executed to save the schedule. There are many more features and I urge you to have a look at their documentation.
RQ Scheduler
Some tasks cannot be executed immediately therefore we need to create a task queue and pop tasks according to a Queue system such as LIFO or FIFO. python-rq allows us to do exactly this, using Redis as a broker to queue jobs. The entry for a new job is stored as a hash map with info such as created_at, enqueued_at, origin, data, description .
Queued jobs are executed by a program called worker. Workers too have an entry in the Redis cache and are responsible for dequeuing a job along with updating the job status in Redis. Jobs can be queued as and when required but to schedule them we need rq-scheduler.
from rq_scheduler import Scheduler
queue = Queue('circle', connection=Redis())
scheduler = Scheduler(queue=queue)
scheduler.schedule(
scheduled_time=datetime.utcnow(), # Time for first execution, in UTC timezone
func=func, # Function to be queued
args=[arg1, arg2], # Arguments passed into function when executed
kwargs={'foo': 'bar'}, # Keyword arguments passed into function when executed
interval=60, # Time before the function is called again, in seconds
repeat=None, # Repeat this number of times (None means repeat forever)
meta={'foo': 'bar'} # Arbitrary pickleable data on the job itself
)
An RQ worker must be started separately in a terminal or via python-rq worker utility. As soon as a job is triggered, it can be seen in the worker terminal, separate function callbacks can be used in success and failure scenarios.
Conclusion
There are a few more libraries for scheduling but here, I have discussed the most common ones. An honorable mention would be Celery, added advantage of celery is that the user can choose between multiple brokers. I appreciate you reading till the end. Check out my other articles too. Cheers!
Comments
Loading comments…