 Web Server: When the client sends a request to open a webpage, the browser has to fetch the response from somewhere, and this somewhere is the webserver. Now suppose there is an application for a game:
Web Server: When the client sends a request to open a webpage, the browser has to fetch the response from somewhere, and this somewhere is the webserver. Now suppose there is an application for a game:
the client starts the game, the server responded to it, now the server can do 2 things:
- Wait for the client to make the next move.
- Check if there is another client who wants to play, to avoid the blocking.
NGINX is a web server, which follows 2nd point.
Reverse Proxy: accepts a request from a client, forwards it to a server that can fulfill it, and returns the server’s response to the client.
NGINX is a reverse proxy also. We can do caching, load balancing at NGINX as well
Nginx uses an asynchronous, event-driven approach where requests are handled in a single thread. There is one master process that controls multiple worker processes. Each worker can handle a large number of simultaneous connections. Workers are single-threaded, and since they are async, it means each request can be executed by the workers concurrently without blocking other requests. Like the above game example. You can tune NGINX according to your need with various parameters. Two of them are:
- worker_processes: The number of NGINX workers (default is 1). In most cases, running one worker process/ CPU core works well. But you can tune it accordingly.
- worker_connections: The maximum number of connections that each worker process can handle simultaneously. The default is 512, but most systems have enough resources to support a larger number.
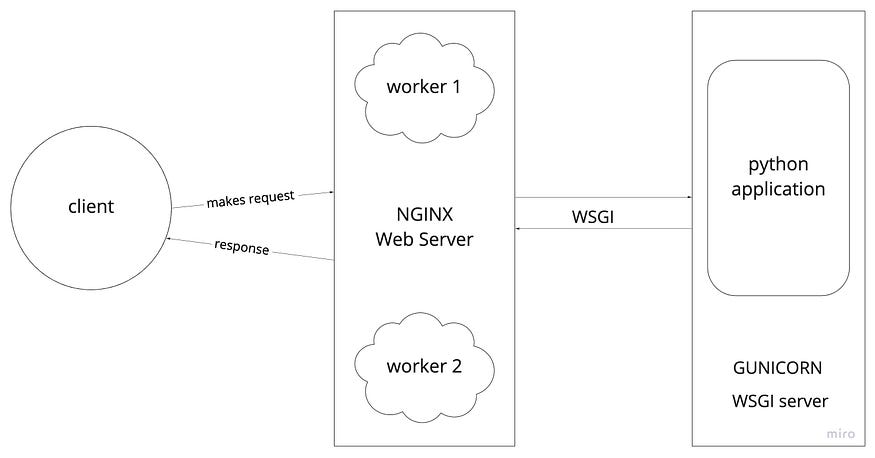
We kind of had web servers only in the initial days, and to run python applications, we had the mod_python module. But this is not very much suitable for Python applications. So people decided to define some standards with which webservers can talk to Python applications. WSGI is that standard.
WSGI: The Web Server Gateway Interface is a simple calling convention for web servers to forward requests to web applications or frameworks written in the Python programming language.
WSGI has two parts: Web Server, Python Application.
In this way, with WSGI we can seperate server code from the application code where you can add your business logic.
There are many frameworks in which you can write Python applications that support WSGI like Django, CherryPy, Flask, etc, but they are not good enough to handle thousands of requests concurrently or they don’t know how to best route them from the server. Therefore we kind of need another server where we can host our application which deals with the webserver.
An application server is a server that hosts applications. And for Python applications, the application servers are known as WSGI servers as they follow WSGI standards.
WSGI servers use their configuration to get the application’s path. WSGI applications are a single, synchronous callable that takes a request and returns a response. Its design is tied to the HTTP-style request/response cycle. So if we want to achieve a long-lived connection with it, it will block the server, and it is not good for real-time applications.
If we made WSGI as asynchronous callable, (which means it won’t wait for the response, it can switch to other tasks or process other requests), it won’t be able to handle the protocols that have multiple incoming events (like Websockets), because it has only a single path to provide a request.
So to handle all these people introduced ASGI standards. Its primary goal is to provide a way to write HTTP/2 and WebSocket code alongside normal HTTP handling code
ASGI: Asynchronous Server Gateway Interface is structured as a single, asynchronous callable. Applications are asynchronous callables rather than simple callables, and they communicate with the server by receiving and sending asynchronous event messages rather than receiving a single input stream and returning a single iterable.
It takes a
scope, which is adictcontaining details about the specific connection,send, an asynchronous callable, that lets the application send event messages to the client, andreceive, an asynchronous callable which lets the application receive event messages from the client.This not only allows multiple incoming events and outgoing events for each application, but also allows for a background coroutine so the application can do other things (such as listening for events on an external trigger, like a Redis queue).
Python never runs more than 1 thread per process because of the GIL. Even if you have 100 threads inside your process, the GIL will only allow a single thread to run at the same time. That means that, at any time, 99 of those threads are paused and 1 thread is working. Gunicorn is a way to get around this limitation.
Gunicorn: is a WSGI server based on the pre-fork worker model. This means that there is a central master process that manages a set of worker processes. The master never knows anything about individual clients. All requests and responses are handled completely by worker processes.
In gunicorn, we can define various parameters. Following are a few:
- workers: Number of workers you want to start. Generally, it is recommended to create (2 x $num_cores) + 1 as the number of workers to start with.
- threads: We can also define many threads/workers, by default it is 1.
- worker class: Worker class defines how workers will work. Gunicorn provides sync, gevent, evenlet, tornado, gthread worker classes. sync is the default.
Suppose you want to handle many requests/sec. If you use sync workers, you can either increase the workers or add more threads to a worker.
If you try to use the _sync_ worker type and set the _threads_ setting to more than 1, the _gthread_ worker type will be used instead.
Sync workers — The most basic and the default worker type is a synchronous worker class that handles a single request at a time.
Async workers (gevent, evenlet) — The asynchronous workers available are based on Greenlets (via Eventlet and Gevent).
As we know python doesn’t run more than 1 thread, so you have to increase the number of workers. But there is a tipping point where adding more workers has a negative impact on performance. So we can go for the async worker class, which uses green threads(Greenlets). You get the benefit of NOT having to create threads in your workers. Assume that you are getting threads w/o having to explicitly create them.
Greenlets, also known as green threads, cooperative threads or coroutines, give threads, but without using threads. Threads are managed by the operating system kernel. The operating system uses a general-purpose scheduler to switch between threads. This general-purpose scheduler is not always very efficient.
Greenlets emulate multi-threaded environments without relying on any native operating system capabilities. Greenlets are managed in application space and not in kernel space
Hope this helps you to understand the basics. There is a lot to explore, so happy exploring :)
Comments
Loading comments…