“Shuffle the cards, not the problems.” — Anonymous

As per Wikipedia.
Shuffling is a procedure used to randomize a deck of playing cards to provide an element of chance in card games
But what is Shuffling in the Spark world ??
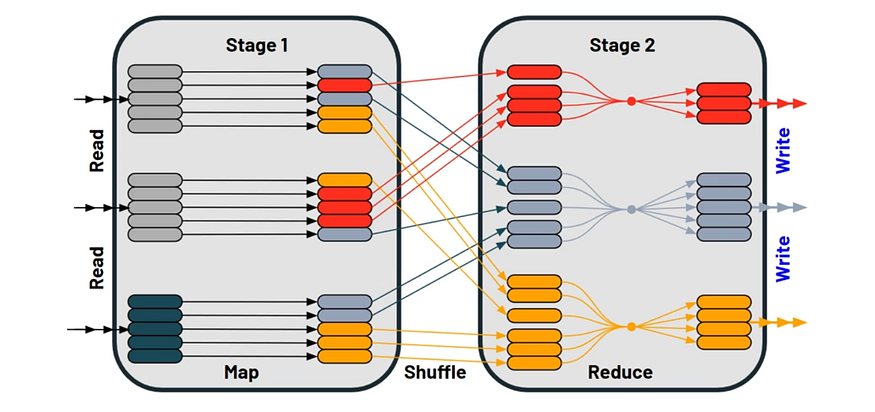
Apache Spark processes queries by distributing data over multiple nodes and calculating the values separately on every node. However, occasionally, the nodes need to exchange the data. After all, that’s the purpose of Spark — processing data that doesn’t fit on a single machine.
Shuffling is the process of exchanging data between partitions. As a result, data rows can move between worker nodes when their source partition and the target partition reside on a different machine.
Spark doesn’t move data between nodes randomly. Shuffling is a time-consuming operation, so it happens only when there is no other option.
Performance Impact
The Shuffle is an expensive operation since it involves disk I/O, data serialization, and network I/O. To organize data for the shuffle, Spark generates sets of tasks — map tasks to organize the data, and a set of reduce tasks to aggregate it. This nomenclature comes from MapReduce and does not directly relate to Spark’s map and reduce operations.
Internally, results from individual map tasks are kept in memory until they can’t fit. Then, these are sorted based on the target partition and written to a single file. On the reduce side, tasks read the relevant sorted blocks.
Certain shuffle operations can consume significant amounts of heap memory since they employ in-memory data structures to organize records before or after transferring them. Shuffle also generates a large number of intermediate files on disk.
Most Important Part → How to Avoid Spark Shuffle ??
- Use Appropriate Partitioning: Ensure that your data is appropriately partitioned from the beginning. If your data is already partitioned based on the operation you are performing, Spark can avoid shuffling altogether. Use functions like
repartition()orcoalesce()to control the partitioning of your data.
# Sample data
data = [(1, "A"), (2, "B"), (3, "C"), (4, "D"), (5, "E")]
# Create a DataFrame
df = spark.createDataFrame(data, ["id", "name"])
# Bad - Shuffling involved due to default partitioning (200 partitions)
result_bad = df.groupBy("id").count()
# Good - Avoids shuffling by explicitly repartitioning (2 partitions)
df_repartitioned = df.repartition(2, "id")
result_good = df_repartitioned.groupBy("id").count()
- Filter Early: Apply filters or conditions to your data as early as possible in your transformations. This way, you can reduce the amount of data that needs to be shuffled through the subsequent stages.
# Sample data
sales_data = [(101, "Product A", 100), (102, "Product B", 150), (103, "Product C", 200)]
categories_data = [(101, "Category X"), (102, "Category Y"), (103, "Category Z")]
# Create DataFrames
sales_df = spark.createDataFrame(sales_data, ["product_id", "product_name", "price"])
categories_df = spark.createDataFrame(categories_data, ["product_id", "category"])
# Bad - Shuffling involved due to regular join
result_bad = sales_df.join(categories_df, on="product_id")
# Good - Avoids shuffling using broadcast variable
# Filter the small DataFrame early and broadcast it for efficient join
filtered_categories_df = categories_df.filter("category = 'Category X'")
result_good = sales_df.join(broadcast(filtered_categories_df), on="product_id")
- Use Broadcast Variables: If you have small lookup data that you want to join with a larger dataset, consider using broadcast variables. Broadcasting the small dataset to all nodes can be more efficient than shuffling the larger dataset.
# Sample data
products_data = [(101, "Product A", 100), (102, "Product B", 150), (103, "Product C", 200)]
categories_data = [(101, "Category X"), (102, "Category Y"), (103, "Category Z")]
# Create DataFrames
products_df = spark.createDataFrame(products_data, ["product_id", "product_name", "price"])
categories_df = spark.createDataFrame(categories_data, ["category_id", "category_name"])
# Bad - Shuffling involved due to regular join
result_bad = products_df.join(categories_df, products_df.product_id == categories_df.category_id)
# Good - Avoids shuffling using broadcast variable
# Create a broadcast variable from the categories DataFrame
broadcast_categories = broadcast(categories_df)
# Join the DataFrames using the broadcast variable
result_good = products_df.join(broadcast_categories, products_df.product_id == broadcast_categories.category_id)
- Avoid Using
**groupByKey()**: PreferreduceByKey()oraggregateByKey()instead ofgroupByKey()as the former performs partial aggregation locally before shuffling the data, leading to better performance.
# Sample data
data = [(1, "click"), (2, "like"), (1, "share"), (3, "click"), (2, "share")]
# Create an RDD
rdd = sc.parallelize(data)
# Bad - Shuffling involved due to groupByKey
result_bad = rdd.groupByKey().mapValues(len)
# Good - Avoids shuffling by using reduceByKey
result_good = rdd.map(lambda x: (x[0], 1)).reduceByKey(lambda a, b: a + b)
- Use Data Locality: Whenever possible, try to process data that is already stored on the same node where the computation is happening. This reduces network communication and shuffling.
# Sample data
data = [(1, 10), (2, 20), (1, 5), (3, 15), (2, 25)]
# Create a DataFrame
df = spark.createDataFrame(data, ["key", "value"])
# Bad - Shuffling involved due to default data locality
result_bad = df.groupBy("key").max("value")
# Good - Avoids shuffling by repartitioning and using data locality
df_repartitioned = df.repartition("key") # Repartition to align data by key
result_good = df_repartitioned.groupBy("key").max("value")
- Use Memory and Disk Caching: Caching intermediate data that will be reused in multiple stages can help avoid recomputation and reduce the need for shuffling.
# Sample data
data = [(1, 10), (2, 20), (1, 5), (3, 15), (2, 25)]
# Create a DataFrame
df = spark.createDataFrame(data, ["key", "value"])
# Bad - Shuffling involved due to recomputation of the filter condition
result_bad = df.filter("value > 10").groupBy("key").sum("value")
# Good - Avoids shuffling by caching the filtered data
df_filtered = df.filter("value > 10").cache()
result_good = df_filtered.groupBy("key").sum("value")
- Optimize Data Serialization: Choose efficient serialization formats like Avro or Kryo to reduce the data size during shuffling.
# Create a Spark session with KryoSerializer
spark = SparkSession.builder \
.appName("AvoidShuffleExample") \
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") \
.getOrCreate()
- Tune Spark Configurations: Adjust Spark configuration parameters like
spark.shuffle.partitions,spark.reducer.maxSizeInFlight, andspark.shuffle.file.bufferto fine-tune the shuffling behavior. - Monitor and Analyze: Use Spark’s monitoring tools like Spark UI and Spark History Server to analyze the performance of your jobs and identify areas where shuffling can be optimized.
By following these best practices and optimizing your Spark jobs, you can significantly reduce the need for shuffling, leading to improved performance and resource utilization. However, in some cases, shuffling may still be unavoidable, especially for complex operations or when working with large datasets. In such cases, focus on optimizing shuffling rather than completely avoiding it.
Comments
Loading comments…