Speed and performance matter when it comes to data operations. It is often tempting for us to write pandas data operations without caring much about the speed, however, once the scale of the data reaches a certain limit, for loop and map operations become very slow with DataFrames and as you will see, only vectorized series operations and vectorized array operations remain reasonably fast. Today we want to demonstrate how you can vectorize your pandas code and compare the speed performance of each operation.
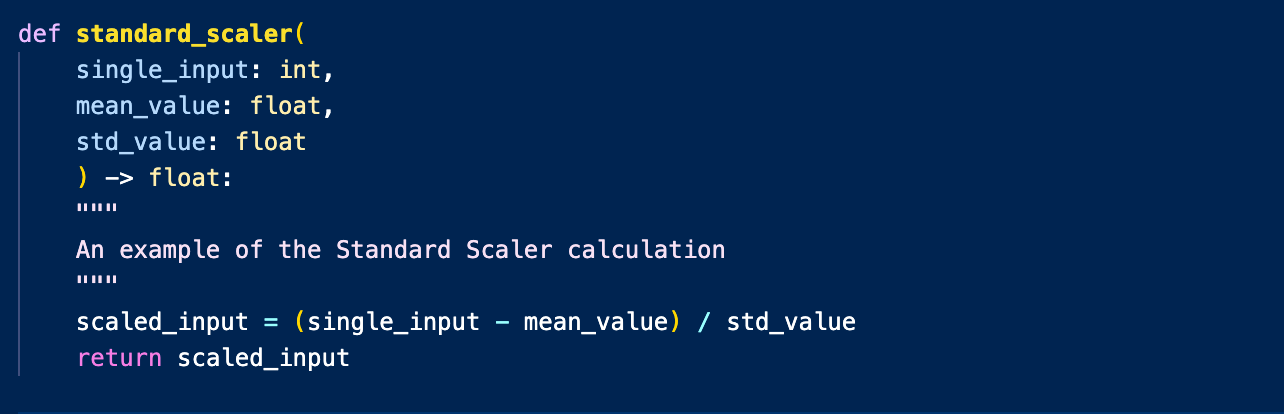
Example: Standard Scaler
For practical purposes, we are using the Standard Scaler calculation as an example, which is typically used to standardize your dataset for many traditional machine learning models to run on.
#Standard Scaler
z = (x - u) / s
Sample Implementation:
Dataset:
We are using a randomly generated dataset with a size of 100,000,000 rows and 3 columns.
What it looks like:
DataFrame Iterrows:
Iterrows() allows you to iterate through a pandas DataFrame row by row and it’s usually an approach to be avoided. As in this case, we couldn’t even finish the code within the time limit we set.
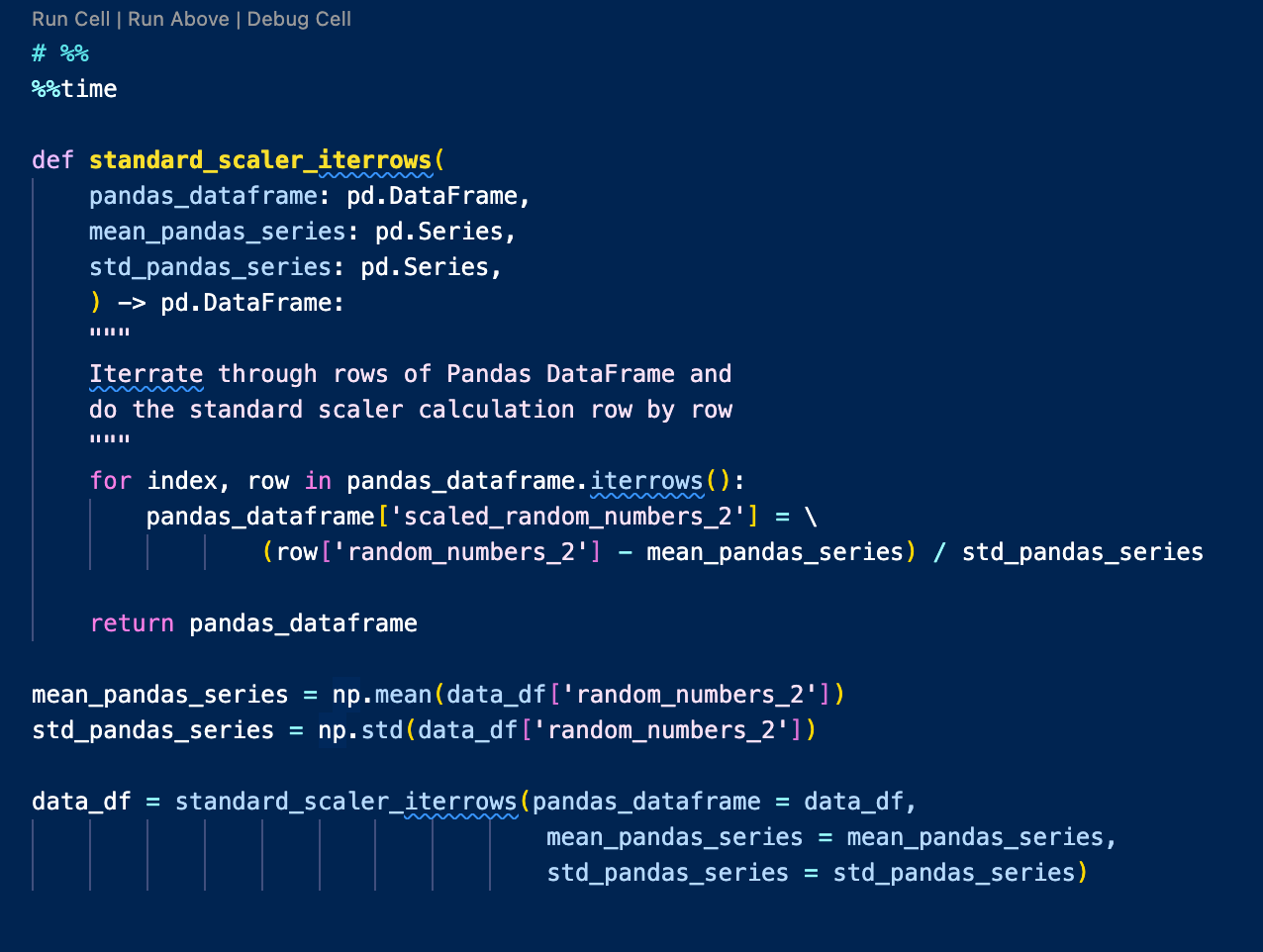
Performance: Timed Out
Series Apply:
For the next approach, we use pd.Series.apply() function to map through Pandas Series. Note that when you use pd.Series.apply(), there isn’t an argument for axis, as there is only one column. And for custom functions, you would have to pass in the additional arguments with the args parameter.
Performance: 37.1s

Series Map:
We could also choose to map the function over each element within the Pandas Series. This is somewhat faster than Series Apply, but still relatively slow.
Performance: 31.5s

Vectorized Series:
Based on the definition given by the official Numpy documentation, vectorization is defined as being “able to delegate the task of performing mathematical operations on the array’s contents to optimized, compiled C code.” Instead of looping through rows, columns or elements, this allows us to apply one set of instructions on multiple elements at the same time.
Here we are utilizing the built-in vectorization operation from pandas Series with NumPy. Many data operations can and should be vectorized. Even if you don’t have the built-in vectorization operations from pandas Series as custom functions can get complex, you can probably still find many vectorized operations available in Numpy. This is where the power of NumPy and pandas can be combined.

Performance: 316 ms

Vectorized Array:
By using the NumPy array directly (you can convert Pandas Series to NumPy arrays by calling the .values attribute), you can speed up things even further from the vectorized Series.

Performance: 298 ms

Summary:
For 100,000,000 rows of data, we have summarized the performance of different data operations below:
Iterrows: Timed Out Series Apply: 37.1 s Series Map: 31.5 s Vectorized Series: 316 ms Vectorized Arrays: 298 ms
Takeaway: When the size of data gets big, we always want to stick with vectorized operations, Series or Arrays. We should try to avoid Iterrows as much as possible. When there are no vectorized operations available for your use case, then stick to the Map operations.
Hope you find this helpful! Thanks for reading this week’s tip! Check out other Data Hacks on Dataproducts.io.
Comments
Loading comments…