
Why JSON to Pandas?
There is a ton of data out there on the web and much of it exists in a specific format called JavaScript Object Notation (JSON). However, while JSON is well suited to exchange large amounts of data between machines, it’s not easy for humans to read or process. On the flip side, Python and Pandas have become the go-to tools to help us analyze and visualize data. As a result, chances are high that you will eventually have to tackle the JSON to Pandas problem in Python.
The topic of JSON in Python with Pandas is a well-worn path; however, in this story, I share a straight-forward solution that handles the task of getting JSON data from an API into your Pandas DataFrame. In addition, my solution accounts for a Pandas update to json_normalize as well as handling certificate validation warnings when getting data over the Internet.
To understand more on the technical background of JSON, check out this article on medium.com.
Scenario
In this project, I’m researching crime in Washington, D.C. and want to leverage the city’s OpenData portal to further my research. Once I get the data, I can run statistics, create visualizations, and hopefully, learn something worth sharing.
To be sure, we can easily download data in CSV or Excel formats and then process that data to whatever end. However, while the spreadsheet download and ingest method works just fine, we can perform the “get” task in just one step by reading data directly into a Pandas DataFrame. Also, I think this method lends itself better to automation as part of a workflow or data pipeline.
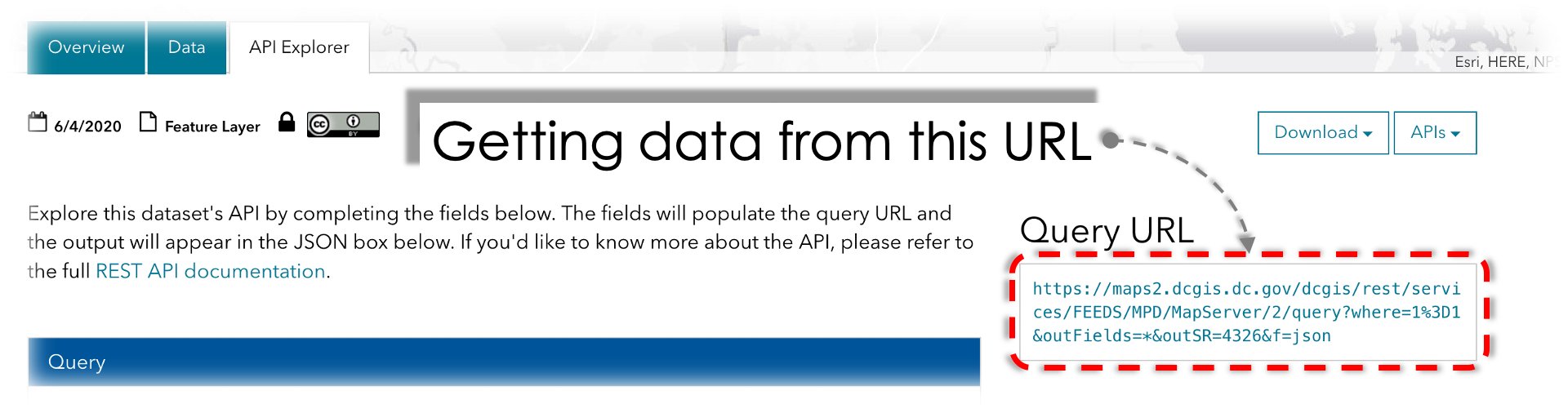 Basic Task — Read data from the OpenData API URL directly into a Pandas DataFrame in Python. A screenshot from OpenData DC.
Basic Task — Read data from the OpenData API URL directly into a Pandas DataFrame in Python. A screenshot from OpenData DC.
Overview
I am running this project in Google Colab and you can skip right to the notebook below or following along the steps in this story.
Google Colaboratory with Justin Chae
Although I break down the project into several steps, it is really two-part.
First, start with a known data source (the URL of the JSON API) and get the data with urllib3. Second, use Pandas to decode and read the data. The result is a Pandas DataFrame that is human readable and ready for analysis.
Step 0 — Import Libraries
# to handle data retrieval
import urllib3
from urllib3 import request
# to handle certificate verification
import certifi
# to manage json data
import json
# for pandas dataframes
import pandas as pd
# uncomment below if installation needed (not necessary in Colab)
#!pip install certifi
**Note: **I recently learned that pandas.io.json.json_normalize is deprecated. As a result, notice how my project simply calls Pandas.json_normalize. According to the future warning (copy below), the code will work, but switching to the new stuff is recommended.
# example of what not to do
from pandas.io.json import json_normalize
data = json_normalize(data)
>>> FutureWarning: pandas.io.json.json_normalize is deprecated, use pandas.json_normalize instead
Step 1 — Handle Certificate Validation
# handle certificate verification and SSL warnings
# https://urllib3.readthedocs.io/en/latest/user-guide.html#ssl
http = urllib3.PoolManager(
cert_reqs='CERT_REQUIRED',
ca_certs=certifi.where())
Do not ignore certificate warnings. Although you can proceed without using certifi, you are taking an unnecessary cybersecurity risk. For more, see the urllib3 documentation.
Step 2 — Get Data from Web API
# get data from the API
url = 'https://maps2.dcgis.dc.gov/dcgis/rest/services/FEEDS/MPD/MapServer/2/query?where=1%3D1&outFields=*&outSR=4326&f=json'
r = http.request('GET', url)
r.status
The expected output of r.status is code 200 which means everything is OK.
Step 3 — Decode JSON Data to Dict
# decode json data into a dict object
data = json.loads(r.data.decode('utf-8'))
data
At this point, when printing data, the notebook will display the entire dataset as a dict —basically in JSON format.
Next, after decoding, json.loads gives us the data in what is essentially, JSON format. Scroll to the top and notice how the data we want is under “features.”
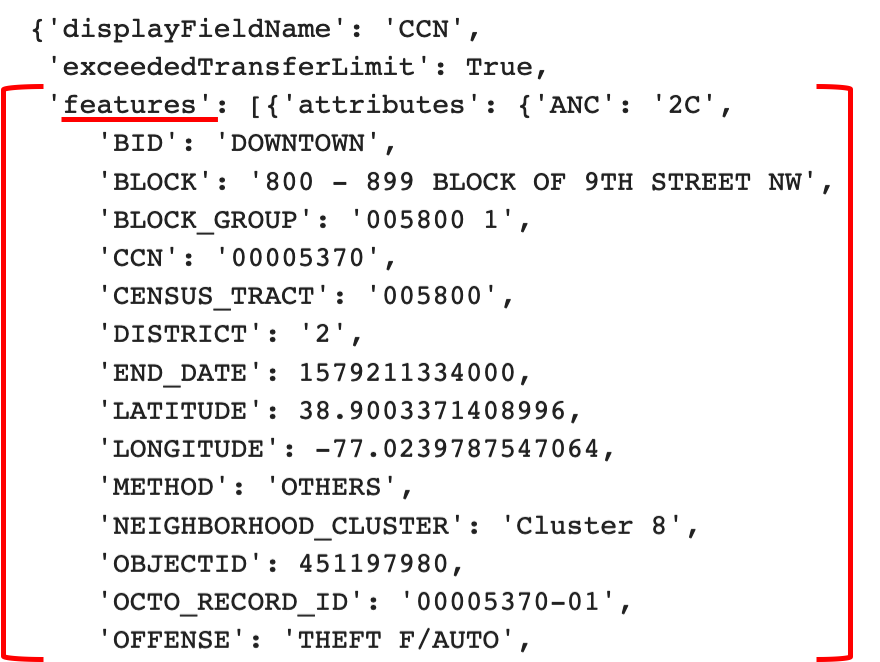
**Okay, this next step will vary for almost every project so take some time to carefully inspect the data. **For example, in this particular dataset, the elements of interest are under a level called “features.”
Knowing what the data looks like is important because if I don’t know to look under features, then the dataframe will only contain the top-level headers which are, to me, useless. If you get a table that looks like the following screenshot, take a minute to inspect the data — you are probably close, but are off by just a bit.
 Underwhelming result when reading JSON to Pandas DataFrame. A single row is produced with no actual data and only headers. This is solved by reading the proper level of data.
Underwhelming result when reading JSON to Pandas DataFrame. A single row is produced with no actual data and only headers. This is solved by reading the proper level of data.
Step 4 — Normalize Dict to Pandas DataFrame
# in this dataset, the data to extract is under 'features'
df = pd.json_normalize(data, 'features')
df.head(10)
Lastly, we get to the decisive part of the project — data is in a nice table-like format in Pandas.
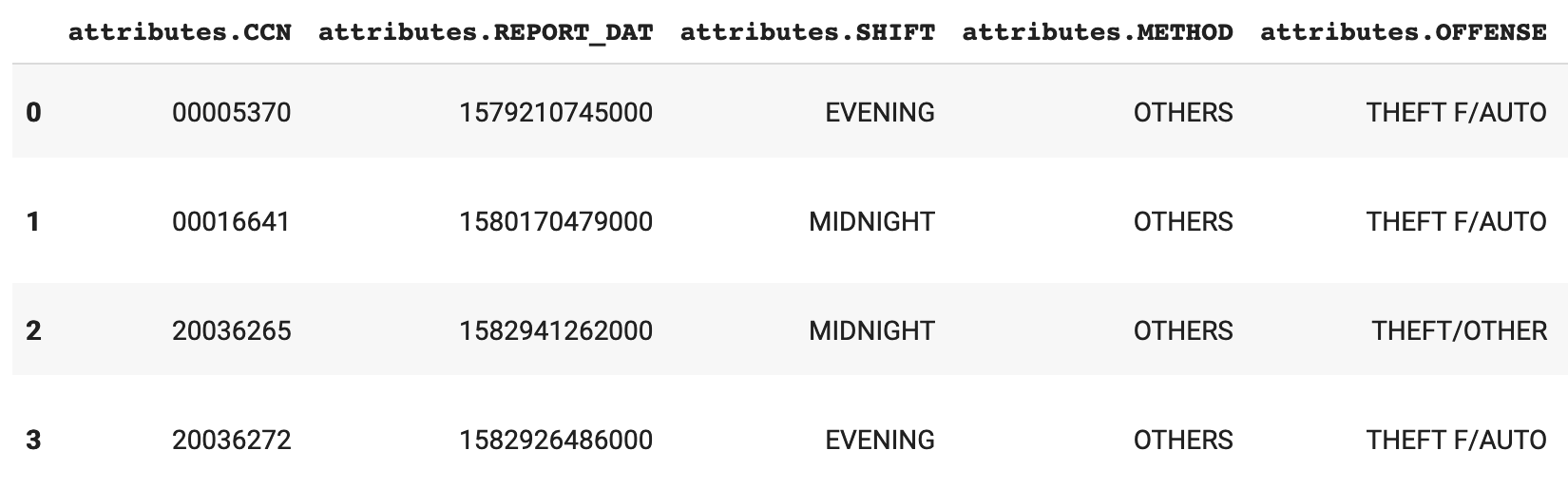 Data that started in JSON format now in a Pandas DataFrame and ready for further analysis.
Data that started in JSON format now in a Pandas DataFrame and ready for further analysis.
Finish
For many data projects, there will be a need to manage JSON data in Python. In this story, I’ve presented one way to tackle the problem with Google Colab and Washington, D.C.’s OpenData API. I hope this helps with your project.
Thoughts or comments? I’d love to hear from you.
Cheers,
-Justin
Resources
What is open data? Check out the Open Data Handbook at https://opendatahandbook.org/guide/en/what-is-open-data/
What’s up with Google Colab? https://colab.research.google.com
More on JSON and Pandas: https://towardsdatascience.com/flattening-json-objects-in-python-f5343c794b10
Pandas Documentation: https://pandas.pydata.org/pandas-docs/stable/index.html
Urllib3 Documentation: https://urllib3.readthedocs.io/en/1.5/#usage
Comments
Loading comments…