Previously, I followed Andrej Karpathy’s tutorial, where he implemented a character-level GPT from scratch. In this post, I will do the same for his tokenizer video. I will follow along and elaborate on the topics he mentions, as well as the code.
From Bigrams to Transformers: Building a GPT Model from Scratch
What is a Tokenizer?
A tokenizer is a component that converts raw text into a sequence of tokens, which are discrete units that a language model can process.
Since neural networks operate on numbers rather than text, the tokenizer performs two key steps:
- Splitting text into tokens (characters, words, or subwords)
- Mapping each token to a numeric ID
Text: "hello"
Tokens: ["h", "e", "l", "l", "o"]
Token IDs: [7, 4, 11, 11, 14]
The output sequence of token IDs is what the model actually receives as input.
Vocabulary Size
The vocabulary is the set of all possible tokens that the tokenizer can produce.
The vocabulary size is simply the number of unique tokens in that set.
For example, in a character-level tokenizer, every unique character becomes a token (like we did in the previous post on the Shakespeare dataset).
Text: "hello world"
Unique characters:
['h', 'e', 'l', 'o', ' ', 'w', 'r', 'd']
Vocabulary size:
|V| = 8
Each character is assigned an integer ID:
{
'h':0,
'e':1,
'l':2,
'o':3,
' ':4,
'w':5,
'r':6,
'd':7
}
Character level Encoding:
"hello"
→ ['h','e','l','l','o']
→ [0,1,2,2,3]
Embedding Table
Neural networks cannot work directly with token IDs because integers do not contain semantic information. Instead, each token ID is mapped to a dense vector representation using an embedding table.
An embedding table is simply a learnable matrix.
vocab_size = V
embedding_dim = D
Then the embedding table has shape: (V,D)

Embedding Table.
Token ID Embedding
------------------------------
h 0 [0.21, -0.13, 0.44, 0.02]
e 1 [0.55, 0.61, -0.22, 0.31]
l 2 [-0.40, 0.18, 0.73, -0.11]
...
When the model receives the sequence:
[0,1,2,2,3]
It performs a lookup:
Embedding[0]
Embedding[1]
Embedding[2]
Embedding[2]
Embedding[3]
Resulting in a matrix:
(sequence_length, embedding_dim)
Example:(5,4)
This matrix is what enters the transformer.
Subwords
Tokenizers use algorithms like BPE, WordPiece, or SentencePiece to build a vocabulary of ~30k to 100k subword units.
You can visit https://tiktokenizer.vercel.app/ to view a tokenizer directly in the browser. By entering some text and selecting a model, you can see how the text is tokenized in real time.
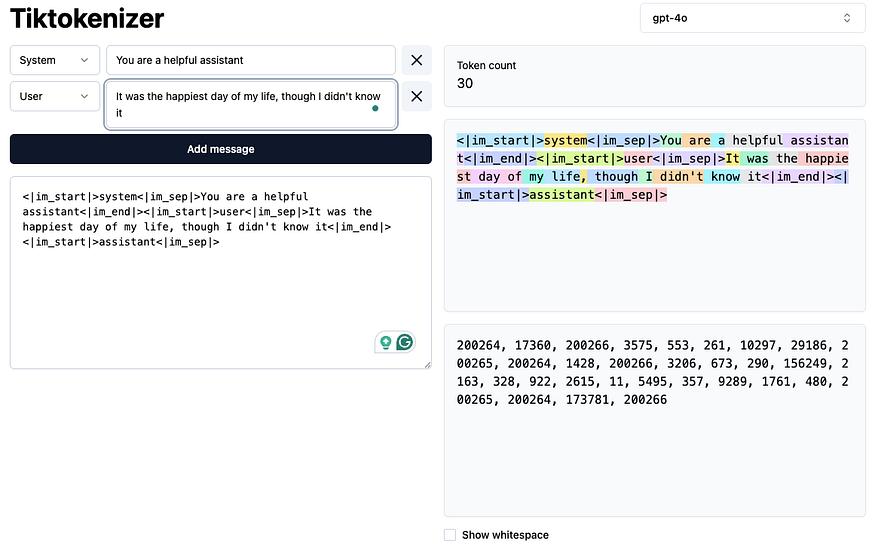
Tiktokenizer
Rather than storing every possible word, they store common fragments, prefixes like "un-", roots like "run", suffixes like "-ing", "-tion".
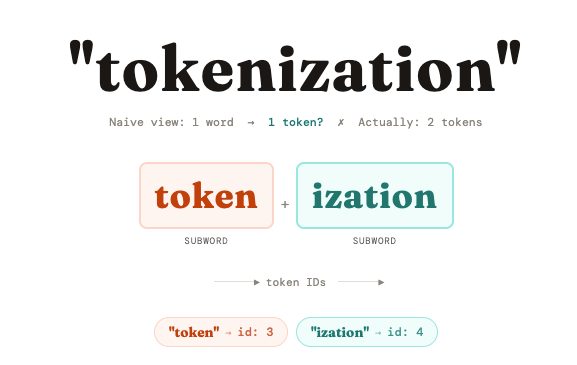
“tokenization” is not in the vocabulary as a single token. Instead it’s split into “token” (a common root) and “ization” (a common suffix). Both pieces are in the vocab, so the model understands the word through its parts.
UTF-8 Encoding
Before we can tokenize text, we need to understand how text exists inside a computer.

Unicode. Source
Computers do not store characters like “a” or "안". They only store bytes, which are numbers between 0 and 255.
So any text must first be converted into a sequence of bytes. One of the most widely used systems for doing this is UTF-8.
UTF-8 is a variable-length encoding that converts Unicode characters into a sequence of 1–4 bytes.
Unicode defines every character used in human writing systems. UTF-8 defines how those characters are represented as bytes.
A byte is an 8-bit number. Because it has 8 bits, a byte can represent 256 possible values.
list("hello".encode("utf-8"))
# We get:
[104, 101, 108, 108, 111]
These numbers are raw byte values. Each of these numbers corresponds to one byte (8 bits).
104 → 01101000
101 → 01100101
108 → 01101100...
- English letters → 1 byte
- Korean characters → 3 bytes
- Emojis → 4 bytes
This is why UTF-8 is called variable-length encoding.
Byte Pair Encoding (BPE)
The problem with byte-level tokens is that sequences become very long.
hello → [104,101,108,108,111]
Instead of 5 tokens, we would prefer something like:
["hello"]
# or
["hel","lo"]
Byte Pair Encoding repeatedly merges the most common pair of tokens into a new token.
This gradually builds larger subwords.
Start with:
base vocabulary = 256 byte tokens
Then we repeatedly learn new tokens like:
(104,101) -> token 256 ("he")
(256,108) -> token 257 ("hel")
(257,108) -> token 258 ("hell")
(258,111) -> token 259 ("hello")
Over time, the vocabulary grows from:
256 → 50,000 tokens
Suppose we start with this training text:
banana banana bandana
First tokenize to characters:
b a n a n a
b a n a n a
b a n d a n a
Step 1 — Count Adjacent Pairs
Pairs:
(b,a)
(a,n)
(n,a)
(a,n)
(n,a)
Counts:
(a,n) = 5
(n,a) = 5
(b,a) = 3
Most frequent pair:
(a,n)
Step 2 — Merge
Merge (a,n) → AN
b AN AN a
b AN AN a
b AN d AN a
Step 3 — Repeat
New pairs:
(b,AN)
(AN,AN)
(AN,a)
(AN,d)
(d,AN)
Suppose (AN,a) is most frequent.
Merge again:
ANa
Now, tokens become larger pieces.
After many merges, we get tokens like:
banana
band
ana
BPE does not operate on characters. It operates on bytes.
Example:
"안"
UTF-8:
[236,149,136]
BPE might later merge:
(236,149) -> token 256
(256,136) -> token 257
Now, token 257 represents the entire Korean character.
Density in token space
The languages that appear more frequently in the tokenizer dataset will receive more dedicated tokens. Those langauges therefore, become more compressed in token space.
Suppose your tokenizer training dataset is mostly English text.
Example frequent byte sequences:
"th"
"he"
"ing"
"tion"
"the"
BPE will create tokens like:
the
ing
tion
Now the word:
internationalization
might tokenize like:
inter + national + ization
Only 3 tokens. So, English becomes very efficient.
Japanese uses characters like:
こんにちは
UTF-8 bytes for these characters are long sequences. If Japanese is rare in the tokenizer training set, BPE will not see those byte patterns frequently. So it will not create merges for them. Instead the tokenizer might split Japanese into many byte pieces:
[232,130,167, ...]
So a single Japanese word might become 10+ tokens.
That means:
Japanese → long token sequences
English → short token sequences
Think of token space as the representation budget of the model.
The model processes tokens.
So if a sentence takes:
English: 10 tokens
Japanese: 40 tokens
then Japanese consume 4x more of the context window. That means the model can see less Japanese text at once.
But if Japanese is well represented in tokenizer training, it might become:
English: 10 tokens
Japanese: 12 tokens
Now both languages are dense in token space.
Forcing certain boundaries using a regex pre-tokenization step
In theory, Byte Pair Encoding could merge anything:
"hello!!!world123"
Without constraints, BPE might learn strange merges like:
"world123"
"!!!w"
These are undesirable because they mix different semantic categories:
- letters
- numbers
- punctuation
- whitespace
So GPT-2 first splits the text into chunks using regex, and BPE only runs inside those chunks.
gpt-2/src/encoder.py at master · openai/gpt-2
self.pat = re.compile(r"""'s|'t|'re|'ve|'m|'ll|'d| ?\p{L}+| ?\p{N}+| ?[^\s\p{L}\p{N}]+|\s+(?!\S)|\s+""")
The pattern used in GPT-2 is written with the regex library.
's | 't | 're | 've | 'm | 'll | 'd
These explicitly capture English contractions.
I've → "I" + "'ve"
don't → "don" + "'t"
she'll → "she" + "'ll"
This ensures BPE does not merge contractions incorrectly.
Hello've
becomes:
Hello
've
Words
?\p{L}+
Meaning:
optional space + sequence of letters
\p{L} means any Unicode letter.
Examples matched:
Hello
world
how
are
you
If a space exists, it is captured together:
" world"
" how"
This preserves leading whitespace, which GPT-2 uses as a signal.
Numbers:
?\p{N}+
\p{N} means Unicode number characters. So numbers are kept separate from words.
world123
becomes:
world
123
Punctuation / Symbols
?[^\s\p{L}\p{N}]+
This means
optional space + characters that are NOT:
whitespace
letters
numbers
So punctuation groups together.
!!!?
Instead of splitting as:
!
!
!
?
GPT-2 keeps them together.
An example:
Hello've world123 how's are you!!!?
Regex split:
['Hello', "'ve", ' world', '123', ' how', "'s", ' are', ' you', '!!!?']
Without this regex rule, BPE might learn weird tokens like:
"dog123"
"!!!hello"
Those tokens would generalize poorly. By forcing a split across:
letters
numbers
punctuation
spaces
The tokenizer becomes more robust and reusable.
Special Tokens
A special token is a reserved token in the tokenizer vocabulary that has a predefined meaning.
These tokens are not produced by normal tokenization rules like BPE. Instead, they are explicitly inserted when needed.

Special tokens. Source
GPT-2 defines:
encoder['<|endoftext|>']
This token marks the boundary between documents in the training data.
For example, the training dataset may look like this:
Document A
<|endoftext|>
Document B
<|endoftext|>
Document C
During training, the model sees something like:
"... last sentence of doc A <|endoftext|> first sentence of doc B ..."
So the model learns that:
<|endoftext|>indicates a hard boundary- A new document starts after it
Modern LLMs use several special tokens.
<bos> start of sequence
<eos> end of sequence
<pad> padding token
<unk> unknown token
<sys> system prompt
<assistant>
<user>
...
Tiktoken vs SentencePiece
When training or running LLMs, tokenizers are rarely implemented from scratch. Instead, production systems rely on optimized libraries such as:
Both implement subword tokenization algorithms like BPE, but they differ in what they operate on internally.

tiktoken approach
The GPT tokenizer pipeline looks like this:
text
↓
UTF-8 encoding
↓
bytes (0–255)
↓
BPE merges on bytes
↓
tokens
Example:
hello
↓
UTF-8
↓
[104,101,108,108,111]
↓
BPE merges
↓
["hello"]
Any text is guaranteed to be representable because UTF-8 bytes cover everything.
This design was introduced in GPT-2 and continues in later OpenAI models.
SentencePiece approach
SentencePiece works slightly differently.
Instead of starting from bytes, it starts from Unicode code points (characters).
text
↓
Unicode characters
↓
BPE merges on characters
↓
tokens
Example:
hello
↓
[h,e,l,l,o]
↓
BPE merges
↓
["hello"]
So the base units are characters instead of bytes.
This difference introduces a problem: Unicode contains hundreds of thousands of characters.
To control vocabulary growth, SentencePiece introduces character_covarage (i.e., 0.99995)
It means: include characters covering 99.995% of the training corpus.
Very rare characters are handled in two ways:
- UNK token: Rare characters become
<unk>. - byte fallback: If
byte_fallback=True, SentencePiece converts rare characters to UTF-8 bytes.
SentencePiece has several practical advantages.
- It can train tokenizers effectively. Unlike
tiktoken, it includes optimized implementations. - SentencePiece trains directly from raw text, without requiring preprocessing.
Why can’t LLMs spell words?
Because letters are not always individual tokens.
Why can’t LLMs do simple string tasks like reversing a string?
Reversing characters assumes the input is:
[a, b, c, d]
But the model sees something like:
["ab", "cd"]
Why are LLMs worse at non-English languages?
Because tokenizers are often trained mostly on English text.
English → few tokens per sentence
Japanese → many tokens per sentence
Why are LLMs bad at simple arithmetic?
Numbers are usually split into tokens.
12345
→ ["123", "45"]
Why did GPT-2 struggle with Python code?
Early tokenizers were optimized for natural language, not code.
Why does the generation stop when <|endoftext|> appears?
Because <|endoftext|> is a special token used to mark document boundaries. When the model predicts it, generation systems usually treat it as: STOP GENERATION.
Why do I get warnings about trailing whitespace?
Because tokenizers often encode spaces as part of tokens.
"hello world"
["hello", " world"]
Trailing spaces change tokenization:
"hello "
→ ["hello", " "]
Why did the model break with "SolidGoldMagikarp"?
This is a famous tokenizer pathology.
The word appears in GPT-2’s tokenizer training data, but never in LLM’s training data. Since the model never saw this token, it behaves unpredictably when it appears.
Furthermore, since it never saw that token during training, the embedding vector for that token was never updated (it stayed as its random initialization).
When you prompt the model with it, the model sees a “random” vector and gets “confused”, often resulting in the model repeating the token or refusing to speak.
Why prefer YAML over JSON with LLMs?
Because YAML uses fewer tokens.
Why is LLM not truly end-to-end language modeling?
Because the tokenizer is a separate preprocessing step.
From Bigrams to Transformers: Building a GPT Model from Scratch
Attention Is All You Need — Understanding the Transformer Model
Sources
https://www.youtube.com/watch?v=zduSFxRajkE&list=PLAqhIrjkxbuWI23v9cThsA9GvCAUhRvKZ&index=9
Comments
Loading comments…