Most explanations of AI fall into one of two failure modes.
They are either so technical that only a machine learning engineer can follow them, or so vague that they say nothing at all. “Our AI analyzes content holistically.” “Our system uses advanced algorithms.” “We leverage cutting-edge deep learning.” These phrases appear in press releases and investor decks across the industry, and they are essentially meaningless.
I want to do something different.
I want to give you a genuine, plain-English explanation of how multimodal AI actually works — the kind of explanation that respects your intelligence without assuming you have a PhD in computer science. Because the technology behind context-aware content moderation is not magic, and it is not a black box. It is a set of engineering decisions that have real, traceable consequences for every moderation outcome a platform produces.
Understanding those decisions is the first step toward demanding better ones.
Start Here: What “Multimodal” Actually Means
The word “multimodal” simply means multiple modes of input. A unimodal system processes one type of data. A multimodal system processes several types simultaneously and synthesizes them into a single output.
Your own brain is multimodal. When you watch a video, you are not processing the audio separately from the visuals and then manually combining the results. You are experiencing them as a unified whole, where each stream of information shapes how you interpret the others. The tone of someone’s voice changes the meaning of their words. The visual context of a scene changes how you read a gesture. The cultural familiarity of a setting changes how you interpret everything in it.
This is exactly the capacity that unimodal AI systems lack, and exactly the capacity that multimodal systems are designed to replicate.
In the context of video content moderation, the relevant input modes are: audio, visual, text, and behavioral metadata. A multimodal system ingests all four simultaneously. The insight that comes out the other side is qualitatively different from what any single stream could produce alone.
The Four Input Streams: What the System Is Actually Reading
Stream 1: Audio
Audio analysis in a multimodal moderation system operates on two levels simultaneously.
The first is speech-to-text transcription: converting spoken language into a text representation that can be processed for meaning, keywords, and semantic content. This sounds straightforward, but it is where most global AI systems begin to struggle. Standard transcription models are optimized for clean, standard-dialect speech in a handful of dominant languages. Regional accents, local dialects, and code-switching between languages produce transcription errors that cascade into every downstream decision.
The second level is paralinguistic analysis: reading the characteristics of the audio signal itself, independent of the words being spoken. Tone, pitch, cadence, emotional register, volume dynamics. A sentence delivered with calm, measured pacing carries a different intent signal than the same sentence delivered with rising aggression, even if the words are identical. Paralinguistic analysis captures that difference.
Together, these two layers give the system a richer representation of what is being communicated than either could produce alone.
Stream 2: Visual
Visual analysis in video moderation has historically been the most developed stream, and also the most overestimated.
Object detection (identifying what physical things are present in a frame) is something modern computer vision models do with impressive accuracy. The challenge, as I have written before, is that object detection without contextual interpretation is often useless or actively misleading. A knife is identified. A weapon is flagged. The cooking tutorial is removed.
Mature visual analysis goes beyond object detection into action recognition: understanding not just what is present in a frame, but what is happening across a sequence of frames. Is the identified object being used in a way that suggests harm? Is the physical interaction between people aggressive or playful? Does the sequence of actions follow a pattern associated with harmful content, or does it fit the structure of an educational demonstration?
Action recognition is computationally heavier than object detection, and it requires significantly more sophisticated training data. But it is the difference between a system that sees and a system that understands.
Stream 3: Text
Text inputs in video moderation come from multiple sources: on-screen captions, text overlays embedded in the video itself, titles, descriptions, hashtags, and comments. Each of these represents an additional signal about the content’s intent and context.
A video with an on-screen caption that explicitly frames violent footage as archival news material is a different moderation case than identical footage with no caption. A title that uses coded language associated with a known harmful community is a meaningful signal even if the video content itself appears neutral.
Text stream analysis connects these inputs to the audio and visual signals, looking for consistency or contradiction. When a video’s text signals and its audio-visual content are telling different stories, that discrepancy is itself a meaningful moderation signal.
Stream 4: Behavioral Metadata
This is the stream that most people do not think about when they think about content moderation, and it is one of the most powerful.
Behavioral metadata includes everything surrounding the content that is not the content itself: the creator’s publishing history and prior moderation record, the speed and pattern of engagement the content is receiving, the time and geographic distribution of that engagement, the network of accounts interacting with the content, and the platform context in which the content was published.
A piece of content that receives ten thousand views in two hours from a tightly clustered network of accounts with no prior engagement history is a different moderation case than identical content that accumulates the same views organically over a week. The content is the same. The behavioral context is entirely different.
Behavioral metadata allows the system to model not just what the content is, but how it is moving through the platform — and whether that movement pattern is consistent with organic audience behavior or coordinated distribution.
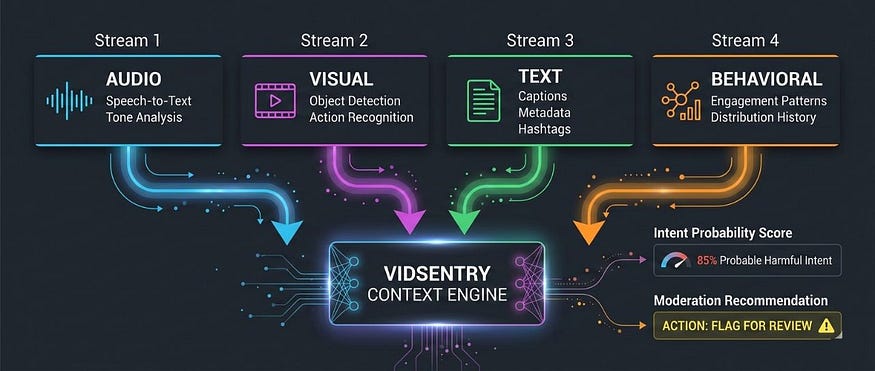
The Synthesis Layer: Where Multimodal AI Earns Its Name
Ingesting four input streams simultaneously is a significant engineering achievement. But the real power of multimodal AI is not in the ingestion. It is in the synthesis.
Each input stream produces its own set of signals and probability estimates. The audio stream might return a moderate-confidence flag on aggressive tone. The visual stream might identify an object associated with prohibited content. The text stream might show neutral caption language. The behavioral metadata might show completely normal distribution patterns.
In a unimodal system, the audio flag or the visual flag triggers enforcement. In a multimodal system, those signals are weighted against each other. The neutral text and normal behavioral context reduce the overall probability of harmful intent. The synthesis output reflects the full picture, not just the loudest individual signal.
This is the mechanism behind what we call intent modeling at VidSentry. The system is not asking “is this flagged signal present?” It is asking “given everything this system can observe about this content and its context, what is the most probable intent behind it?”
That is a fundamentally different question. And it produces fundamentally different answers.

Why My Thesis Work Shaped This Approach
My Honours thesis at UNISA focused on multimodal deep learning for pneumonia detection, using multiple imaging modalities simultaneously to improve diagnostic accuracy in medical AI.
The parallel to content moderation is not superficial. In medical diagnosis, a single imaging modality can detect the presence of an anomaly. What it struggles to determine, in isolation, is whether that anomaly is clinically significant, what caused it, and how it should be treated. The answer to those questions requires synthesizing multiple data streams (different imaging types, patient history, presenting symptoms, demographic context) into a unified clinical judgment.
Applying that same synthesis logic to video moderation was the intellectual leap that shaped VidSentry’s architecture. A keyword is an anomaly. An object is an anomaly. Neither is a diagnosis. The diagnosis requires context.
Medical AI that flags every chest shadow as potential pneumonia and treats accordingly would harm patients at scale. Content moderation AI that flags every contextual signal as potential harm and enforces accordingly is doing exactly the same thing to creators and platforms.
The engineering discipline required to build diagnostic AI that is both sensitive enough to catch genuine cases and specific enough to avoid false positives is precisely the discipline that content moderation has been missing.
What This Means for Platforms Building on Multimodal AI
If you are a platform operator or Trust & Safety leader evaluating AI moderation infrastructure, the practical implication of everything above is this: the question to ask any moderation vendor is not “what does your AI detect?” It is “how does your AI synthesize?”
Detection is the easy part. Every major moderation vendor can show you impressive object detection and keyword matching accuracy numbers. Those numbers tell you very little about real-world performance on the nuanced, edge-case content that actually drives your false positive rate and your creator churn.
Synthesis is where the performance gap between systems becomes visible. Ask how the system handles content where audio and visual signals are in conflict. Ask how it performs on code-switched speech. Ask how its false positive rate varies across creator demographics and content languages.
The answers to those questions will tell you more about a moderation system’s real-world fitness than any benchmark score on a curated test dataset.
The Plain-English Summary
Multimodal AI watches a video the way an informed, culturally aware human analyst would. It listens to what is being said and how it is being said. It watches what is happening across the full sequence of the video, not just a single frame. It reads the text signals surrounding the content. It considers the behavioral context in which the content is moving through the platform.
It synthesizes all of that into a judgment about intent.
That judgment is not always perfect. No system is. But it is categorically more accurate, more fair, and more defensible than a system that drops the hammer because a flagged word appeared or a knife was visible in a frame.
The technology exists. The engineering discipline to build it well exists. The only remaining question is whether the industry is ready to demand it.
At VidSentry, we are building for the platforms that already are.
Next in this series: Africa is home to over 2,000 languages. I will explain why that makes it the single greatest unsolved challenge in AI, and the single greatest opportunity for getting AI right.
Pride Chamisa is the founder of VidSentry, an AI-powered video moderation platform built to understand global context and African nuance. He writes about AI safety, multimodal machine learning, and the engineering behind context-aware content moderation.
Comments
Loading comments…