Enterprise adoption of LLMs is rapidly shifting from isolated applications to shared platforms orchestrating many agents, tools, and workloads simultaneously. Siloed deployments quickly become cost-prohibitive and operationally brittle, making multi-tenant orchestration platforms unavoidable.
Most platform designs prioritize functional correctness and latency SLAs. Throughput is sometimes considered when scaling pressure appears. Stability, however, is rarely treated as a primary design constraint — even though instability is often what ultimately limits usable scale.
In practice, multi-tenant LLM systems do not fail first due to incorrect outputs or latency violations. They fail when memory residency, batching efficiency, and bandwidth pressure interact in ways that degrade throughput long before latency alarms trigger.
This article explores how to design an enterprise multi-tenant LLM platform where stability is treated as a first-class architectural constraint rather than a secondary performance metric.
Formalizing Stability
Stability in a multi-tenant system is often conflated with availability. A system may exhibit near-perfect up-time while still failing to deliver consistent performance under realistic workloads.
A system is not unstable only when it crashes or rejects traffic. It becomes unstable when it can no longer sustain useful work efficiently even while remaining operational.
In simple terms:
Availability answers whether the system responds.
Stability answers whether the system’s response remains bounded within its operational constraints — latency per unit work, throughput, efficiency, and correctness — under sustained multi-tenant load.
Instability in LLM Platforms
Instability in LLM platforms primarily arises because of the nature of the transformer architecture and multi-tenancy of the serving platform:
- KV cache memory grows linearly with context length. Attention compute cost grows approximately O(n²) in vanilla transformers. The requirement is amplified by the number of sessions
- Longer contexts increase KV cache residency and per-token decode cost. Longer contexts increase KV cache residency and per-token decode cost, which reduces the effective throughput of the system.
- Latency bounds are typically violated indirectly: throughput degradation reduces effective service rate, which amplifies queuing delay.
- GPUs are efficient in batch processing. When a tenant submits longer contexts, or multiple concurrent sessions or larger generation lengths, then small context users are delayed behind long-context users, High Priority tenants are starved and Long-running sessions dominate decode bandwidth.
These instabilities manifest within the inference runtime, but platform architecture determines whether they are amplified or contained.
These failure modes are not independent. Memory pressure reduces batching flexibility, degraded batching lowers effective throughput, reduced throughput amplifies queueing delay, and queue growth eventually appears as latency and fairness violations. The role of platform architecture is not to eliminate runtime instability entirely, but to sense it early and shape demand so the inference runtime remains within a stable operating region.
Architecting Stable LLM Platforms
Architectural Levers:
Run-time levers — Length bucketing, Token-budget scheduling, priority-queues, weighted fair-queuing, Decode step caps per session, Early truncation under overload. The Run-time levers are mostly available for the Inference servers that serve the model Ex: Triton.
Platform-Level levers — Per-Tenant concurrency quota, Per-tenant token budgets, Context length Caps, Separate long-context protocol, Priority tiers (SLA Classes), sticky routing. These are the options
Strategies to stabilize multi-tenant LLM platforms:
- Cap concurrent long-context sessions
- Separate long-context pool
- KV eviction of idle sessions
- Sliding-window attention
- Context compression
- Early summarization
- Token-budget scheduling
- Disaggregate prefill/decode
This transitions naturally into, Stability is not just about memory capacity, but about sustained bandwidth under multi-tenant load.
Platform Design — High Level Architecture
Press enter or click to view image in full size
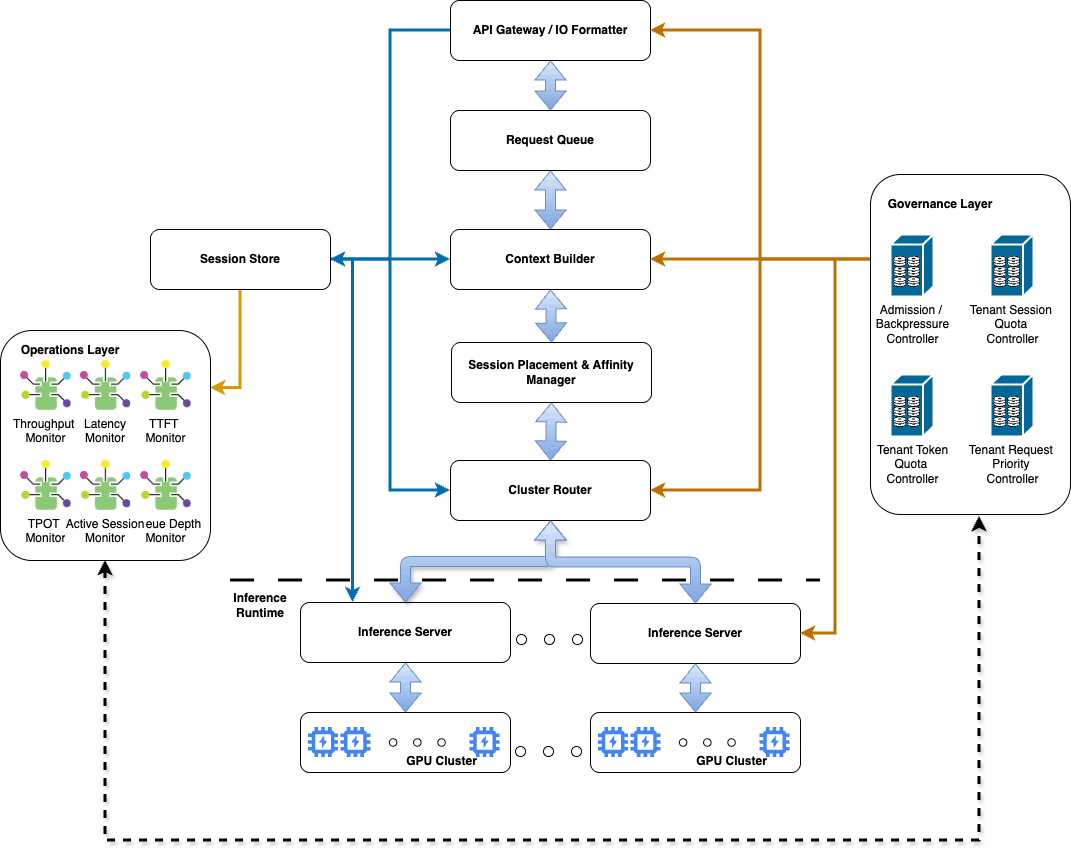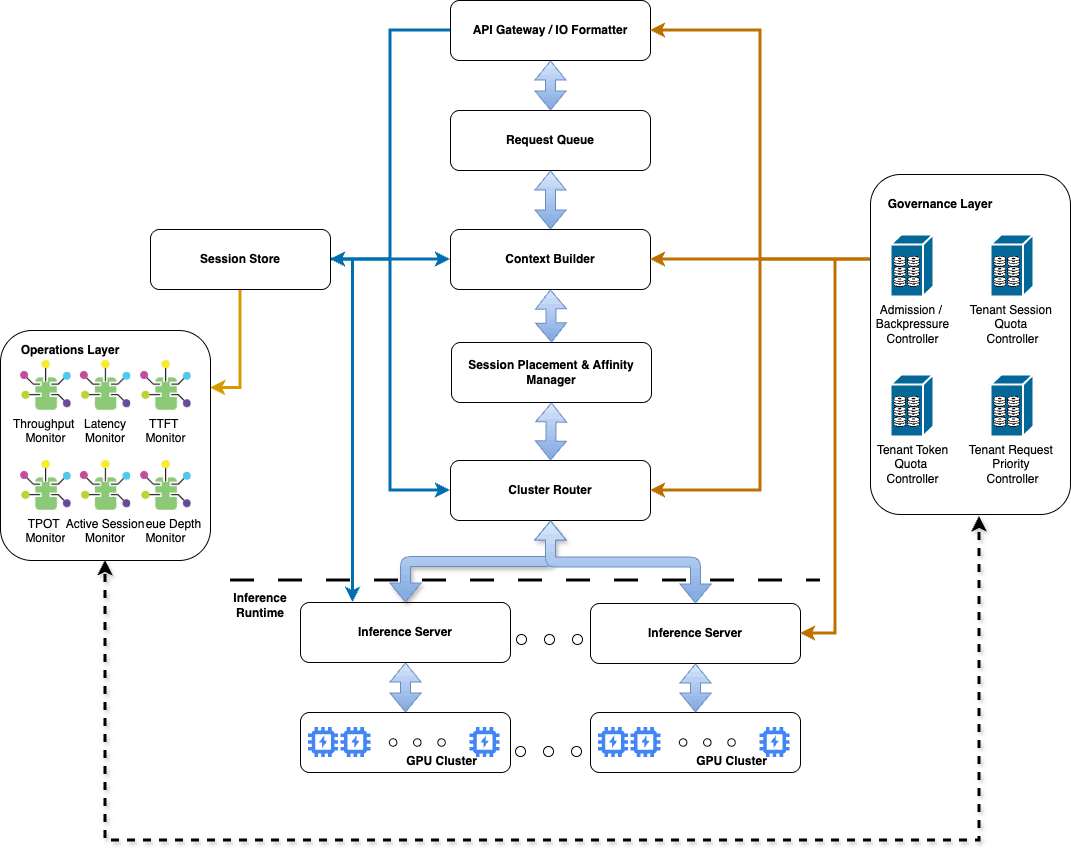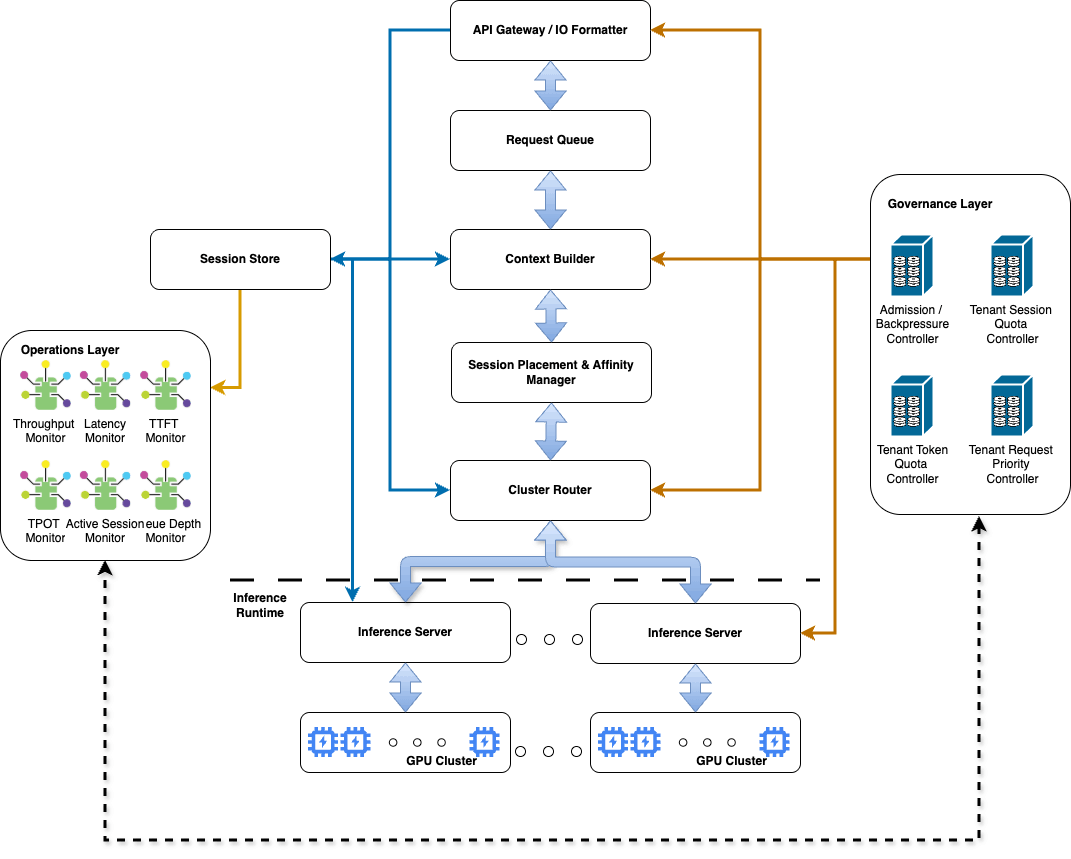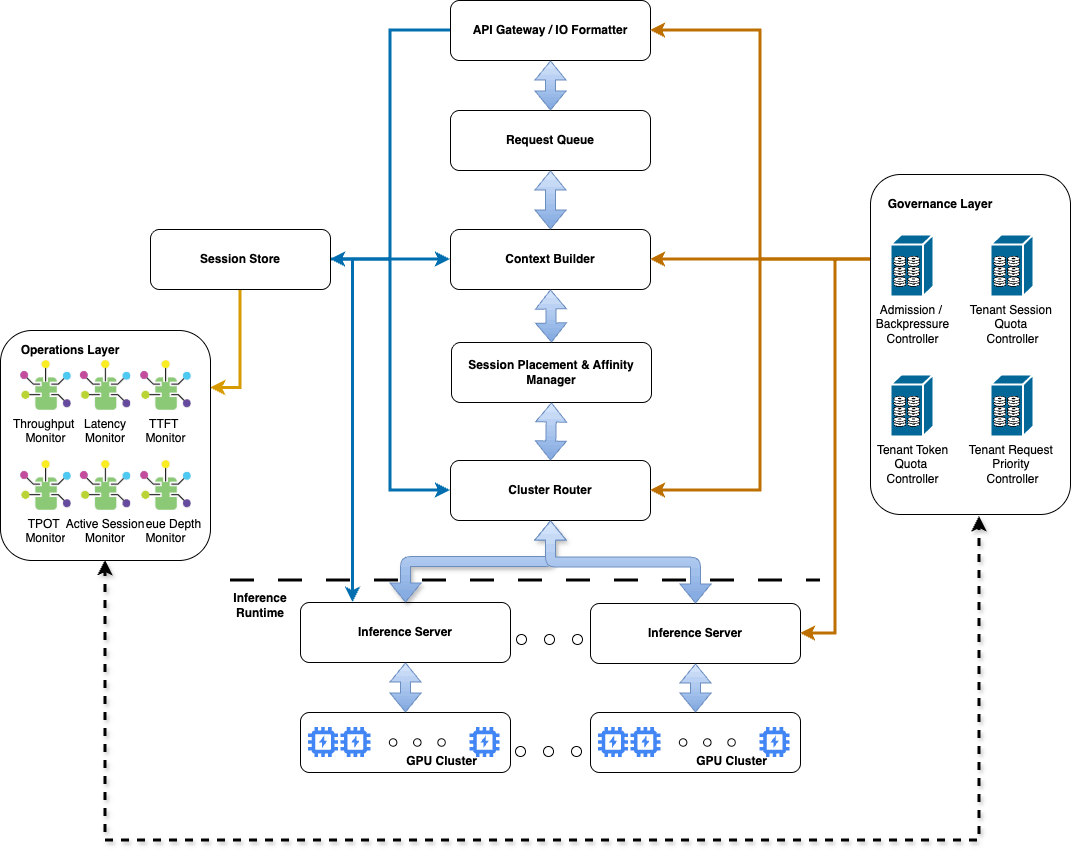
Operations Layer — This layer focus on monitoring the throughput, latency, Time to First Token (TTFT), etc. Since, the objective of the platform is to be stable, the operations layer is not just concerned with monitoring the different levers but also communicate the same to the Governance layer.
Governance Layer — This layer focus on enforcing the token limits, priority of the requests, session control and admission control. To ensure stability, these cannot be static parameters but dynamic. The input from the Operations Layer would help the Governance Layer modify its thresholds in a way that optimizes Stability, Availability and Resource Optimization — an dynamic optimization problem.
API Gateway/IO Formatter — This layer is pretty much the first layer and the layer that user directly interact with. This layers provides the necessary interface as well as basic formatting for the subsequent layers.
Context Builder — As mentioned before, different context lengths will affect the batching process, resulting in performance degradation. In these cases, the shorter contexts are usually padded. However, it is also possible to normalize or compress the prompt to make consistent context length as much as possible. If long contexts are a long tail distribution, then this layer would try to compress/reformat the query to within the acceptable context length
Request Queue — This module is responsible for traffic smoothing, priority scheduling, backpressure and burst absorption. This may be implemented using an in-memory or streaming queue depending on latency and durability requirements.
Session Placement and Affinity Manager — This module is responsible for preventing degradation by session to shard mapping, affinity preservation, controlled redistribution and warm state preservation. Requests from the same session should preferentially map to the same shard to preserve warm execution state and minimize repeated prefill and KV reconstruction. However, this not always possible and occasionally redistribution of sessions is needed and this module efficiently manages this placement. For better efficacy, this module tracks sessions (session_id), tenants (tenant_id), last_active_time, preferred_shard, context_length_estimate, priority, etc.
Cluster Router — This is module, that routes it to the different available run-time servers and also communicates the information to the Session Placement and Affinity Manager to enable it maintain session affinity.
Platform Design — Trade-Offs:
Some of the trade-offs of the design are as follows:
- This architecture is optimized for multi-tenant inference serving, not for large scale model training
- The system focuses on stability and consequently, it may be conservative in the number of the sessions, tenants, and contexts. As a consequence, the system may provide a better tenant isolation and routing
- The design does not optimize exclusively for minimum latency. Instead, latency is treated as an early signal of system instability.
- The system tries to preserver locality and consequently may not provide the best load balancing.
- The system is expected to overcome noisy neighbour issues, improves SLA and fairness but reject or throttle work even when the system is not fully exhausted
- The system also focuses on fairness and thereby may provide predictable service but may not be maximizing throughput
Comments
Loading comments…