The same system that failed your users on Tuesday passed every test on Monday. The model hadn’t changed. The prompts were identical. And yet something was clearly, reliably wrong. This is not bad luck. It’s a design problem! 🤔
I’ve been spending some time on this exact problem across the agentic systems. The design is almost always the same. However, the failure doesn’t start with the LLM. It starts with what gets fed to the LLM and what happens to the outputs afterward.
The root cause isn’t probabilistic decay or model fragility. The problem is that we build AI Systems by following the traditional practices we use for deterministic software. And those assumptions are quietly killing us in production.
Why “Tests Passed!” Means Nothing Now
The green checkmark is not lying to you. It’s just answering a different question than you think.
LLMs behave non-deterministically by nature, meaning that the same prompt, run twice, can take two different reasoning paths to two different conclusions. Your test suite runs it once, sees something reasonable, and marks it passing. What it never sees is the second run. Or the fifth. Or, as it sounds crazy, the one that happens at 2 AM in production when the context window looks slightly different.
What I see as the deeper problem is the architecture. Treating evaluation as a final gate — does this output look right? — made sense for deterministic systems. For multi-step agents where outputs become inputs, it’s like checking the last domino and ignoring the chain.
What you actually need is structural validation at every layer of the pipeline, before outputs become inputs, as follows;
Deterministic Testing → Output Evaluation → Trajectory Observability
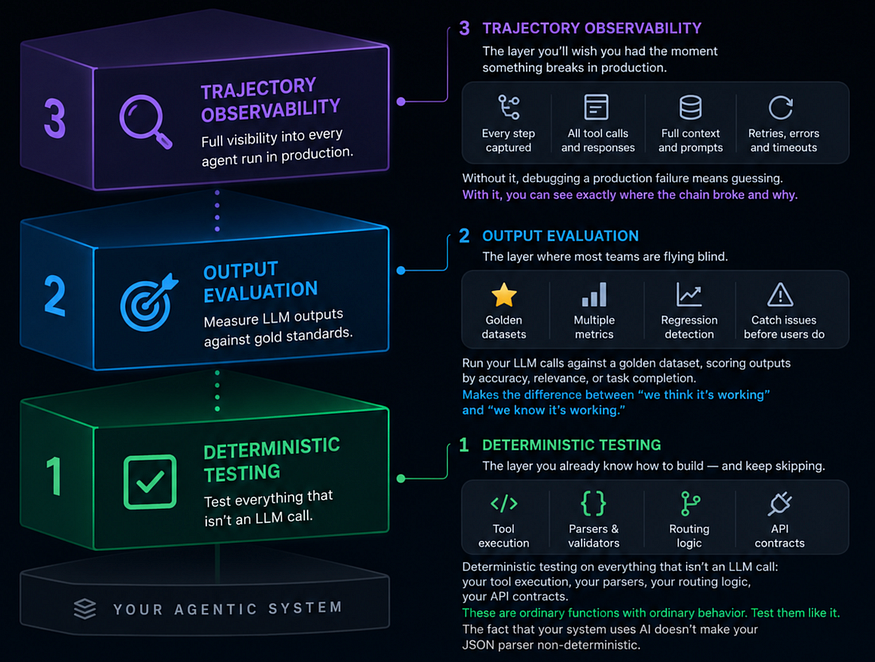
The context window is your most risky dependency
In a multi-agent system, agents communicate by passing context. This is so fundamental it barely gets mentioned, which is exactly why its failure mode goes unnoticed. Bad context compounds. If Agent A produces a subtly incorrect intermediate result and Agent B receives it as ground truth, Agent B’s output will be confidently wrong in a way that’s almost impossible to trace back to the source.
By the time a human notices the problem, three agents have already conditioned on a false premise. The logs show no error. The model performed as intended. But the system failed because the pipeline had no opinion about what was flowing through it.
We all know that pain! So, three practices that address this directly:
1- Validate intermediate outputs before passing them downstream. Not with assert statements, with a schema check, a structured output parser, or a lightweight LLM-as-judge call. If Agent A is supposed to return a JSON object with five required fields, verify that before Agent B sees it. This sounds obvious. Almost nobody does it consistently.
2- Summarize, don’t append. Long agentic workflows that keep growing the context window hit two problems simultaneously: the model’s effective attention on earlier content degrades, and you’re paying for tokens that add noise rather than signal. Compress completed stages into a structured summary before passing forward.
3- Inject known facts as periodic sanity checks. For long-running agents, periodically inject a verifiable fact — a date you control, a value you know — and check whether the agent’s subsequent outputs remain consistent with it. It sounds simple. It catches drift that no other technique reliably surfaces.
None of this requires understanding information theory. It requires treating your agent as a data pipeline and understanding that pipelines degrade when you don’t validate what flows through them.
Your Model Already Knows When It’s Guessing
Here’s something many teams overlook: modern LLMs expose uncertainty signals that can sometimes correlate with unreliable outputs.
Some APIs expose this through log probabilities, token confidence distributions, or related scoring signals. When a model hesitates around a date, a name, a tool selection, or a critical number, that uncertainty can sometimes appear in the generation patterns before the error reaches your users.
These signals are not perfect confidence estimates. Models can still hallucinate confidently. But, when treated carefully, they can become useful operational indicators within a larger reliability system.
You don’t need a statistics degree to use them. The pattern is simple:
- identify the outputs that matter most,
- monitor uncertainty around them,
- and route ambiguous cases differently.
High-confidence outputs may continue normally. Lower-confidence outputs can be:
- retried with tighter constraints,
- validated through secondary checks,
- routed to humans, or
- logged for evaluation.
This is where the paradox resolves: the model isn’t broken, and neither are our prompts. What’s missing is the architectural layer that decides how uncertain outputs should be handled before downstream systems treat them as truth.
The Tooling That Exists Right Now
You don’t have to build this infrastructure from scratch. The ecosystem has caught up faster than most people realize.
Braintrust is the closest thing the industry has to a proper test suite for non-deterministic outputs, eval datasets, LLM-as-judge scoring, and regression tracking in one place. If you’re serious about output quality over time, start here.
LangFuse is open-source observability for LLM applications. It gives you full agent trajectory visibility, every tool call, every context window, every retry with minimal instrumentation. You can’t fix what you can’t see.
PromptFoo lives in your CI pipeline. CLI-first, fast, and built for engineers who want prompt regression testing to feel like any other automated test. Parallel seed execution, semantic similarity scoring, no dashboard required.
RAGAS is purpose-built for RAG pipelines specifically, measuring faithfulness, answer relevance, and context recall as independent signals rather than a single blended score. If retrieval is part of your architecture, this belongs in your stack.
LangSmith rounds out the observability side, tracing, debugging, and dataset management, with enough adoption that your team has probably already heard of it.
Start Trusting Your Architecture over Your Model
The engineers making the most impact on agentic systems right now are not the ones writing the cleverest prompts. They’re the ones who have made one fundamental mental shift: they treat LLM outputs as untrusted signals, such as incoming API data from a third-party service where you don’t know what’s on the other side, so you validate the schema, check the values, and handle the edge cases before anything downstream sees it.
If you think of it as a pipeline processing uncertain data, you build differently. You validate at boundaries. You observe trajectories. You design fallback paths for the responses that land in the ambiguous middle.
Reliability is not a property of the model.It’s a property of the system you build around it.
The failure mode isn’t the LLM. The LLM is doing exactly what it was trained to do. The failure is the assumption that a capable model is sufficient for a reliable system.
It isn’t. That’s the paradox. And yes, you know what you’ll build now 🚀
If you’re building production agentic systems, I’d like to hear what failure modes you’ve encountered that aren’t covered here. Feel free to drop it in the comments 😊
Comments
Loading comments…