Software defects are not a minor inconvenience; they are a quantified, escalating business liability. According to the Consortium for Information & Software Quality (CISQ), poor software quality costs U.S. organizations $2.41 trillion in 2022 alone.
Yet despite sky-high stakes, most QA teams are still operating with the same manual, reactive test creation processes built for a 1990s SDLC. The result? A widening gap between software complexity and test coverage that grows more dangerous with every sprint.
- The global cost of poor software quality reached $2.41 trillion in 2022, according to CISQ.
- Manual QA achieves an average defect detection rate of only 75%, meaning roughly 1 in 4 bugs goes undetected before release.
- QA engineers spend up to 40% of their total effort simply writing test cases, time that could otherwise go toward strategy and exploratory testing (Gartner).
- 63% of Agile teams report a perpetual regression test backlog, a sign that test creation is consistently outpaced by development velocity (Capgemini).
- A defect caught post-release costs 15–30x more to fix than one identified during development, making early detection a direct financial priority (IBM).
The core problem is not a lack of effort. It is a structural mismatch. Modern applications are microservice architectures with thousands of interdependencies, dynamic user flows, and continuous deployments. Manual testers, no matter how skilled, cannot generate, maintain, and execute test suites at the speed and precision that these systems demand. Something must change. That something is how test cases are born. For organizations facing these challenges, partnering with experienced QA providers like Kualitatem can help bridge the gap between growing software complexity and effective test coverage without overhauling your entire QA process.
The Rise of AI-Driven Test Case Generation
AI-powered test generation is not only a trend it is a structural response to structural failure. By applying machine learning to code repositories, application logs, past test outcomes, and requirement descriptions, AI tools can do what no human team can: analyze the entire state space of an application and synthesize test scenarios probabilistically ranked by risk.
How the AI Generation Engine Works
1. Neural Network Code Path Analysis: scans the code repository and isolates recent delta changes, mapping them to historical defect zones.
2. Probabilistic Risk Modeling: builds defect probability scores for every module, factoring in change frequency, coupling, and past failure rates.
3. Behavioral Pattern Recognition: extracts dominant and edge-case user flows from application logs and session recordings.
4. Dynamic Test Scenario Adaptation: re-ranks and expands test suites in real time as code changes are pushed so, so no static regression library is needed.
Market Signal
The global AI in software testing market was valued at $1.42 billion in 2023 and is projected to reach $12.77 billion by 2032, with a CAGR of 27.7% (Allied Market Research). Adoption is no longer early-stage; it is entering the mainstream enterprise phase.
The Risks You Cannot Afford to Ignore
Before committing budget and roadmap to AI-driven testing, QA leaders and CTO offices must candidly assess both major and minor risk categories. Uncritical adoption is as dangerous as no adoption.
Major Risks
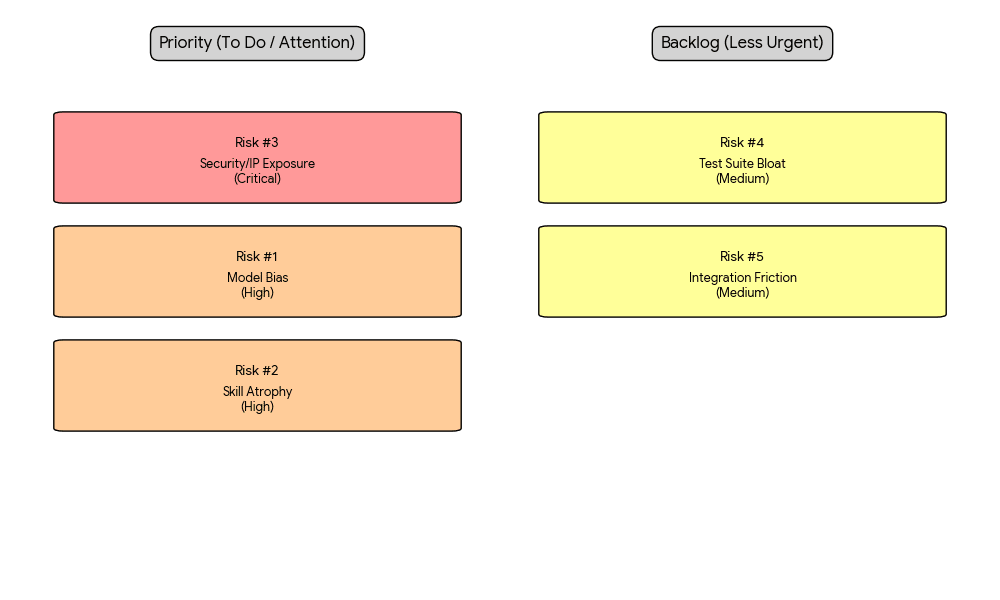
Risk #1: Model Bias and Training Data Poisoning
AI test generation models learn from historical test data and defect logs. If those datasets are imbalanced, reflecting, for instance, a team that historically under-tested payment flows or accessibility paths, the AI will perpetuate and amplify those gaps.
A 2023 study by Accenture found that 41% of AI-assisted QA teams reported that the AI prioritized test areas already well-covered, creating a 'rich get richer' coverage dynamic.
Risk level: HIGH directly impacts test coverage quality and release confidence.
Risk # 2: Over-Reliance Leading to Skill Atrophy
As AI handles test generation, human QA engineers may progressively lose the analytical skills required to design complex exploratory tests.
Risk level: HIGH, a long-term organizational and talent risk.
Risk 3: Security and IP Exposure via External Model APIs
Many AI testing tools call external LLM APIs to process code repositories and requirement documents. This exposes potentially proprietary business logic, architecture diagrams, and unreleased feature specifications to third-party model providers.
Risk level: CRITICAL for regulated industries (fintech, healthtech, defense).
Minor Risks
Risk 4: Test Suite Bloat and Maintenance Overhead
AI models, left unconstrained, generate test cases at volume. Without governance guardrails, a QA team can quickly accumulate thousands of AI-generated tests many of which overlap, contradict deprecated features, or address implausible edge cases.
Risk level: MEDIUM manageable with defined pruning policies.
Risk 5: Integration Friction with Legacy CI/CD Pipelines
Most AI testing platforms are built for modern cloud-native stacks. Enterprises with on-premise Jenkins instances, legacy SOAP services, or mainframe-adjacent systems frequently encounter significant integration friction, requiring custom connectors or middleware layers that erode the productivity gains.
Risk level: MEDIUM, primarily a technical debt issue.
Case Example: Goldman Sachs and Risk-Priority Testing
Goldman Sachs engineering teams have publicly discussed their approach to applying machine learning to prioritize which code paths carry the highest financial and reputational risk effectively treating test allocation the same way their analysts treat portfolio risk management: deploy capital (testing effort) where the probability weighted loss is highest.
In their model, an AI layer continuously analyzes transaction processing code changes, correlates them against historical incident data, and surfaces a ranked list of test scenarios before each release. The outcome: a reported 40% reduction in production incidents tied to transaction edge case failures, while simultaneously reducing regression suite execution time by 35% through smarter test selection.
"Key Lesson for LeadersGoldman Sachs did not deploy AI testing to replace QA they deployed it to make QA decisions with the same rigor applied to their financial risk models. The strategic insight: treat every release as a portfolio of risk, and let AI be the quant analyst that prices each test's expected value"
If you're looking to implement this roadmap efficiently, AI testing services can help you launch pilots, build reliable data foundations, and scale with measurable outcomes.
Strategic Framework for AI-Driven QA Transformation
For enterprise technology leaders, the path forward is not simply the procurement of an AI testing tool. It is a strategic transformation of the QA function across people, process, and technology dimensions.
Strategy 1: Build a Testing Data Flywheel
AI models improve with data. The first business priority is establishing a structured data pipeline: capture every test execution, defect log, and resolution outcome in a normalized schema. This testing data flywheel where each release cycle enriches the AI's training context is your most defensible competitive moat. Organizations that start this data collection discipline today will have AI models that are meaningfully more accurate in 18 months than those that begin data collection later.
• Instrument CI/CD pipelines to log test results with metadata: code module, author, change type, defect severity.
• Standardize defect taxonomy across all squads. Consistent labeling is the prerequisite for high-quality model training.
• Establish a 'testing data governance' role within the QA leadership team.
Strategy 2: Adopt a Human-in-the-Loop (HITL) Governance Model
To counter skill atrophy and model bias risks, do not implement AI test generation as a fully autonomous system. Instead, deploy a Human-in-the-Loop model where AI generates candidate test suites and senior QA engineers perform structured review, pruning, and augmentation.
• AI generates test candidates ranked by risk score.
• QA lead reviews the top 20% of high-risk cases and all edge-case scenarios.
• Human team approves, modifies, or rejects generated tests with rationale logged; this feedback loops back into model retraining.
• Junior QA engineers rotate through AI output review as a structured learning exercise, maintaining skill currency.
Strategy 3: Segment Tooling by Regulatory Risk Profile
Not all codebases carry equal data sensitivity. B2B organizations should implement a tiered tooling policy: use cloud-based AI testing APIs for internal tools and non-sensitive product areas; deploy on-premise or private-cloud AI models for code repositories containing PII, financial transaction logic, or regulated health data. This segmentation approach resolves the IP and security exposure risk without prohibiting AI adoption across the board. AI-generated test cases can be imported into Kualitee, where QA leads review, approve, or modify them. This ensures a controlled Human-in-the-Loop process while keeping all test artifacts organized
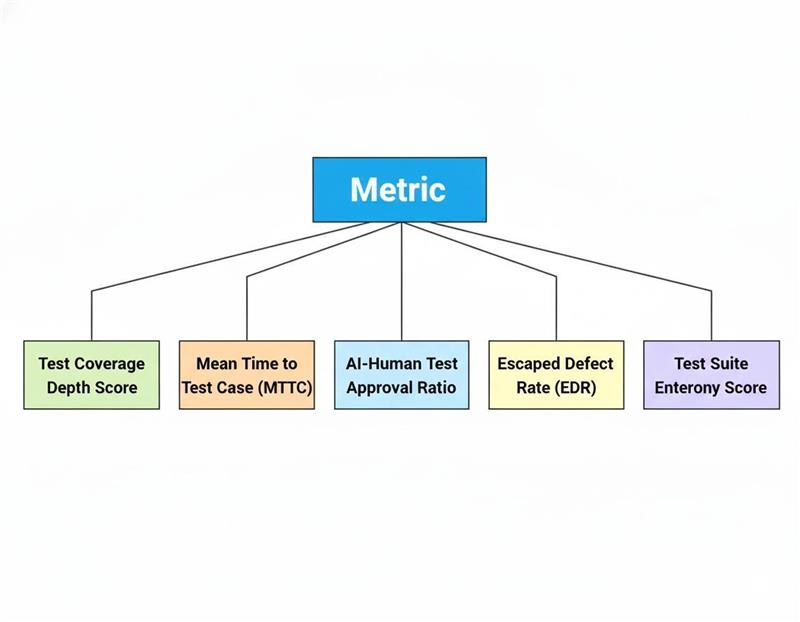
Strategy 4: Redefine QA KPIs Around AI-Augmented Outcomes
Traditional QA metrics, such as defect count and pass/fail rate, are insufficient to capture the value of AI-driven testing. B2B leaders should adopt a new KPI framework that measures outcomes relevant to AI-augmented QA:
,
Strategy 5: Vendor Partnership vs. Build Decision Framework
For most B2B organizations with fewer than 50 QA engineers, vendor partnerships with platforms such as Testim, Functionize, mabl, or Applitools offer faster time-to-value than internal builds. For organizations above this threshold, particularly those in fintech, healthtech, or defense, a hybrid model (commercial platform for standard testing, proprietary ML models for risk-classification) provides both speed and competitive control.
How to Get Started: A Simple 5-Step Roadmap
If you're a QA leader or tech director and want to start using AI in testing, you don’t need to change everything at once. Follow this practical, low-risk approach.
Step 1: Review Your Current Test Data (Weeks 1–2)
Before buying any AI tools, first understand what you already have. Look at your existing:
- Test cases
- Bug reports
- Test execution history
Find gaps where are you not testing enough? (e.g., certain user flows or sensitive data areas). This will be your starting point to measure improvement.
Step 2: Start with a Small Pilot (Weeks 2–4)
Don’t roll this out across the whole company. Start small.
Pick:
- One product area
- Medium complexity
- A team open to experimenting
Set a clear goal, like: “Improve edge-case test coverage in checkout by 30% in 60 days.”
Step 3: Prepare Your Data First (Weeks 3–6)
Before using AI, make sure your data is clean and structured.
- Add proper logging to test executions
- Label your test data clearly
- Collect at least 4–6 weeks of good data
Skipping this step is one of the biggest reasons AI pilots fail.
Step 4: Use AI with Human Review (Weeks 6–10)
Now start generating test cases using AI, but don’t trust it blindly.
- Every AI-generated test should be reviewed by a QA lead
- Only approved tests go into your regression suite
Track how many AI tests get approved. In most cases, approval rates reach 70–80% within a few weeks.
Step 5: Measure Results and Decide Next Steps (Weeks 10–12)
At the end of the pilot, evaluate the results:
- Did test coverage improve?
- Did you save time?
- Did defect detection improve?
- Is the team happy with the process?
Use this data to decide:
- Scale up AI testing
- Or pause and improve your approach
Final Strategic Insight
The QA teams that will define competitive advantage over the next five years are not those with the most testers but those who treat test generation as a data science problem. AI does not replace the QA professional; it elevates them from case writer to risk architect. The organizations that make that transition deliberately, with proper governance and data discipline, will ship faster, break less, and cost significantly less to operate.
Comments
Loading comments…