Introduction
Scraping pipelines are running at a higher frequency now, with tighter refresh cycles and lower tolerance for failure. At the same time, anti-bot systems have improved. Detection is layered, rate limits are stricter, and simple workarounds no longer hold.
Most teams adapt by extending the stack. An anti-bot solution handles detection signals and CAPTCHA challenges, a proxy network manages IP rotation and geo targeting, browser infrastructure renders JavaScript-heavy pages, a SERP API returns structured search data, and a data formatter normalizes output for downstream use.
Together, they form the core of a web scraping infrastructure stack. The issues show up in production, where these components run independently with different retry logic, timeouts, and failure conditions.
A request can pass one layer and fail at the next, and tracing that path across vendors means stitching logs across separate dashboards with no shared request ID. It can be harder to manage when combined, leaving you maintaining five tools for one job due to architectural complexity.
In this article, we will look at how that failure shows up across the pipeline and what a more reliable approach looks like.
The Typical Web Scraping Pipeline Architecture
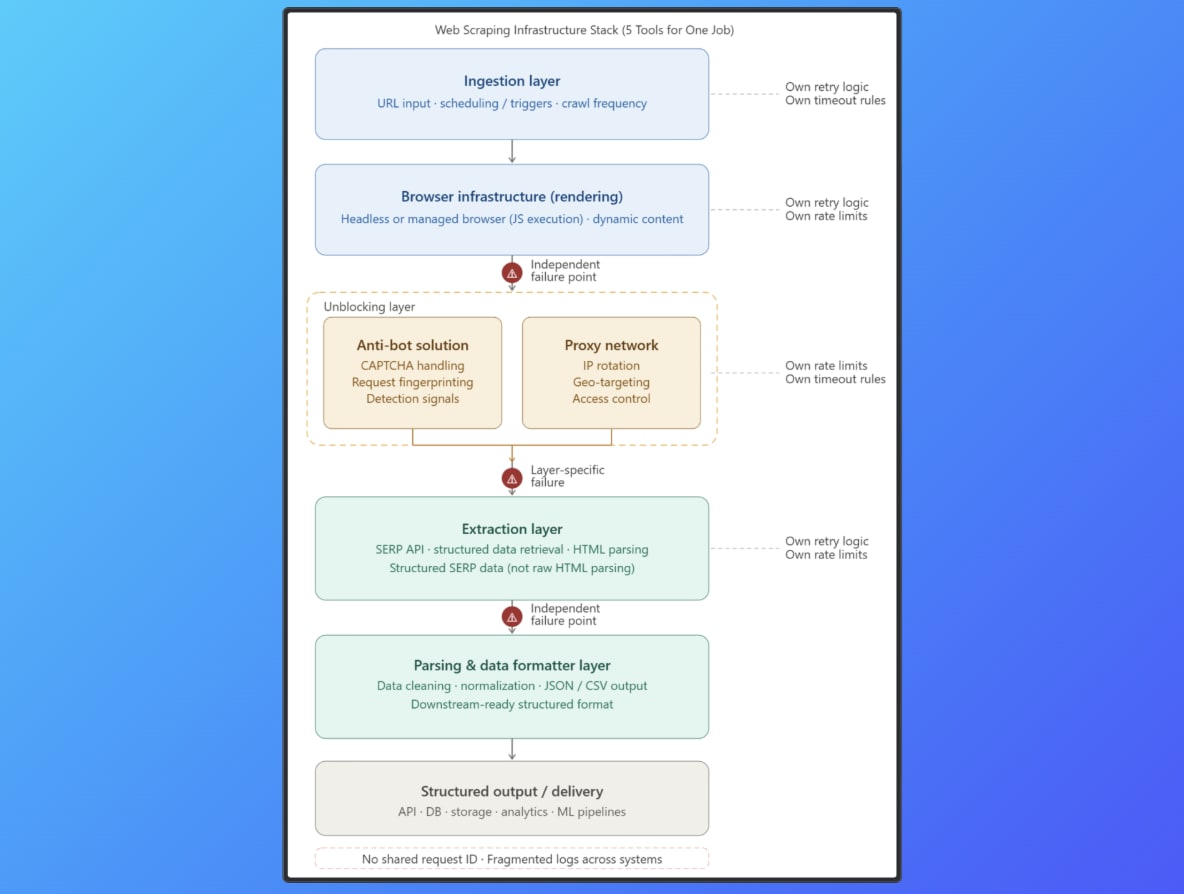
A standard web scraping pipeline architecture follows a predictable flow. It starts with ingestion, where target URLs are defined, scheduled, and triggered based on crawl frequency or events.
Next comes rendering through browser infrastructure. This layer uses headless or managed browsers to execute JavaScript and load dynamic content that simple HTTP requests cannot access.
Once content loads, unblocking handles access control. An anti-bot solution works with a proxy network to manage IP rotation, apply geo targeting, and deal with CAPTCHA challenges or detection signals.
After access is secured, extraction begins. A SERP API is often used here for search engine data, returning structured results such as rankings, URLs, and metadata instead of raw HTML. Finally, parsing and delivery prepare the output. A data formatter cleans, normalizes, and converts data into structured formats like JSON or CSV for downstream use.
Each layer addresses a specific need in the web scraping infrastructure stack. The complexity comes from how these layers interact and depend on each other during execution.
Where the Stack Breaks
Failures follow from how the pipeline is wired. Each component runs with its own retry policy, timeout window, and rate limits, and requests move across layers without shared state, so behavior diverges as soon as conditions change.
For example, a proxy request can succeed while the browser fails to render. A page can render correctly but still get blocked by anti-bot checks. A SERP API call can return incomplete data under throttling. A parser can fail when the DOM structure changes slightly.
Failure does not occur at a single point, which makes debugging harder. Logs sit across different dashboards, with no shared request ID or trace, so you end up correlating events across systems just to understand what happened to one request.
This fragmentation carries into operations, where onboarding, billing, and vendor dependencies start to slow down changes across the pipeline.
The Hidden Costs of a Multi-Tool Stack
A multi-tool stack increases operational overhead across setup, cost tracking, dependency management, and stability. Here are a few hidden costs:
- Onboarding overhead: Each tool comes with its own API design, SDK behavior, and authentication flow. You spend time wiring these together before you can even test data output. Every new addition extends setup time and increases the effort needed to understand how requests move through the stack.
- Billing complexity: Costs are split across models. One service charges per request, another by bandwidth, and another by successful responses. Mapping this to a single cost per usable dataset is difficult, so forecasting becomes guesswork.
- Vendor dependency: When one provider slows down or enforces stricter limits, the entire pipeline is affected. Replacing that component is not simple, since each layer is tightly integrated with the rest of the flow.
- Operational failure surface: Every integration introduces another point that needs monitoring. Stability depends on how well these independent systems behave together under load.
At this stage, you are maintaining a distributed system across vendors, not just running a scraper.
Designing a Unified Web Scraping Infrastructure Stack
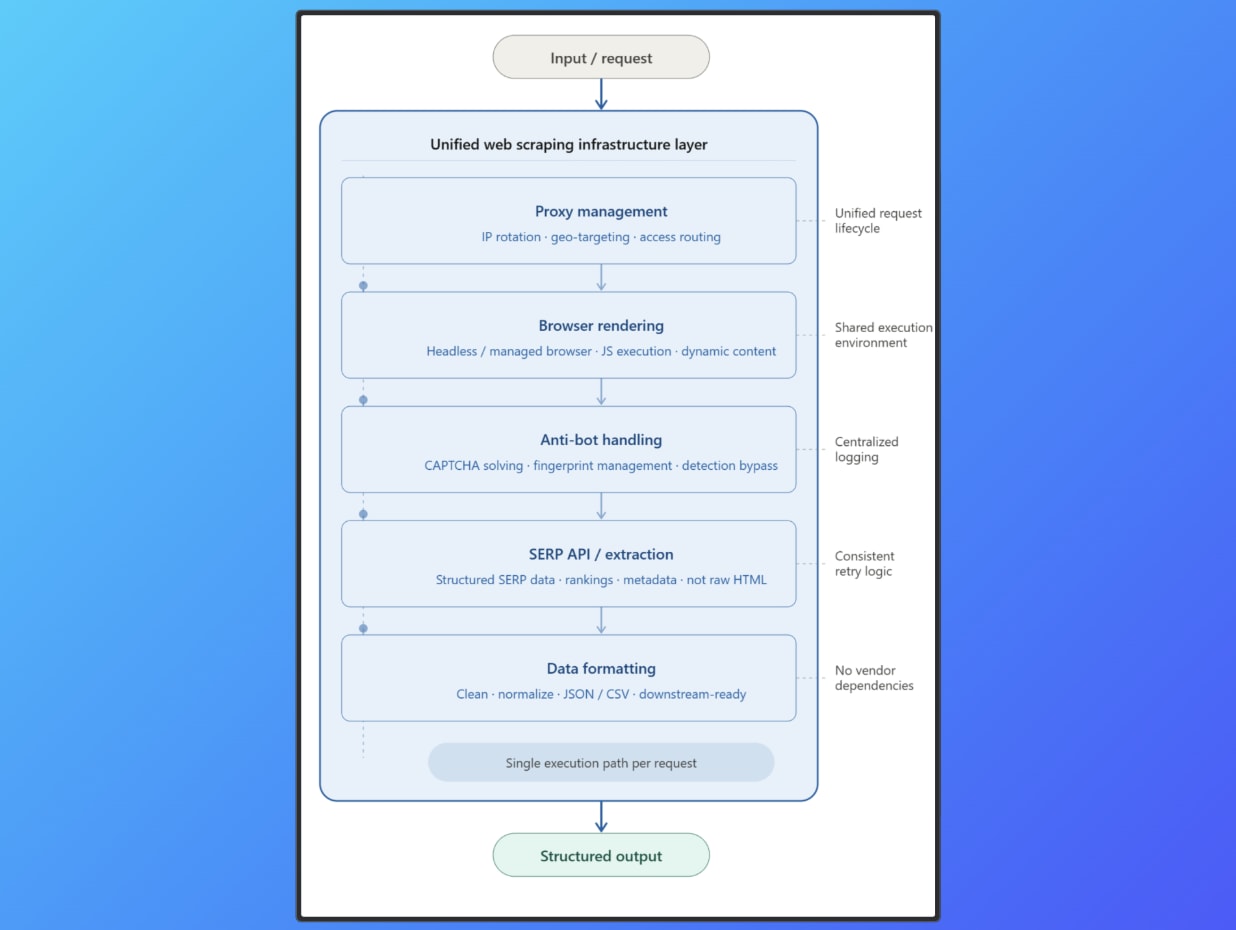
By using a unified architecture, you can reduce coordination issues by consolidating core scraping functions into a single execution layer. Here are the core functions that this unified layer supports:
- Proxy management scraping ensures IP rotation and geo targeting are applied consistently at the request level.
- Browser rendering executes JavaScript through managed browser environments to handle dynamic content.
- Anti-bot handling integrates detection bypass and CAPTCHA resolution directly into request execution.
- SERP API browser automation returns structured data from search engines without relying on raw HTML parsing.
- Structured data delivery normalizes and outputs data in formats ready for downstream systems.
All functions operate within the same execution environment, so request flow remains consistent without needing external coordination between layers.
How Bright Data Unifies the Web Scraping Infrastructure Stack
A unified scraping stack changes how requests are executed by keeping routing, rendering, and extraction within the same system instead of distributing them across external services.
Bright Data provides this as an all-in-one web scraping solution, where each layer operates within shared infrastructure rather than as separate services.
Here is how the components map in your infrastructure:
- Web Unlocker manages anti-bot handling at the request level by applying fingerprinting, header control, and CAPTCHA resolution as part of the same execution flow, rather than as a separate pre-processing step.
- Residential Proxies handle proxy management scraping by dynamically assigning IPs with geo targeting during request execution, without requiring external proxy rotation logic.
- Scraping Browser runs rendering within a managed browser environment where session state, cookies, and execution context persist across interactions, removing the need to maintain headless infrastructure.
- SERP API provides structured search engine data directly, so extraction does not depend on parsing unstable HTML responses or managing search-specific blocking patterns.
- Web Scraper IDE acts as the orchestration layer, where request logic, parsing rules, and execution flows are defined and run within the same system.
Since these components run on shared infrastructure, you can get consistent request handling and unified execution.
What You Gain from a Unified Scraping Infrastructure
A unified scraping stack gives you consistent execution, measurable performance, and predictable cost at the request level.
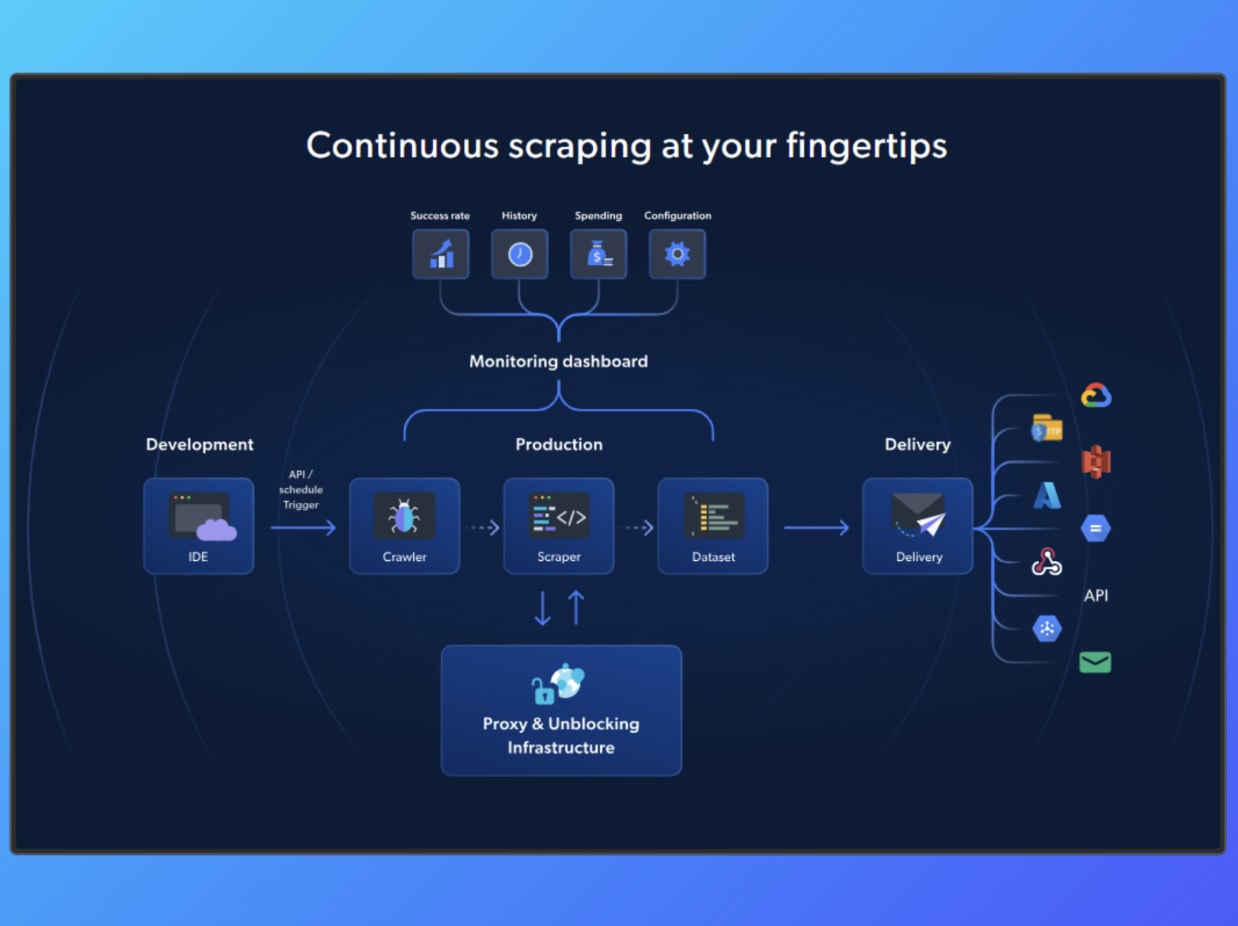
With Bright Data, a single request can pass through Web Unlocker for anti-bot handling, route via Residential Proxies for geo targeting, execute in the Scraping Browser for rendering, and return structured output through the SERP API or scraping workflow, all within one execution path.
For example, when tracking product prices across multiple e-commerce sites, location targeting, page rendering, and extraction stay aligned within the same request, which reduces mismatches and incomplete records.
In benchmarks, Bright Data achieved an average success rate of 98.44% across protected domains, along with 99.99% uptime and 99.95% request success rates, which improves data reliability under load.
This setup lets you measure output against actual results, adjust workflows without reworking integrations, and run high-frequency data collection with fewer failed or partial responses.
Key Takeaways
Most scraping pipelines grow into five-tool stacks because each layer solves a real problem. But when you run them together, coordination becomes the bottleneck. You deal with separate retries, fragmented logs, and inconsistent behavior across layers. That slows debugging, increases cost, and makes the system harder to control.
A unified web scraping infrastructure stack simplifies this. You run proxy management, rendering, anti-bot handling, and data extraction within one system. Requests stay consistent, failures are easier to trace, and output becomes more reliable.
If you want stable pipelines and predictable results, start with the architecture. Try Bright Data to run your scraping workflows within a single infrastructure layer.
Comments
Loading comments…