A constant at the top of a file is still hardcoded, same for a config.py. Here’s what to do instead.
The staging deploy
You deploy to staging. The model fails to load. You grep the codebase:
# config.py
MODEL_PATH = "/models/v2"
DB_HOST = "localhost"
MAX_RETRIES = 3
Staging has v3. You change MODEL_PATH = "/models/v3", redeploy. It works. Two weeks later production needs v4. Same fix, same deploy. You have a config.py but you do not have a configuration … you have hardcoding you can find quickly.
By the end of this article, you will have a clear test for what counts as configuration, three correct places to put it, and a startup validation pattern that turns misconfiguration into a loud error rather than a silent runtime mystery.
What configuration actually is
Configuration is anything that changes between environments, runs, or deployments without requiring a code change or redeploy.
Apply the test:
DB_HOST = "localhost"changes between dev/staging/prod? Yes → configuration.MODEL_PATH = "/models/v2"changes when a new model is deployed? Yes → configuration.MAX_RETRIES = 3a policy decision that might be adjusted per deployment? Probably configuration.BATCH_SIZE = 32a tuning parameter that varies per run? Configuration (CLI arg). Never changes after the initial decision? Constant: fine in code.
Constants are decisions made once in the codebase. Configuration is decisions made outside the codebase, per deployment or per run, they are more about the environment you are setting them in. It’s not the same running a pod, a container, or testing on local.

Three anti-patterns
Python file as config: requires a code change to update, commits secrets to source control, cannot be overridden per environment (and probably a crawler will pick it up, please don’t use this one):
# config.py this is NOT configuration
API_KEY = "sk-hardcoded-secret-key" # committed to git
MODEL_PATH = "/models/v2" # requires redeploy to change
Magic strings scattered across modules, no single place to audit or change:
# pipeline.py
def load_model():
return load("/models/v2/classifier.pkl") # grep-only discoverability
Config mixed with logic: entangles environment decisions with business logic, makes testing require env var setup:
def connect():
host = "db.prod.example.com" if os.environ.get("ENV") == "prod" else "localhost"
return psycopg2.connect(host=host)
The antipatterns show that making changes becomes hardcoding you can find quickly, but they don’t let you mix and match configurations properly into different environments easily. Next, we have what to do instead.
The three correct homes
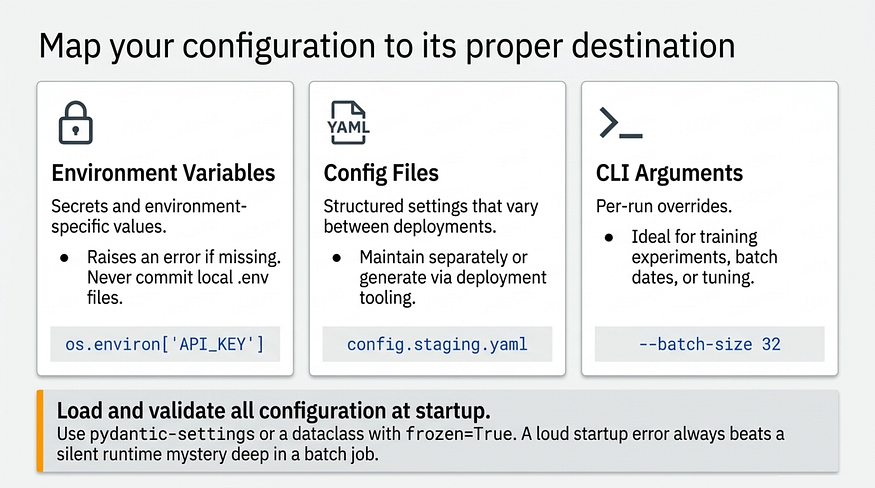
Environment variables: secrets and environment-specific values
import os
db_host = os.environ["DB_HOST"] # required — raises KeyError if missing
api_key = os.environ["API_KEY"]
model_path = os.environ.get("MODEL_PATH", "/models/default") # optional with default
# Set for demonstration:
os.environ["DB_HOST"] = "db.staging.example.com"
os.environ["API_KEY"] = "test-key"
print(os.environ["DB_HOST"])
print(os.environ.get("TIMEOUT", "30"))
Use os.environ["KEY"] for required values (raises KeyError immediately if missing) and os.environ.get("KEY", default) for optional ones.
Config files: structured settings that vary between deployments
import yaml
# In production, read from a file: yaml.safe_load(Path("config.yaml").read_text())
# Here we use an inline string for demonstration:
config_yaml = """
database:
host: db.staging.example.com
port: 5432
pipeline:
max_retries: 3
batch_size: 64
"""
config = yaml.safe_load(config_yaml)
print(config["database"]["host"])
print(config["pipeline"]["max_retries"])
Config files are the right home for structured, non-secret settings. You maintain config.staging.yaml and config.prod.yaml separately, or your deployment tooling generates them. You might use toml or json , I’d even accept xml files, just keep a config file structured and the api keys out of git, those are secrets you can configure in your Cloud provider or even in GitHub.
CLI arguments: per-run overrides
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", default="/models/default")
parser.add_argument("--batch-size", type=int, default=32)
# parse_args([]) uses defaults — omit [] in production to read from sys.argv
args = parser.parse_args([])
print(args.model_path, args.batch_size)
CLI arguments are the right home for per-run values: model paths for training experiments, date ranges for batch jobs, batch sizes for tuning.
The startup validation pattern
Configuration problems should surface at startup, not at runtime. Here’s an example:
from __future__ import annotations
import os
from dataclasses import dataclass
@dataclass(frozen=True) #Notice how we are using a frozen dataclass, immutable
class Settings:
db_host: str
api_key: str
model_path: str
max_retries: int
@classmethod
def from_env(cls) -> "Settings":
missing = [k for k in ("DB_HOST", "API_KEY", "MODEL_PATH") if not os.environ.get(k)]
if missing:
raise EnvironmentError(f"Missing required env vars: {', '.join(missing)}")
return cls(
db_host=os.environ["DB_HOST"],
api_key=os.environ["API_KEY"],
model_path=os.environ["MODEL_PATH"],
max_retries=int(os.environ.get("MAX_RETRIES", "3")),
)
os.environ.update({"DB_HOST": "localhost", "API_KEY": "key", "MODEL_PATH": "/models/v3"})
settings = Settings.from_env()
print(settings.db_host, settings.model_path, settings.max_retries)
If any required variable is missing, from_env() raises EnvironmentError immediately, and the application does not start. frozen=True prevents mutation after loading.
For larger projects, pydantic-settings provides the same pattern with automatic type coercion, .env file support, and field validation. The dataclass version above is the zero-dependency equivalent.
Gotchas
Don’t over-configure. A value that never changes after the initial decision is a constant. Putting it in environment variables adds complexity without benefit.
.env files are for local development only. python-dotenv loads .env into environment variables for local dev. In production, use your deployment platform’s native secrets management, please, please, please, don’t check .env into source control (a crawler will get your api keys, believe me).
Validate types at load time. os.environ returns strings. Convert and validate at startup: int(os.environ["MAX_RETRIES"]). A ValueError at startup beats a TypeError deep in a batch job.
Takeaways
- Configuration is anything that changes between environments or runs without a code change. Constants in Python files are hardcoding, which is an anti-pattern.
- Load and validate all configuration at startup. A loud startup error beats a silent runtime failure.
frozen=Trueon a settings dataclass prevents accidental mutation after startup, or use Pydantic; it’s actually pretty cool once you get the hang of it.
I’d also love to hear your thoughts and insights on the techniques covered in this article. 💡 Feel free to share your experiences in the comments 💬.
Comments
Loading comments…