Abstract
The quality of mobile user experience (UX) is often perceived as a design domain. In practice, the key UX parameters — launch speed, interface smoothness, resilience to network instability, and crash-free rate — are shaped by engineering decisions at both the client and backend levels.
This article examines UX as a measurable engineering discipline: which signals truly describe experience quality, how to build a “quality loop” through client telemetry (RUM), SLO/SLI, and release guardrails, and how to turn observability into prioritization of improvements. It is shown that UX optimization is effective when focused on critical user flows and worst cohorts (older devices, poor networks), and when improvements are validated by their impact on product metrics (conversion, retention, share of successful actions).
Keywords
mobile UX; performance; stability; crash-free rate; latency; jank; RUM; SLO/SLI; observability; release guardrails; product metrics.
Introduction
A user can rarely articulate exactly what is “wrong” with an application, but quickly feels degradation: slow launch, freezes, “jerky” animation, network errors, unexpected crashes. These effects influence trust in the product and directly impact retention, rating, and share of successful actions.
Unlike the web, the mobile environment is multidimensional: devices of varying power, limited memory, OS background restrictions, unpredictable networks, and delayed client version updates. Therefore, “good UX” on mobile platforms is not only about interface decisions, but also about the engineering resilience of the system to variability.
The engineering framing of the problem sounds like this: which UX parameters do we measure, which target quality levels do we consider acceptable, and how do we prevent regressions when delivering changes? This transforms UX from an aesthetic category into a manageable quality system.
1. UX Signals That Truly Correlate with User Behavior
For mobile products, the most “loaded” UX parameters typically include:
- application launch time (especially p95),
- screen smoothness (jank/FPS drops and frame skips),
- crash-free sessions (share of sessions without crashes),
- network resilience (share of errors, timeouts, retries),
- battery impact (background tasks, inefficient loops).
An important principle: UX is determined not by averages, but by worst-case scenarios. It is precisely the “tails” (p95/p99) that shape the perception of a slow or unstable product, especially on weaker devices and poor networks.
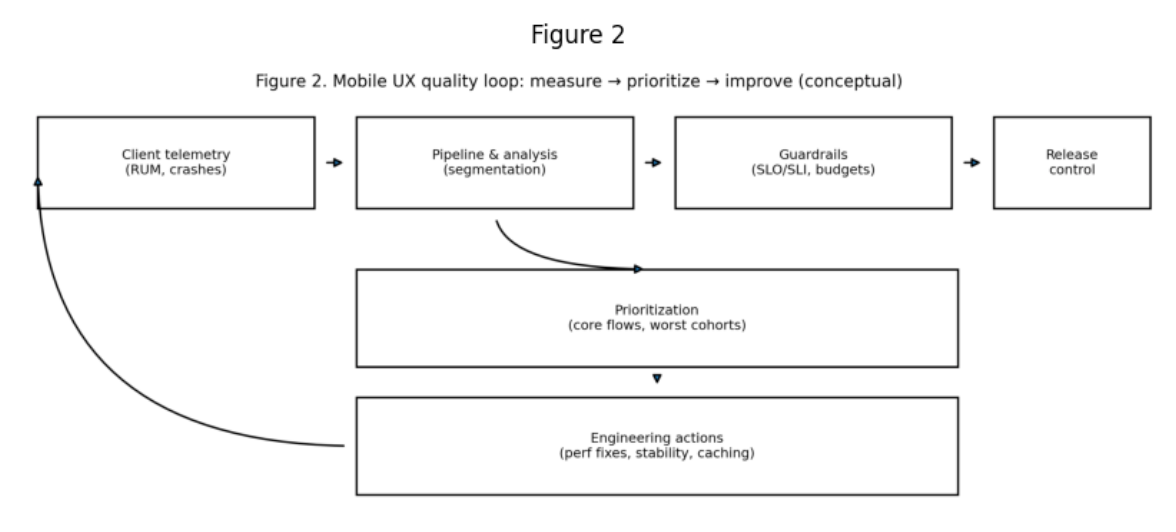
2. “Quality” as a Loop: Measurement → Prioritization → Improvement
Managing UX requires a closed-loop process; otherwise, optimizations become fragmented and do not protect the product from regressions. A practically effective framework looks like this:
- collection of client telemetry (RUM, crashes, network errors)
- segmentation and analysis (by versions, devices, regions, networks)
- guardrails (SLO/SLI and regression budgets)
- prioritization by critical flows and “worst cohorts”
- engineering actions (performance, stability, request optimization)
- release control and validation of impact on metrics
3. Performance as an Engineering Discipline: Where Time Is Usually Lost
In most products, degradation does not occur “in one place,” but rather as a sum of factors:
- heavy screens (complex UI trees, excessive re-rendering),
- inefficient computations on the UI thread,
- excessive network requests or overly “chatty” APIs,
- lack of caching and repeated loading of identical data,
- delays and blocking caused by SDK and analytics initialization at startup.
The key approach is to optimize not the abstract “application,” but the main user journeys: onboarding, login, core screens, payment/checkout, search. It is precisely there that UX improvements produce the maximum product impact.
4. Stability: Crash-Free Rate as the Foundation of Trust
Application crashes and critical errors are perceived by users as a violation of a basic contract. In the engineering model, crash-free rate is not just a quality metric, but an indicator of release controllability. For stability, the following are important:
- testing discipline (especially regression testing of critical scenarios),
- control of environments and configurations,
- careful memory management (leaks, heavy objects),
- version compatibility (client ↔ server),
- release mechanisms for gradual rollout to limit the blast radius.
5. Network as “Hidden UX”: Resilience to Poor Conditions
Mobile UX most often breaks not under ideal conditions, but in reality: subway, roaming, congested networks, high RTT, packet loss. Therefore, the engineering task is to design application behavior so that it remains predictable:
- correct timeouts and limited retries,
- clear loading and error states,
- graceful degradation of functionality without “breaking” the entire application,
- caching and offline strategies where justified.
Users evaluate not what is “sometimes slow,” but what is “unclear and unstable.”
6. Metrics and Guardrails: How Not to Regress
Even if a team once improved launch time and smoothness, quality quickly degrades without systemic protection. Therefore, guardrails are introduced:
- minimally acceptable crash-free levels;
- p95 thresholds for launch and key screens;
- limits on the growth of network errors;
- performance budgets (for example, prohibiting launch time increases in a release).
Guardrails must be embedded into the release process: if metrics worsen, rollout is slowed, stopped, or rolled back. This shifts UX from “firefighting” optimizations to a reproducible engineering practice.
Conclusion
The quality of mobile UX is an engineering task because the key elements of experience are shaped by performance, stability, and network resilience. Effective UX management requires measurable signals, cohort segmentation, and a closed loop of “measure → prioritize → improve” with release guardrails.
Such an approach makes it possible not only to speed up the application and reduce crash rate, but also to consistently improve product metrics: conversion, retention, and user trust.
References
- Forsgren N., Humble J., Kim G. Accelerate. IT Revolution Press.
- Beyer B. et al. Site Reliability Engineering. O’Reilly.
- Nygard M. Release It!. Pragmatic Bookshelf.
- Materials on mobile observability and SLO approaches in product development (generally accepted industry practices).
About the author: Ilia Titovskii is an expert in software engineering and digital product development, with specialization in building scalable systems and leading technology-driven business solutions
Comments
Loading comments…