Introduction
This series of The AI Engineering Journal is to document my process during my internship experience at a software company.
The internship back then was from September 2024 — January 2025.
After the internship ended, I was glad to be offered a position of Software & AI Engineer from January 2025 — March 2025.
Executive Summary of the Internship-to-Engineer Journey
As an intern, I realised that our helpdesk staff struggled to respond to user queries fast and accurately. In their shoes, every second mattered, with the helpdesk user waiting and hoping to get a helpful response from our staff. Optimising this process would mean requiring more manpower and resources, manually sifting through many PDF user documents. I felt that there could be a better way forward by automating it.
As such, I designed Product K, an Artificial Intelligence (AI) solution to facilitate the answering of helpdesk questions. The solution involved using a Retrieval Augmented Generation (RAG) system. The goal was to answer questions accurately with less human intervention, saving time for staff to attend to matters that require their expertise more. The time saved for helpdesk staff to read through PDFs is about 15 mins per PDF read.
The technical process of fine-tuning Product K allowed a significant improvement of 19% in the RAG’s accuracy in retrieving the correct information for user queries. The model’s answers were validated using another AI’s judgement across more common sample questions and answers. Such tests further boosted K-Leap’s confidence in question-answering. More importantly, it boosted the reliability of the solution for real-world helpdesk scenarios.
As I progressed to become an AI engineer, I realised that a large number of helpdesk documents had to be processed. Existing AI solutions in the company had to take days to be fully ingested into the AI system. Hence, I was inspired to improve the efficiency of document ingestion, saving time for Product K to be used by helpdesk staff quickly after inserting the complex amount of information. Implementing and optimising a LlamaIndex data pipeline, this was able to process a large-scale PDF ingestion of 2,085 documents, saving ingestion time from 3 days to only about 1.5 hours.
Internship objective: to develop and deploy an enterprise-grade AI assistant to assist the helpdesk staff. The roadmap involves transitioning from a basic “vanilla” RAG system to an advanced RAG system capable of auto-tuning and an interface.
1. An Overview of Methods
Top-k Value of Parent Document Retrieval (PDR)
Optimising the top-k value in Parent Document Retrieval (PDR) in the RAG model is the central focus for the week in the internship. The top-k parameter determines how many of relevant child chunks or document sections are retrieved in response to a query.
For RAG workflows, tuning top-k is important as it impacts the relevance and completeness of information fed into the LLM for generating accurate responses.
Let’s take a look at how PDR works.

Source from: Weights & Biases.
How does PDR Work?
Firstly, a text splitter is used to split a document into smaller chunks (child chunks). Then, the most relevant child chunks are picked and retrieved. Lastly, the source of the child chunks, also called parent chunks, will be used as context for the model.
The aim of PDR is to allow smaller and more similar chunks to be retrieved with fine granularity. Then, tracking which parent the chunk comes from allows the source to be wider. Hence, a greater context window is used for the experiment.
In theory, the parent child used would allow greater understanding of the information on hand, with more helpdesk steps of the documents captured. The answers would, in theory, be more complete.
However, to test the intuition of PDR, several experiments were carried out to test if the endeavour is worth implementing. Note that the mean score across 10 sample helpdesk questions was computed using the first LLM-Judge (Mixtral).
This method of doing is compared to fixed-sized chunking.
Fixed-Sized Chunking
In fixed-sized chunking, testing and evaluating different chunk sizes to determine their effect on retrieval accuracy was performed. Under the hood, every user query triggers the retrieval process, where each chunk retrieved must adhere to a fixed length to provide context to the model together with the query. This ensures consistency in how the data is presented to the model for processing.
Source from Weaviate.io on Threads.
However, the choice of chunk size directly affects retrieval accuracy. When the chunk size is set to 512 tokens, every segment retrieved and fed into the model will have exactly 512 tokens, regardless of the context of the chunk. Throughout the process, values like 128, 256, …, to 8192 tokens were tuned.
Comparison Between PDR and Fixed-Chunking
Out of all the runs of the hyperparameters tuned (fixed chunking or PDR, varying top-k values of each combination), surprisingly, these three results have caught my eye.
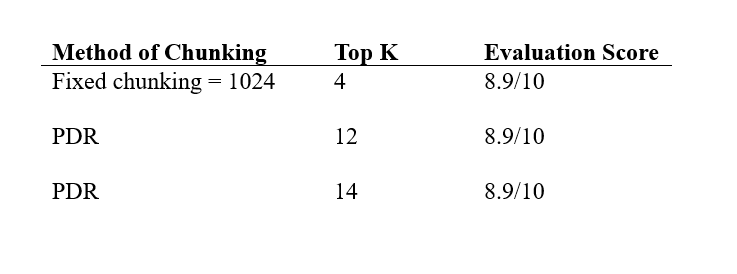
All of them scored 8.9/10 on a range of question-answer pairs as inputs to the RAG helpdesk chatbot.
Unexpectedly, the results ended up in a tie, meaning that both with a fixed chunk length of 1024 (normal chunking with top 4 chunks), and PDR Top 12 are equally effective. PDR Top 14 would not be as effective due to the computational overload of 2 extra chunks for the same estimated performance. This also showed that out of 10 questions, all questions are rated 9/10, except one tougher question, rated 8/10.
Given that Mixtral (the LLM-Judge) struggles to evaluate using decimals and is only able to accurately judge using whole numbers, there could be a better way to tie-break the scores.
2. Tie-Breaking Strategy — DeepEval
This is done by employing DeepEval, a Chain-of-Thought (CoT) prompting method for granular evaluation. This tool could ensure more detailed feedback for our RAG system without reliance on a human to validate the LLM Judge’s scoring decisions.
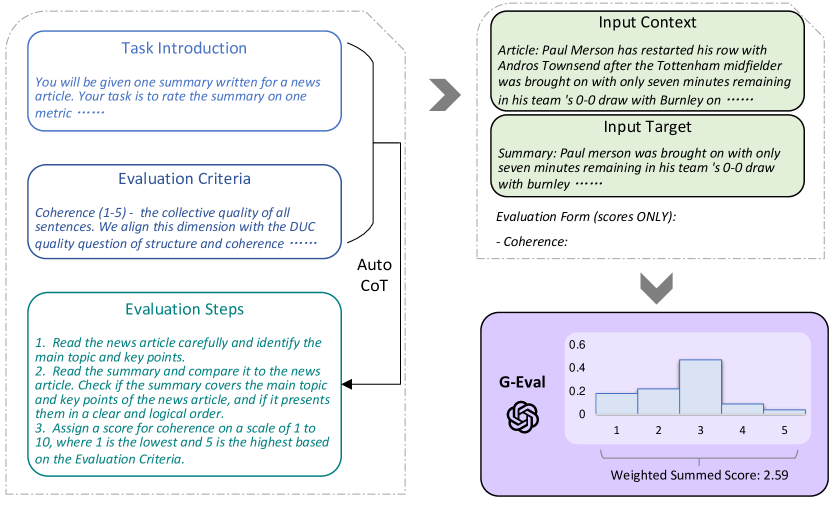
https://ar5iv.labs.arxiv.org/html/2303.16634
The integration of these evaluation metrics and logging systems resulted in a more transparent process for fine-tuning RAG. This project laid the groundwork for continuous improvement in both retrieval and generation steps.
Using a tie-breaking methodology allowed the scores to differentiate. This allows clear interpretability on a more robust method between normal chunking and PDR.
Using a first layer of evaluation (custom G-Eval similarity score), this outputs an approximate 0.8, or 80% similarity of the normal chunking. Also, a 0.79 (79%) score was given on PDR.
The Evaluation of DeepEval
While the margin between fixed-chunking (0.80) and PDR (0.79) is slim, it suggests that fixed chunking has a very slight edge in this context. However, given that the small evaluation set of 10 questions into RAG, the 1% difference should be cautiously interpreted. It might be within the margin of noise, rather than a definitive answer of “one or the other”.
Even though PDR is theoretically richer in its context window, the experiment reveals that it does not significantly outperform a well-tuned fixed chunking approach for this helpdesk use case. There is added computational overhead for PDR, especially at higher values like k = 14, and may not justify the marginal gains.
Why does PDR Not Perform Well Here?
From this experiment specifically:
- The helpdesk documents are already concise and structured, meaning fixed-chunking at 1024 tokens already captures enough context per chunk.
- PDR’s wider parent context window does not add much when the source documents are not very lengthy.
- PDR performs better when documents are long, complex and hierarchically structured. However, the nature of documents into RAG are more self-contained instead for fixed chunking.
Internally within RAG, RAG introduces more text into the context window using parent chunks. These parent chunks may dilute the relevance of the context provided, since the LLM may process a large parent chunk that might not answer the query. As such, it may hurt the precision rather than help it.
Conclusion: Chunking Strategy
The conclusion is to implement a fixed chunking with a value of chunk length = 1024 and top 4 chunks remains a strong baseline for RAG.
In the future, the fixed chunking strategy can also be evaluated against semantic chunking strategies. This can be discussed in a separate article for comparison, as well as the most optimal strategy moving forward.
Errata
Despite every effort to ensure the accuracy of content for the article, occasional errors may occur. Readers who identify any inaccuracies are kindly encouraged to report them. Please contact samuelkoh17@gmail.com with the details of the potential error in the material. Your feedback is much appreciated as it helps improve the quality of work.
Comments
Loading comments…