
If you're an up-and-coming eCommerce company, leveraging web scraping to its fullest potential can give you a competitive edge by providing you with valuable insights into market trends, patterns, pricing, competitor practices, and industry challenges - as I've previously talked about, here:
5 Use Cases of Web Scraping in eCommerce
Anyway, "fullest potential" is key here. Scraping a web page for data may appear simple on paper, but the process can present a number of challenges. Most standard web scraping solutions are not well-equipped to handle these (we'll look into this in a bit). It may be tempting to opt for such "standard solutions", but they can easily backfire, incurring additional costs, and ultimately, costing your business more in the long run with little payoff.
This is why it's important to understand that not all scraping solutions are the same; and that you should make an informed decision when selecting a web scraper for your eCommerce business.
💡 For the example, I'm going to use Bright Data's Web Scraper IDE - an enterprise-grade scraper designed for scalability, with a host of ready-made code templates for scraping data-rich eCommerce websites such as eBay, Amazon and more. It also includes an extremely sophisticated proxy service, built-in debugging tools, and a bunch of other great features, making it my personal recommendation. However, whichever solution you decide to go with, the advice presented here remains valid.
Without further ado, let's get into why choosing the right web scraping solution is important to actually be able to leverage web scraping in beating your competition.
Why It's Important to Choose the Right Web Scraper
Modern websites present numerous challenges for web scraping. Most eCommerce websites frequently change layouts or incorporate anti-scraping measures that can blacklist your IP. Not to mention how standard scraping methods also struggle to scale.
In what follows, we'll look at some of the issues that make selecting the right scraping solution critical to the success of your eCommerce business.
1. Overcoming Scalability and Speed Challenges with a Managed Scraper
Setting up your own scraping software from scratch requires coding knowledge. It is easy enough to set up a simple scraper for a single web page using Python or JavaScript. However, when doing this at scale for several web pages, and/or on regular schedules, the speed and reliability of your process will be severely hampered unless you have a large number of engineers available.
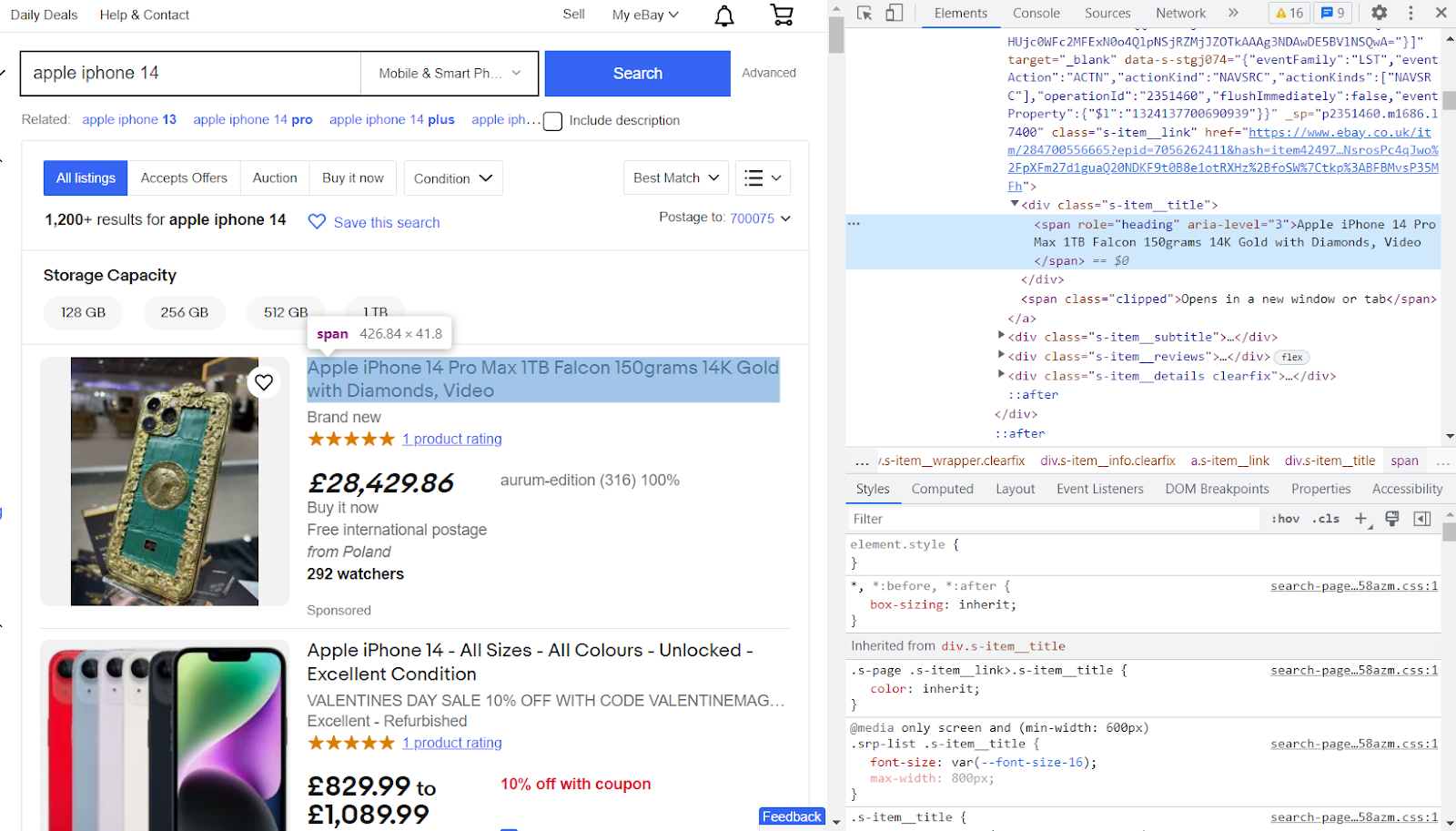
Websites such as eBay and Amazon regularly update their website layouts, meaning that you may no longer find the title in the same div that you wrote the code for.
A tedious and resource-draining process if there was one, and a nightmare when it comes to scaling.
Here's where Bright Data's Web Scraper IDE with its ready-made code templates for eCommerce websites can help.
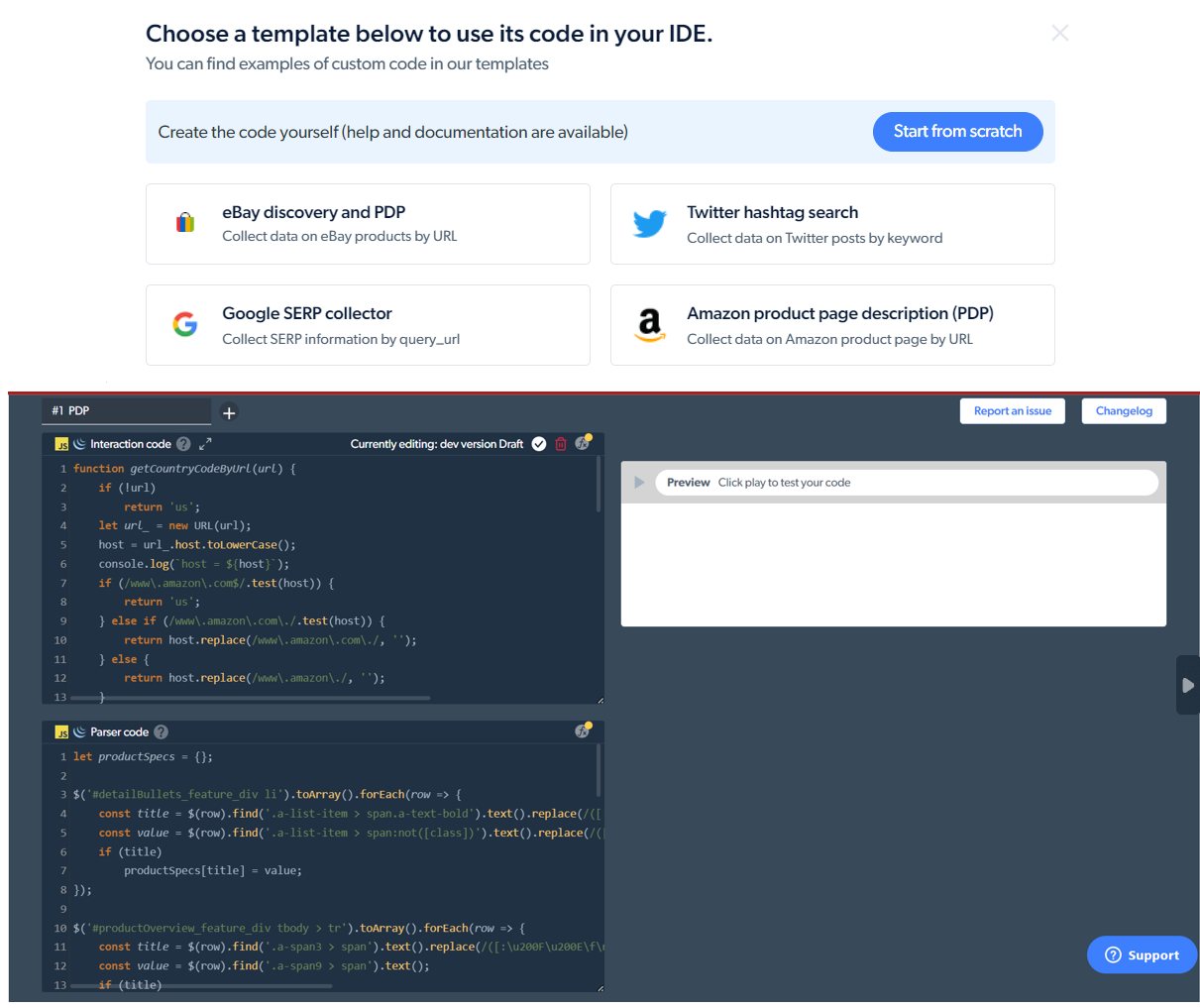
The pre-built code template for gathering product page descriptions from Amazon
You no longer have to spend hours building (and maintaining) your scraper from scratch since the code is already there - and it is managed. Meaning that the Bright Data team ensures that the template code is updated anytime there's a change in the target website's layout or structure. For those with a basic understanding of JavaScript, you can make modifications to the default templates and can leverage the various API commands available.
Note: Even if a template is not available, you can put in a request to the Bright Data team to build one catered to your specific needs.
You can also schedule your scraping operation to re-run at specific intervals (weekly, monthly, or a custom schedule) so that you always receive fresh and 100% accurate data.
2. Bypassing Website Blocks
Most websites these days use sophisticated anti-bot and anti-scraping precautions to prevent 'unwanted' web traffic. If your scraping request is detected as coming from a "crawler", the website can easily flag you and prevent any further attempts at data extraction. This can severely limit the capacity of the data you're able to retrieve.
To access region-specific data from an eCommerce site, one might use proxies to emulate a different location. However, sophisticated websites can detect scrapers using certain proxy networks, and block access.
Here's a piece by Oskar Petr that talks more about website blocks and other challenges faced during web scraping, I highly recommend giving it a read: Overcoming 3 Major Web Scraping Challenges that Developers Face
Bright Data's Web Scraper IDE however, makes use of four different types of proxy services depending on the sensitivity of your data: residential proxies, data center proxies, ISP proxies and mobile proxies. The automated IP rotation also ensures that you can easily bypass hurdles such as CAPTCHAs and rate-limits (when a website limits the volume of requests you can send to it).
Additionally, the IDE uses unblocker infrastructure for IP/device fingerprint-based restrictions on web scraping, seamlessly emulating browser fingerprint information like fonts, cookies, HTML5 canvas/WebGL, OS, screen resolution, and more to avoid being blocked. It also automatically configures pertinent header information (such as User-Agent) to avoid detection as a "crawler."
3. Avoiding Additional Infrastructural Costs
Hosting isn't free. If web scraping operations are at the core of your business, you'll need to set up your own infrastructure and storage for your scraping scripts - and the data obtained.
Bright Data's Web Scraper IDE, on the other hand, is a zero-infrastructure solution for extracting data at any scale. The IDE is integrated into the browser, and templates/scripts are hosted on the Bright Data servers.
Moreover, you can automatically save the data retrieved on your hard drive, or Amazon S3/Google Cloud Storage in the form of a JSON or CSV file...
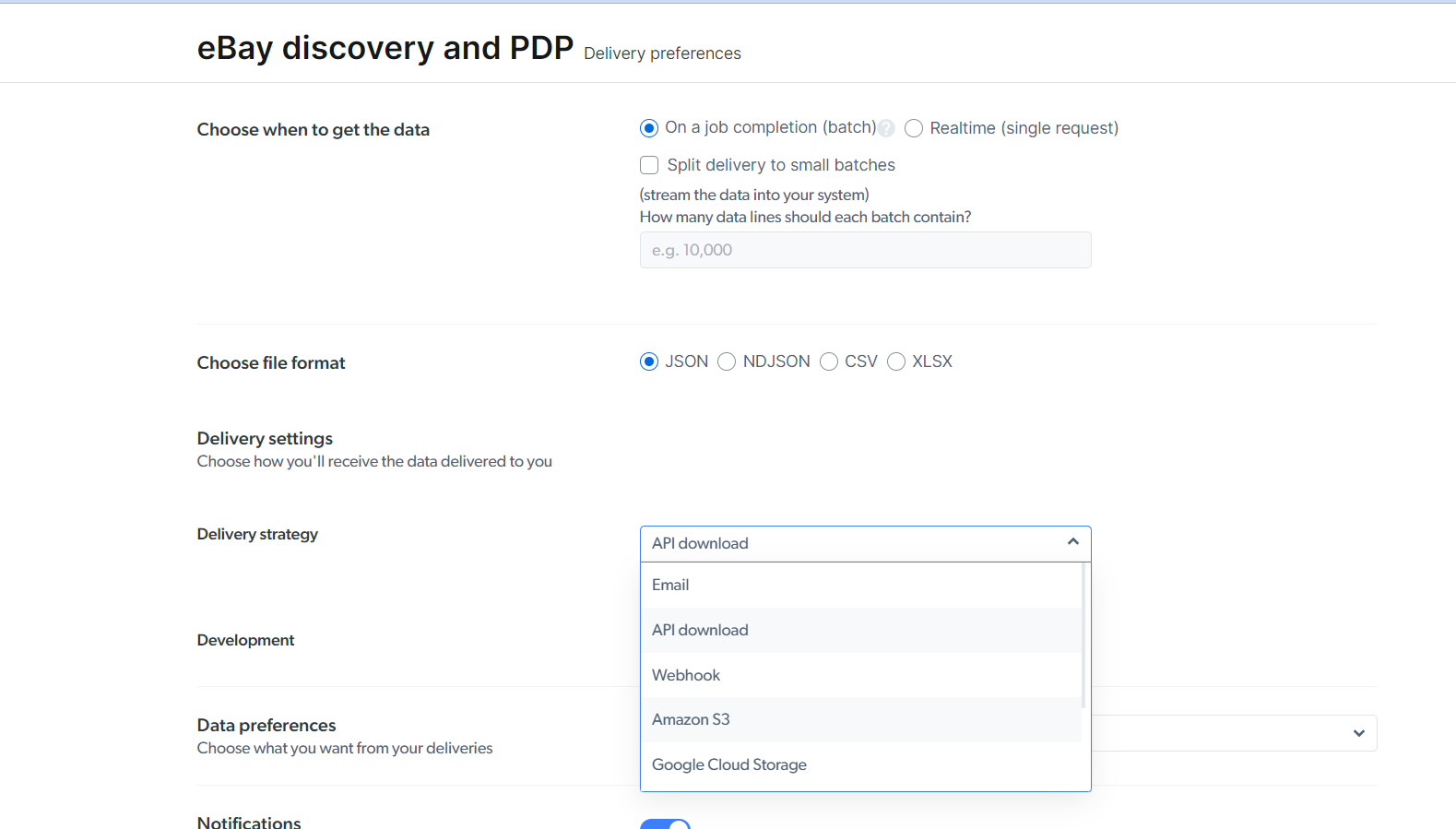
...or fetch it via an API call, integrated into your app.
4. Cutting Down on Management and Maintenance
If your scraping operation is in-house, debugging might take a long time if code breaks unexpectedly. This would require seeking solutions online, which can be time-consuming.
Bright Data's Web Scraper IDE comes with in-built debugging tools allowing you to quickly review a previous crawl to determine what went wrong and what needs to be corrected in the following version. This can be especially helpful if you experience any scraping errors, such as missing or partial data.
Moreover, Bright Data's team offers 24x7 live support (via Chat, Phone, and Email) so you can reach out to them any time you encounter a hurdle and have it solved in no time.
5. Ensuring Legality and Compliance
As per the Computer Fraud and Abuse Act (CFAA), accessing publicly available data is perfectly legal.
However, in real life, the legality of web scraping can often be a thorny question with no context-independent simple 'yes' or 'no' answer. For example, in the LinkedIn vs. HiQ case - where the courts had twice initially ruled in favor of HiQ - the judgment was overturned in 2021 in favor of LinkedIn.
It makes sense to err on the side of caution and avoid unwittingly landing your company in legal hot water.
This is why it makes sense to opt for enterprise-grade scraping solutions that know what they are doing. Bright Data, for instance, complies with all major relevant data protection legal requirements, such as the General Data Protection Regulation (GDPR), The California Consumer Privacy Act (CCPA), and the EU data protection regulatory framework. So you do not have to worry about the legality of your operation.

Now, let's demonstrate the points we discussed above while trying to scrape data from eBay using the Web Scraper IDE.
Scraping Product Listings from eBay With Bright Data
We're going to see how we can scrape information based on product listings on eBay based on a search query in a matter of minutes, with no coding required. Without any delay, let's jump right into it.
For our purposes, we are going to search for "Apple iPhone 14" on eBay UK and scrape the information for the first 10 listings that are in new and unused condition.
This is the page we are going to scrape.
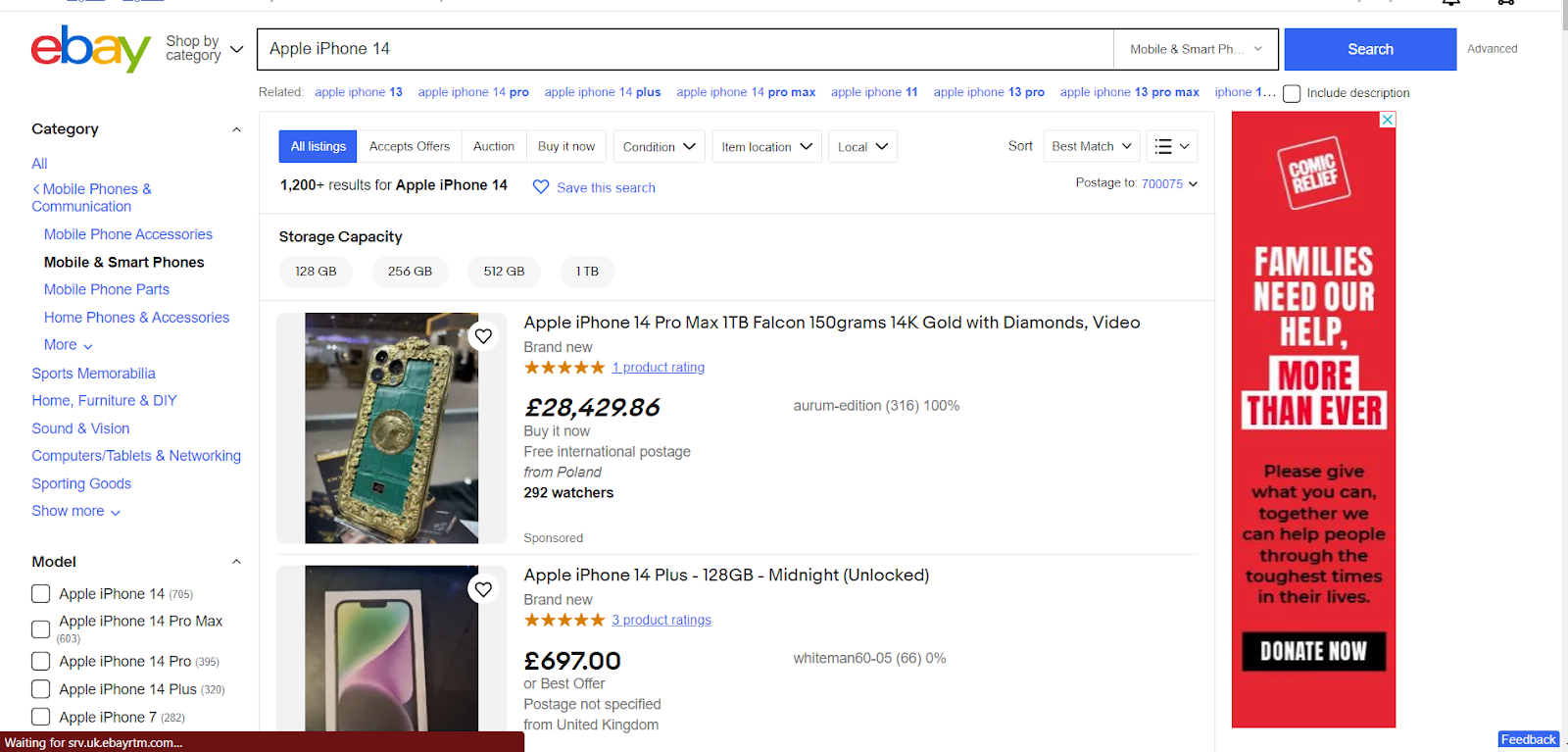
Let's get started.
First, go to Bright Data's website and sign up by clicking on the 'sign up' button on the top right.
Note: You can use your regular Gmail account to sign up as well.
Once you've verified your email and activated your account, sign back in.
Once you're signed in, click on 'Datasets and Web Scraper IDE' on the left sidebar.
Then, select 'My scrapers' which should bring you to this page here. Once here, click on 'Develop a web scraper (IDE)'.
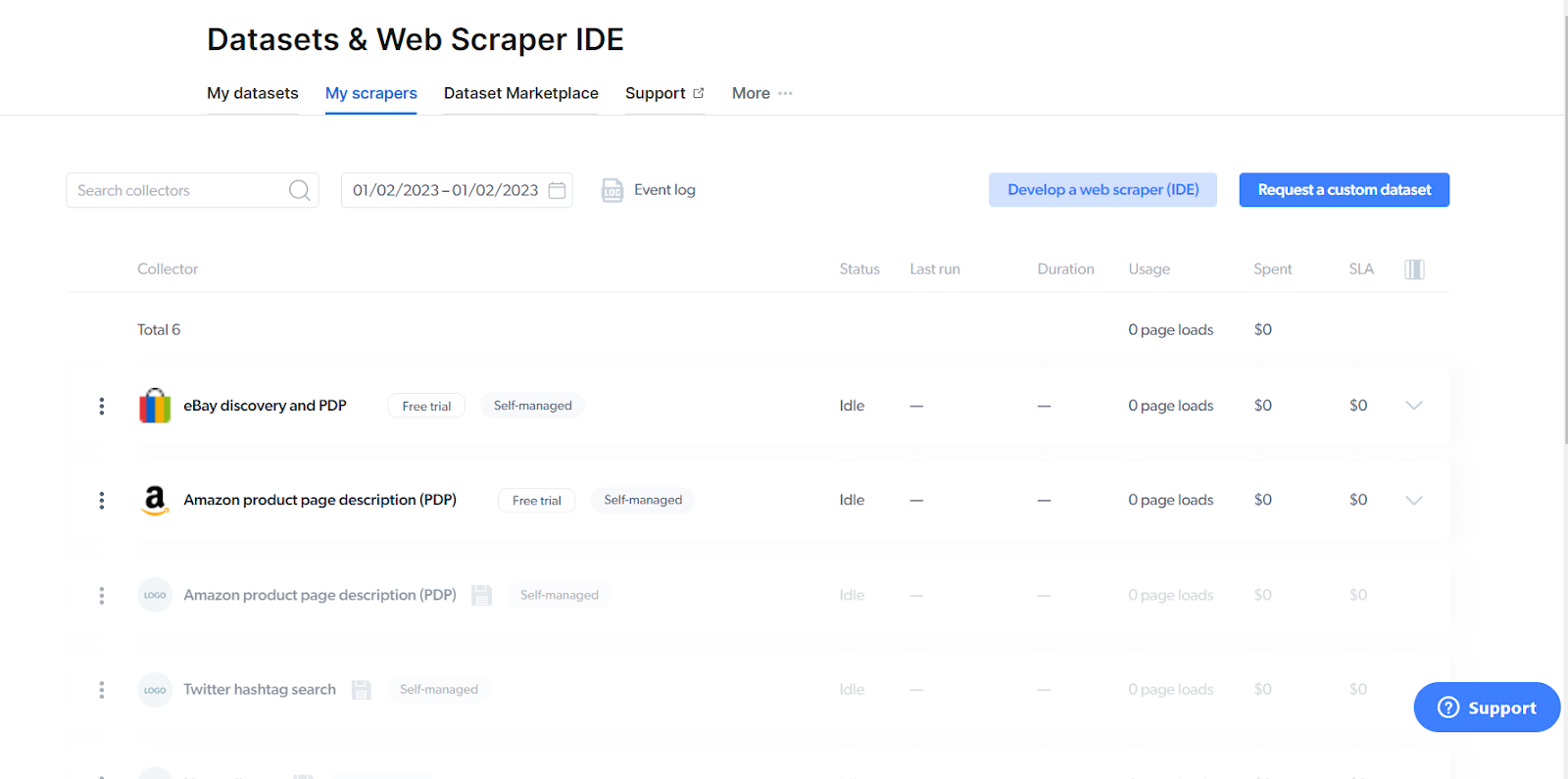
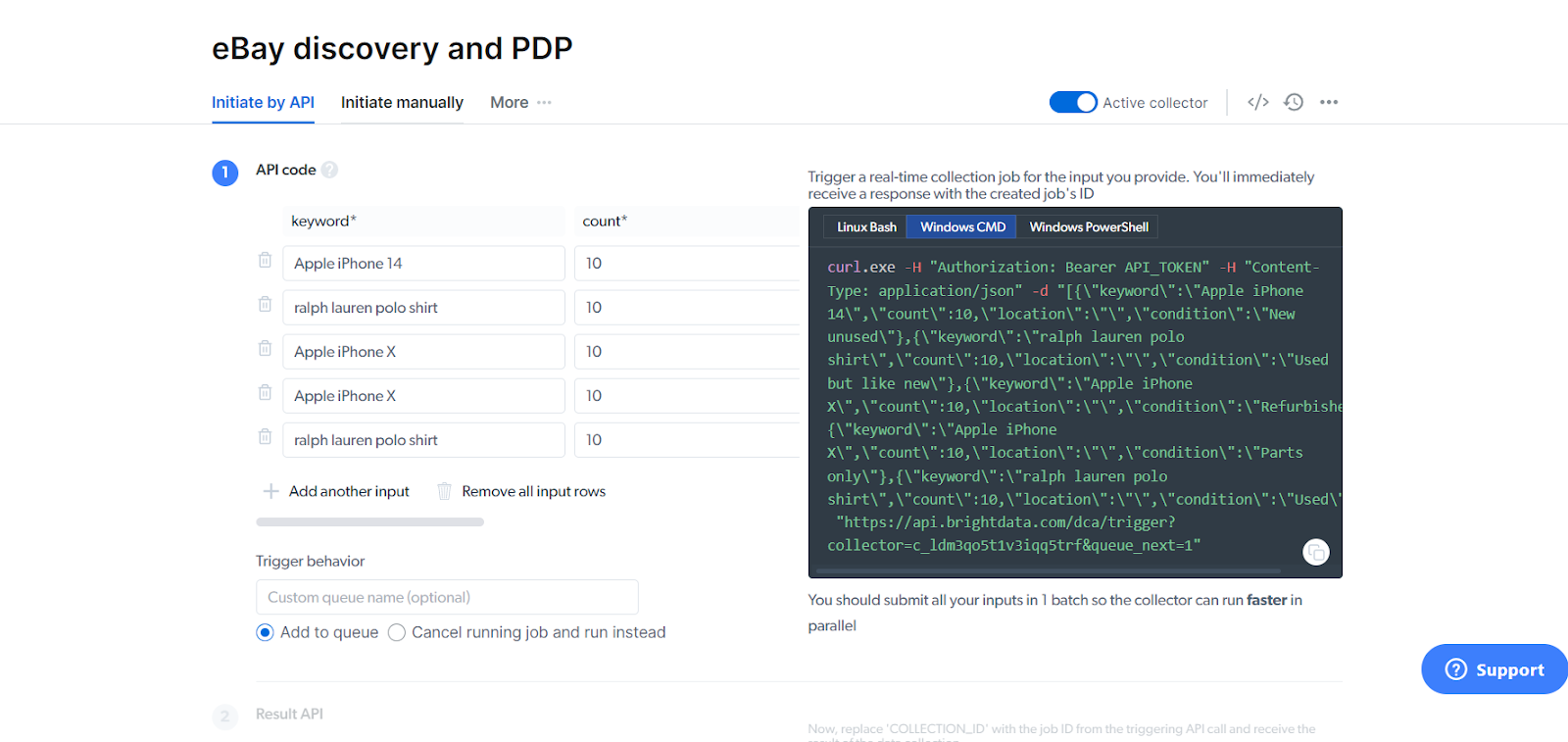
Select the 'eBay discovery and PDP' template.
This will open up the browser-based IDE for us. You can see that the code has already been written.
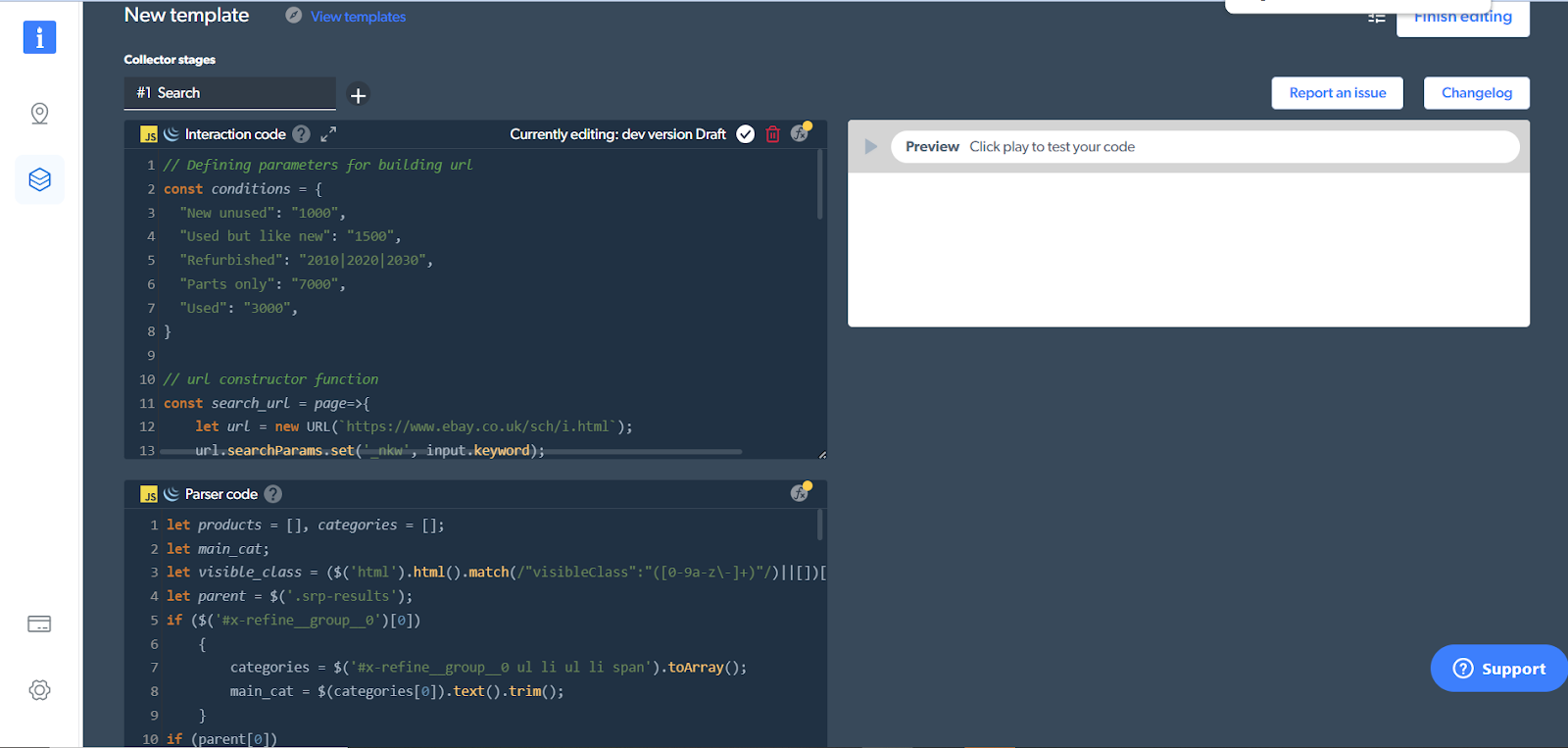
If you scroll down toward the bottom, you'll notice something interesting.
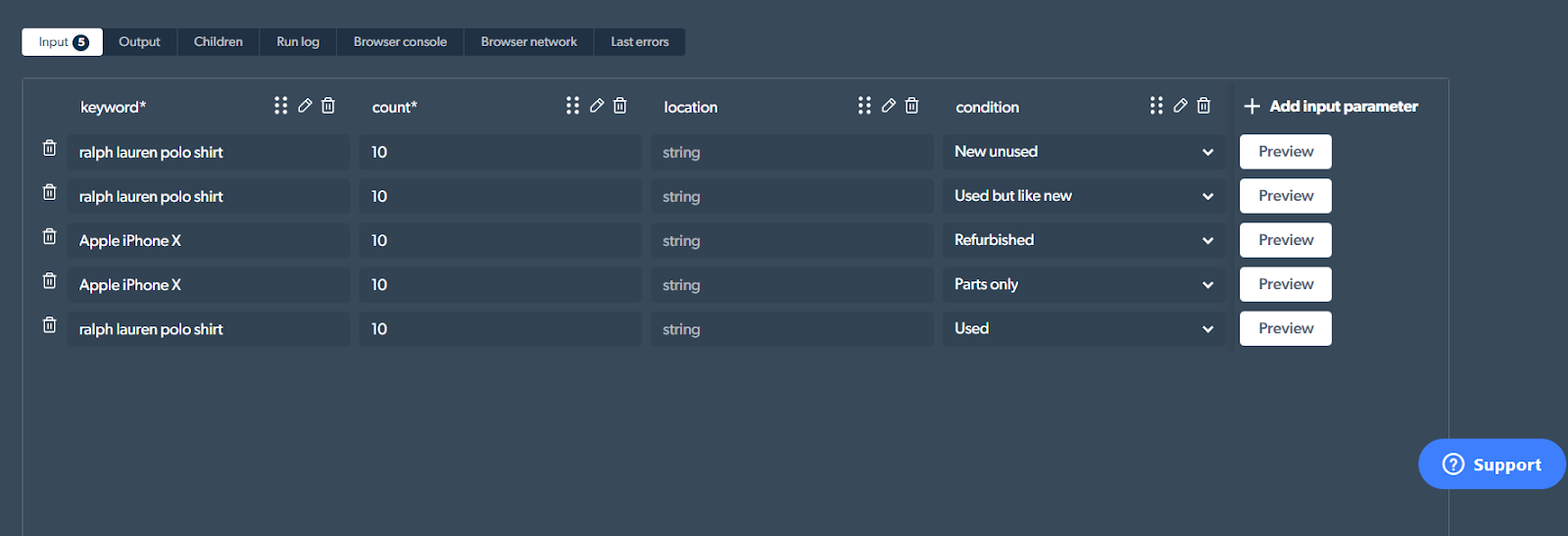
The 'keyword' is the search query we are using. The count being set to 10 means that it will pick up on the first 10 search results that match the keyword as well as its corresponding condition ("new unused"). You can also add in a location if you want.
Now, as you can see, the template here already comes with model search queries. I can click on the 'Preview' button next to each to get the scraping process up and running.
I'll be looking for information on the first 10 'new' and 'unused' listings of the iPhone 14. So, all I'll do is change the description for the keyword, from 'ralph lauren polo shirt' to 'Apple iPhone 14'.
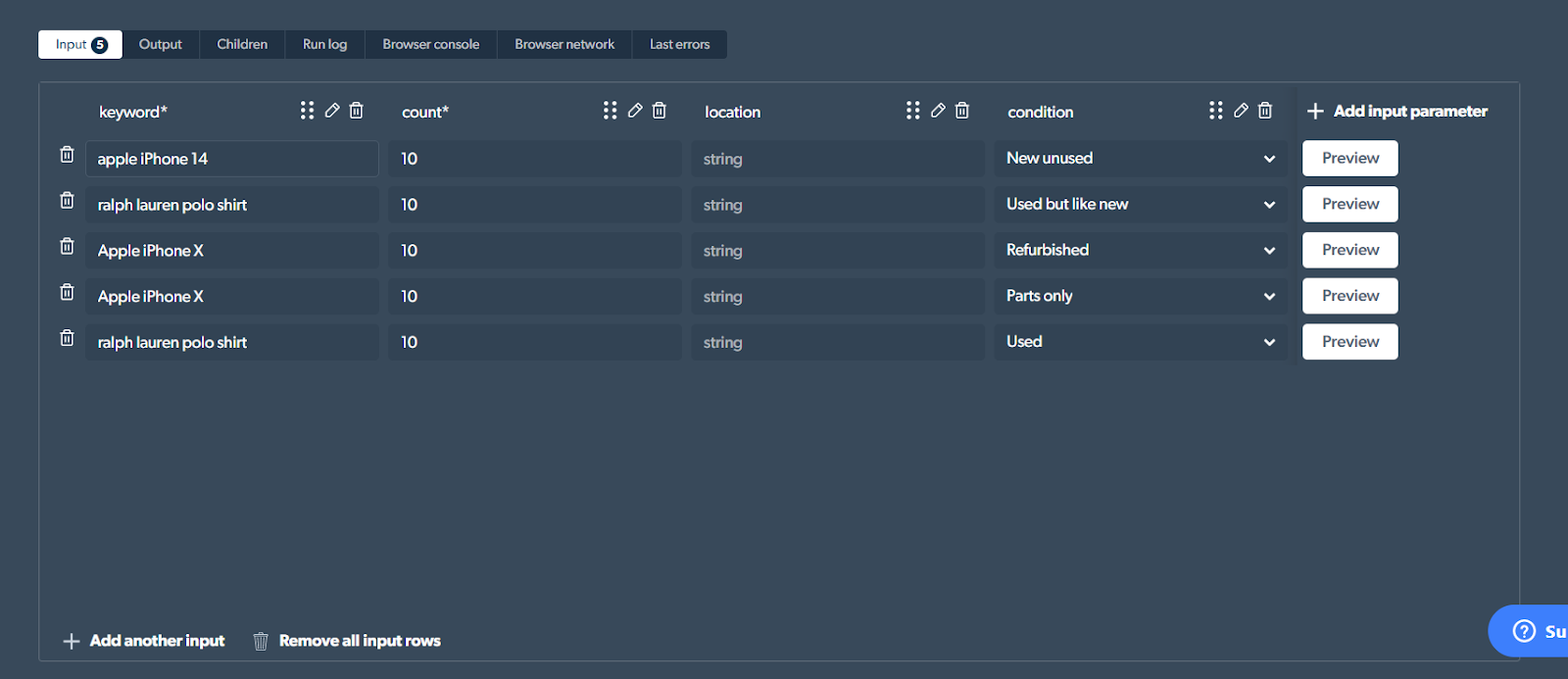
You can enter a product name of your choice, of course, and set the condition accordingly. You can even increase or decrease the count as per your choice.
Anyway, once this is done, hit 'Preview' and the scraping process gets underway. I can observe the progress on the right-hand side 'Preview' window as well.
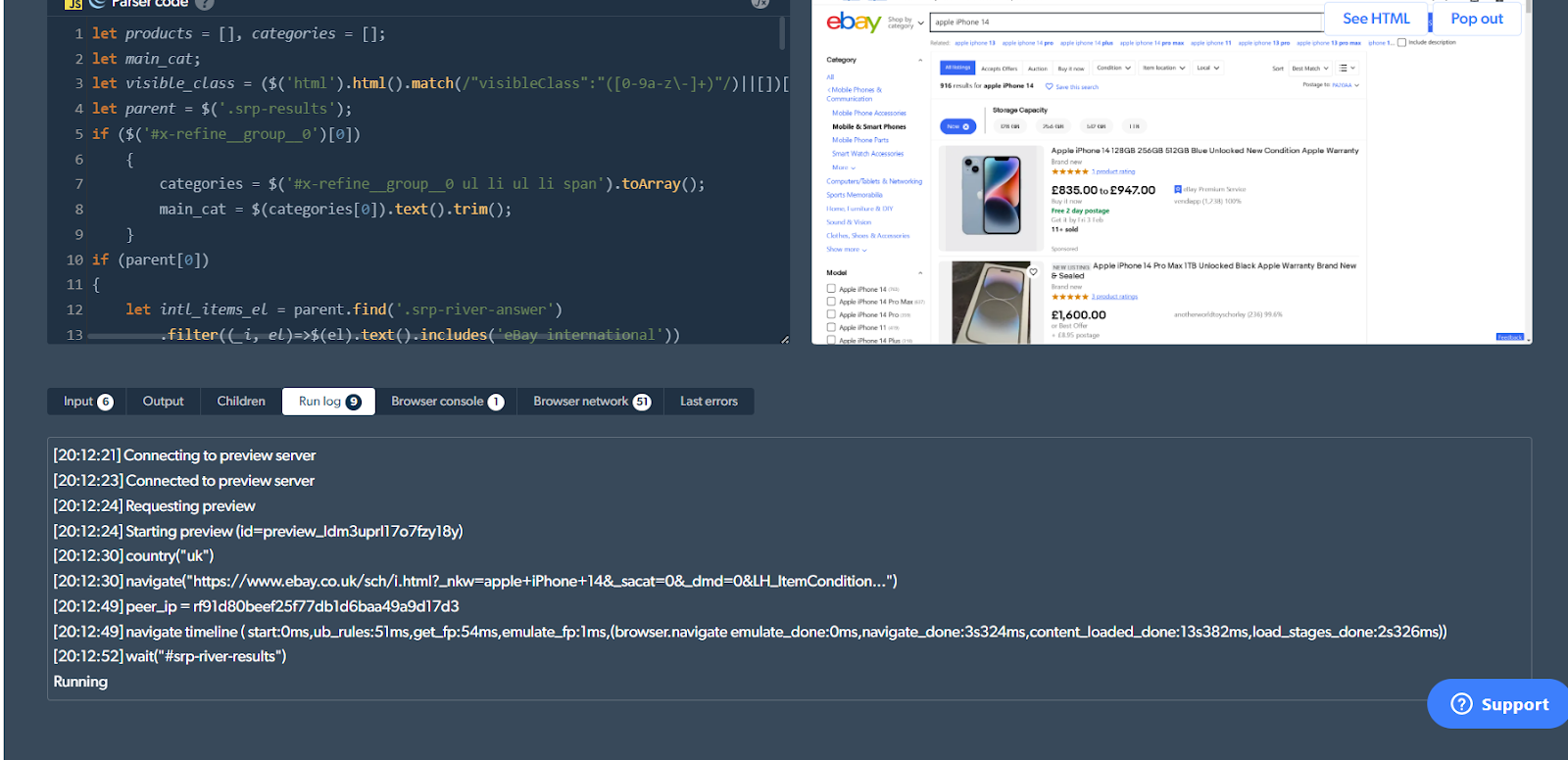
Once the process is done, (took me 3 minutes), you'll see the results under the 'Output' tab.
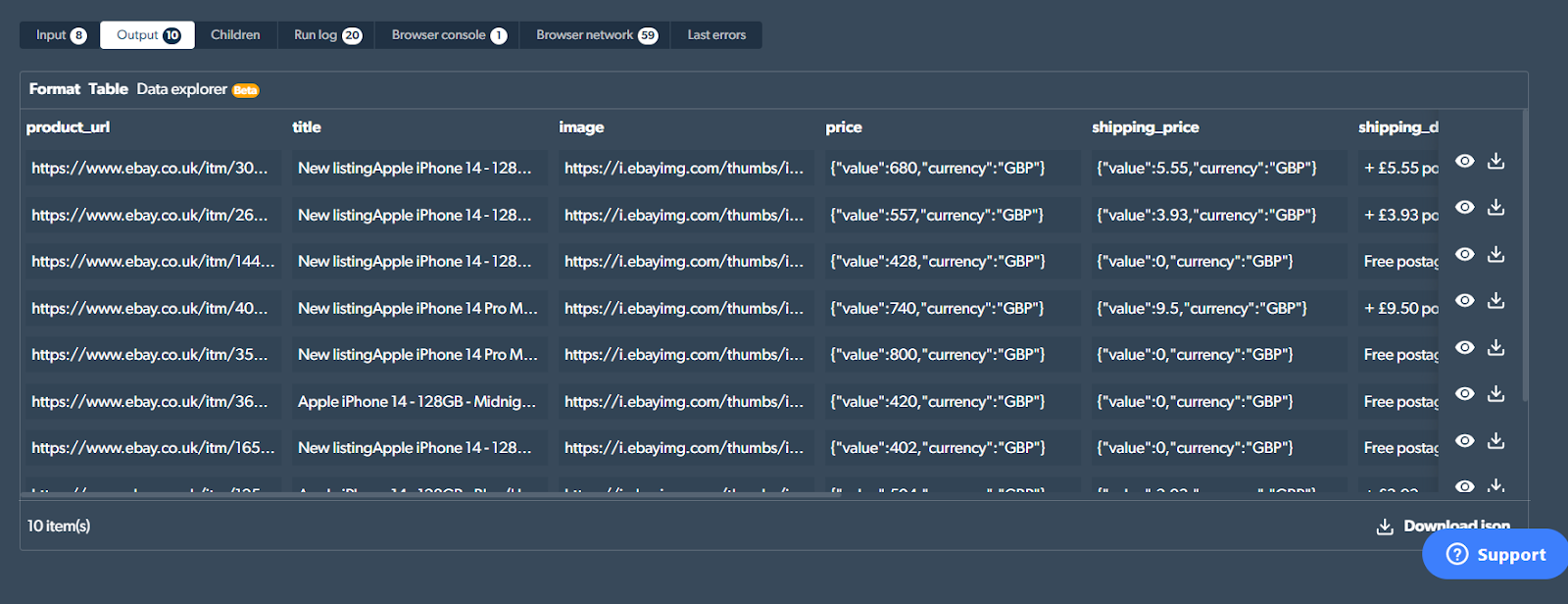
Click on 'Download Json' at the bottom right corner of the screen to get the data in JSON format. In my case, this is what I received.
[
{
"product_url": "https://www.ebay.co.uk/itm/304788534413...ItemCondition=1000",
"title": "New listingApple iPhone 14 - 128GB - Starlight (Unlocked) - NEW AND SEALED",
"image": "https://i.ebayimg.com/thumbs/images/g/XqoAAOSwlhZjuDjk/s-l225.webp",
"price": {
"value": 680,
"currency": "GBP"
},
"shipping_price": {
"value": 5.55,
"currency": "GBP"
},
"shipping_description": "+ £5.55 postage",
"category": "Mobile Phones & Communication",
"location": "N/A",
"condition": "Brand new",
"listing_type": "bid"
}
// ...
]
10 JSON objects in an array, one for each listing matching our criteria.
And that's it - we're done! If I click on 'Finish editing', you can see all the details it picked up under 'Output configuration'.
Conclusion
Web scraping offers eCommerce sites countless benefits that help them stay competitive in a field that is already very stiff. Ready-made web scraping software can help - but even they face challenges.
By utilizing an advanced scraping service like the Web Scraper IDE, your team can focus solely on data analysis rather than investing time and resources in data collection, verification, cleaning, or additional infrastructural costs. Of course, it also has the added benefits of giving you access to real-time monitoring of competitor inventory and pricing as well as 24/7 live support, which gives it a real edge over other scraping software.
You can sign up for a free trial and give it a spin here: Web Scraper IDE - The #1 Website Data Scraper
However, regardless of the scraping software you choose, I hope these articles have shown you why and how to use web scraping to thrive and succeed in your eCommerce business.
Learn more about Bright Data and its products here: https://brightdata.com
Comments
Loading comments…