Written By: Faizan Ahmad, Sr. Manager, Tech Program Management at Amazon Ads

Image: Shutterstock
Customer service systems are expected to function continuously, yet many rely on infrastructure that collapses under stress. One of the most frequent culprits is data migration. Whether due to acquisitions, system upgrades, or platform shifts, these events often break the link between support teams and the information they need.
In sectors like finance and retail media, even short periods of downtime can lead to revenue loss and lasting reputational damage. Common fallback strategies, like spreadsheet tracking or handwritten intake forms, introduce human error, remove auditability, and impose unnecessary overhead.
To address this, I developed and patented a system that rethinks how support teams maintain data access during a migration. Rather than pausing operations or duplicating infrastructure, the model creates a temporary, filtered data layer with authenticated, auditable read/write access. Updates are logged, attributed, and later reconciled with the primary system once migration completes, preserving continuity without added complexity.
This article examines the broader business and operational risks of service disruption during migration and how a targeted data architecture can keep teams functioning during backend transitions.
The Business Case for Zero-Downtime Customer Service
Outages interrupt operations and cause real losses. For regulated sectors like telecom, healthcare, and banking, disruptions may even trigger compliance actions or drive customers away.
Teams often resort to workaround methods. Customer Service Representatives (CSRs) collect requests during the outage and manually update systems once migration completes. This adds operational overhead, increases the risk of inconsistent records, and removes any guarantee of traceable, auditable changes.
These interruptions remain common. According to Uptime Institute, 60--80% of IT and data center leaders reported outages within the last three years. Of those, over two-thirds estimated direct losses above $100,000. Many of these incidents stem from architectural assumptions that systems will remain available, even during major transitions.
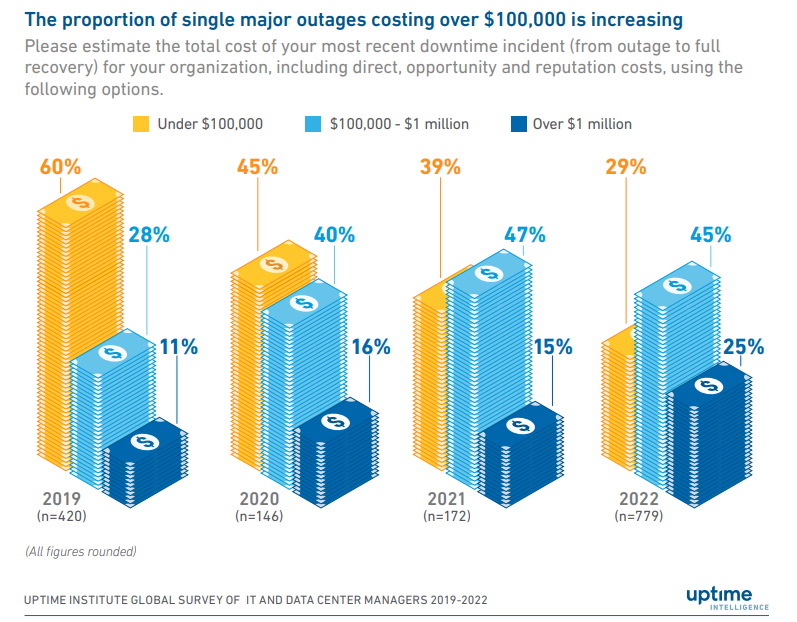
Source: Annual Outage Analysis 2023 | Uptime Institute
However, not all data is needed to maintain customer operations. That observation shaped the architecture behind a different kind of migration contingency system.
An Architecture That Preserves Customer Service Access
My patented system uses a layered configuration structured for fault-tolerance and operational control. It's built around the following core components:
- Source Data Server: Holds the full, permanent dataset.
- Temporary Data Storage: Cloud-native, transient database storing only critical customer fields.
- API Gateway + CSR Terminals: Interface layer enabling real-time reads/writes to temporary storage.

Fig. 1: Systems and Methods for Providing Customer Service Functionality During Portfolio Migration Downtime (USPTO, COF0020 029424.334)
The flow is straightforward. Key customer fields are selected and replicated into a smaller, focused data store. CSRs interact with this system via authenticated APIs. All edits are recorded in a structured instruction queue, which is then applied to the main system when the migration completes.
Security and compliance remain priorities throughout. Access is limited to authenticated users, and the dataset is deliberately constrained to minimize exposure, supporting principles from standards like ISO 27001 and PCI DSS.
Selective Data Replication: A Focused, Low-Exposure Strategy
Most service tasks rely on a small subset of account data. That observation shaped the framework's selective replication strategy. The temporary system holds only these pre-filtered fields:
- Contact info: Address, phone, email
- Verification data: Date of birth or truncated SSN
- Actionable flags: Payment instructions, account blocks, service memos
The data conditioning technique strips away non-essential attributes and formats the remaining data for low-risk storage. In most cases, the temporary dataset requires under 10% of the original storage volume, significantly reducing both exposure and overhead.
Every CSR interaction is logged in a time-stamped queue, with attribution for each change. The queue serves as a post-migration instruction set, enabling precise and conflict-free application of updates once the main system stabilizes. Once the migration finishes, the system applies those updates to the primary database in the sequence they were made, avoiding write conflicts and preserving the order of operations.
Evaluating Approaches to Customer Service Continuity
Manual CSR re-entry remains widespread, especially in legacy environments, but it creates untrackable changes and increases the burden on support teams. More technical organizations sometimes attempt dual-write systems, which involve writing every update to both the legacy and new systems in parallel.
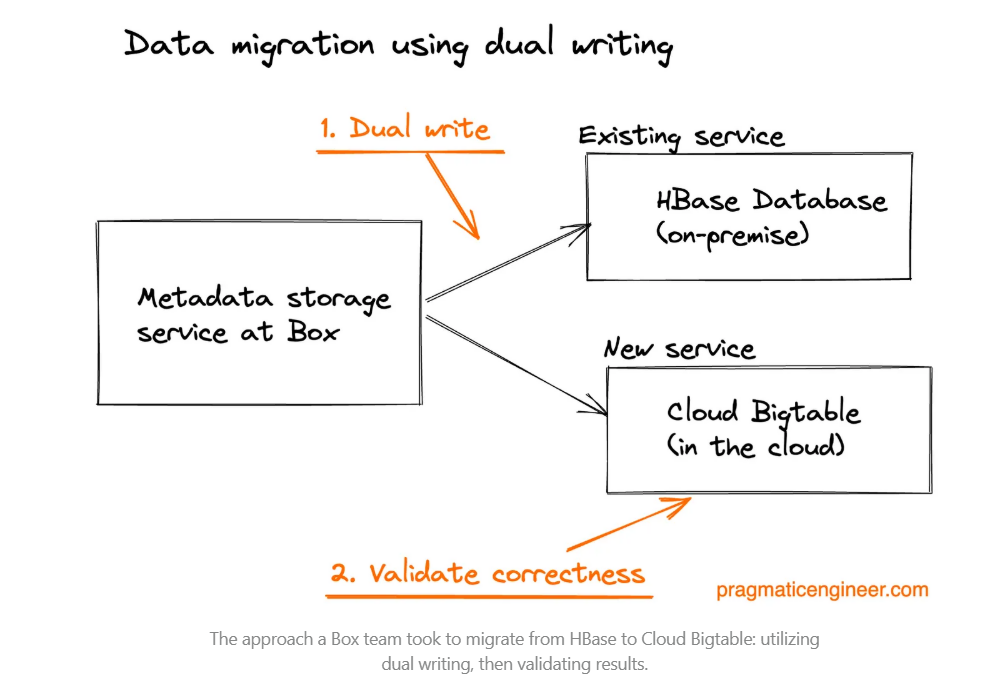
Source: Real-World Engineering Challenges #6: Migrations | The Pragmatic Engineer
Though effective in theory, these setups introduce order-of-operations issues, synchronization risks, and rollback complexity. Even at technically mature companies, such setups are fragile and costly. Teams often introduce write-ahead logs, canary traffic splits, and custom rollback procedures, which significantly increase operational overhead and engineering effort.
By contrast, my framework's instruction-queue method avoids simultaneous writes altogether. The temporary store accepts CSR inputs, logs them with attribution, and queues them for deferred commit. It provides access during migration without risking conflicts or requiring cross-system reconciliation.
Practical Use Cases for Instruction-Queued Access
System downtime, whether scheduled or unexpected, creates significant friction for customer-facing operations. My system's architecture is designed to provide targeted, short-term functionality across multiple failure or transition conditions:
Portfolio Acquisitions
When a financial institution migrates a portfolio, such as a credit card product, data movement can span 48 to 72 hours. During this time, CSR systems are typically frozen. By replicating only key fields (e.g., addresses, account blocks, and memos), the system allows limited functionality to continue.
System Maintenance Windows
Organizations regularly take core services offline for patches, version upgrades, or schema changes. Without a fallback, this halts front-line support. The system solves this by enabling front-line teams to reroute traffic to the temporary store. Most support queries can still be addressed without the full backend.
Emergency Failover Scenarios
When a failure occurs without warning, the temporary data store refreshed periodically (e.g., weekly) can serve as a short-term fallback. This supports critical tasks like card blocks or address changes while systems are being restored.
Scaling the Model: Operational Takeaways and Outlook
A key decision in the architecture was to separate read and write paths in the temporary store. CSRs can access account information even during partial outages, while edits remain queued until safely integrated. This avoids introducing uncertainty during incomplete migrations.
Another design principle is intentional minimization. By pre-identifying only the data needed for front-line work, the system avoids redundant copying and simplifies retention, especially when using time-to-live policies.
The patent also supports extensibility. As organizations scale these systems, other enhancements may include:
- Field-level comparison to validate post-migration accuracy
- Role-based dynamic access enforcement through external IAM systems
- Configurable retention policies to manage data lifecycle
These adjustments focus on improving control and visibility without introducing unnecessary dependencies or operational overhead. There's also room for more sophisticated monitoring. By comparing queued instructions to post-migration records, teams could build models to detect anomalies or risky patterns before they escalate.
Conclusion: Operational Resilience by Design
System migrations and backend transitions are often framed as technical challenges, but their real impact is operational. Without continuity, even brief service disruptions can cascade into lost customer trust, SLA breaches, or long-term churn.
The architecture described here demonstrates how customer service operations can remain available during full-system downtime. It does something more focused by allowing support teams to continue working with the data they actually need, logging those actions reliably, and syncing them back when the platform stabilizes.
For teams planning data migrations, portfolio transfers, or infrastructure upgrades, the relevant question is whether customer service can function without full backend access. This model provides a way to make that possible.
About the Author:
Faizan Ahmad is a seasoned technology leader and Sr. Manager of Technical Programs at Amazon Ads Publisher Tech in Seattle. He leads strategic programs across 10+ systems, including Prime Video and Twitch, supporting over $56B in annual ad revenue. With prior roles at Facebook and Capital One, he brings 17+ years of experience driving innovation in cloud-scale systems, AI/ML, and digital monetization. His past roles include TPM at Facebook's Data Center Infra group and Engineering Manager at Capital One, where he led large-scale credit card migrations and fraud platform builds. Faizan holds an MBA from Manchester Business School and a Data Science Certificate from DePaul University.
References:
Lawrence, A., & Simon, L. (2023, March). Annual Outage Analysis 2023. Uptime Institute. https://uptimeinstitute.com/resources/research-and-reports/annual-outage-analysis-2023
Greathead, C. (2023, June 13). ISO 27001 & PCI DSS: a two-pronged approach to robust information security. Security Risk Management. https://www.srm-solutions.com/blog/iso-27001-pci-dss-a-two-pronged-approach-to-robust-information-security/
Orosz, G. (2022, October 11). Real-World engineering Challenges #6: migrations. The Pragmatic Engineer. https://newsletter.pragmaticengineer.com/p/real-world-engineering-challenges
Flower, D. (2021, November 22). Council Post: The unplanned downtime nightmare --- and how operators can avoid it. Forbes. https://www.forbes.com/councils/forbestechcouncil/2021/11/22/the-unplanned-downtime-nightmare---and-how-operators-can-avoid-it/
Identity and Access Management Trends 2023. (2023, March 28). eMudhra. https://emudhra.com/en/blog/iam-trends-in-2023
Comments
Loading comments…