Imagine an AI that can read an entire library without getting overwhelmed. Today’s large language models (LLMs) , like OpenAI’s GPT series (e.g., ChatGPT) , are incredibly powerful, but they have a context window limit. This means they can only process a certain amount of text in one go (for instance, GPT-4’s standard limit is about 8,000 tokens, and even a hypothetical GPT-5 might go up to 272,000 tokens[1]). If you give them text longer than this, they simply can’t take it all in at once. Even within those limits, something curious happens as the input grows: the model’s performance starts to degrade. It may forget details from earlier, mix up facts, or lose track of the overall structure. AI researchers call this “context rot,” meaning that as the prompt gets longer, the model’s ability to accurately use that information rots away[2]. Many of us have seen this in action , if you have a very long chat with a bot like ChatGPT, it might start repeating itself or making mistakes, almost as if it’s getting dumber over time. This isn’t because the model is bored; it’s because its limited working memory (context window) is overloaded and it can’t keep all the details straight.
The Context Limit Problem in AI
For AI enthusiasts, this context limit is a well-known headache. If you want a model to answer questions about a lengthy document or analyze a huge dataset, you have to chop the input into smaller pieces or use workarounds. Typical solutions include retrieval systems (fetch relevant chunks of text) or summarization pipelines (summarize parts of the text progressively). Essentially, these approaches pre-digest the content for the model , they decide which pieces of information to show to the AI and which to leave out[3]. While such techniques can help, they have limitations. Summarization might throw away important details, and retrieval systems depend on good search strategies decided in advance. Crucially, in all these methods the model itself remains a passive reader[4]. A human or an external program is making the decisions about how to break down the problem and what snippets of text the model gets to see.
What if we turned this paradigm on its head? Instead of the AI being a passive consumer of whatever context we shove into its input, could the AI actively decide what it needs to read and in what order? Enter Recursive Language Models (RLMs) , a new approach emerging from MIT that is poised to break the context barrier and let AI models handle truly massive inputs. RLMs offer a fundamentally different, more active way for language models to engage with information[5]. In simple terms, an RLM-enabled system doesn’t cram all the data into the model’s brain at once. Instead, it lets the model explore the data in pieces, intelligently and recursively, almost like an AI detective searching for clues in a mountain of text.
What Are Recursive Language Models (RLMs)?
Recursive Language Models (RLMs) are not a new type of neural network architecture or a larger GPT model. Rather, an RLM is a clever strategy for using existing language models in a way that bypasses their normal context length limits[6]. From the outside, calling an RLM looks just like calling any other LLM , you give it a prompt (which could be extremely long) plus a query or task, and it will eventually return an answer[7]. But inside, the process is very different.
Instead of one giant step (feeding the entire huge prompt into the model at once), an RLM breaks the process into many small, manageable steps. It’s called “recursive” because the model can call itself on smaller chunks of the text[8]. In essence, the model becomes both the reader and the research assistant:
· The Root Model (Coordinator): This is the main instance of the LLM that handles the high-level conversation or query. The root model sees your question or task and is aware that it has tools at its disposal (like the ability to run code or call helper models). Importantly, the root model does not see the entire long prompt at once[9]. Think of it as the project manager that knows what needs to be done, but not all the raw data upfront.
· The Environment (Memory/Workspace): This holds the full context (the very long prompt or dataset) externally. In the RLM paper’s implementation, the environment is like a Python REPL (Read-Eval-Print Loop) , essentially a live coding notebook where the full text is stored in a variable[10][11]. This environment can execute code and keep state. You can imagine it as a scratchpad or an external hard drive where all the data is available, but not directly in the model’s “head.” The model can query this environment to fetch pieces of data.
· The Sub-Model (Helper): This is essentially the same underlying LLM (or a smaller version of it) used as a helper that the root model can call to analyze specific pieces of the context[12][13]. The sub-model might read a snippet of text (say, a few paragraphs or a single document from the pile) and return some result (like a summary or an answer to a sub-question). The sub-model is like a junior assistant that specializes in reading small chunks and reporting back.
In an RLM, these three components work together in a loop. Here’s how a typical RLM query might go:
1. User Query: You (the user) ask a question or give a task along with a huge context. For example, “Given the attached collection of 100 research papers, what are the key trends in AI in 2025?” The collection of papers is far too large to feed directly into an ordinary LLM.
2. Initialize Environment: The RLM system loads those 100 papers into the environment (e.g., stores them as text in a variable in a Python REPL). The root model is told general info like, “You have a variable all_text that contains all 100 papers, totaling 10 million tokens,” but it isn’t given all_text directly in the prompt[10].
3. Root Model Plans: The root LLM receives the user’s question and knows it can use tools. It might decide: “First, I should figure out how to approach this. Perhaps search the text for keywords like ‘2025’ and ‘trend’.” The root model then issues an action in the environment, e.g., a piece of code or command to search within all_text[14].
4. Environment Executes & Responds: The environment runs the command, perhaps finds occurrences of “trend” across the papers and returns some snippets or counts. The root model sees these results.
5. Root Invokes Sub-Model: Based on those results, the root might say, “Now I have a bunch of excerpts about trends. I’ll ask a sub-model to summarize each chunk.” It can call the sub-model (another instance of the LLM) on, say, one paper’s text at a time. For each call, the sub-model gets a slice of all_text (small enough to fit in its normal context window) and a prompt like “Summarize this paper’s key points about AI trends in 2025.”[15][16] The sub-model processes that chunk and returns a summary.
6. Iterate Recursively: The root model collects the summaries or findings. It can loop, performing new searches, reading new chunks, or asking follow-up questions to sub-models as needed. This recursive loop continues, with the root model steering the process: it decomposes the task of reading the huge context into many sub-tasks on sub-parts of the text. The key is, the model itself is deciding what to read next and what to ignore for now[17]. Unlike a fixed pipeline, it’s dynamically figuring out how to navigate the information.
7. Final Answer: Once the root model is “confident it has the answer” or has gathered enough pieces, it stops the loop and produces the final answer for the user[18]. For instance, it might compile the insights from all sub-model summaries and answer: “Key AI trends in 2025 include X, Y, Z, as evidenced by these papers.”
This process may sound complicated, but to the end user it feels like asking a question to a very smart AI that doesn’t have a short memory. From the outside, you just get your answer as if a single model responded[6]. But under the hood, the RLM has orchestrated multiple small reads and analyses to handle your giant prompt.
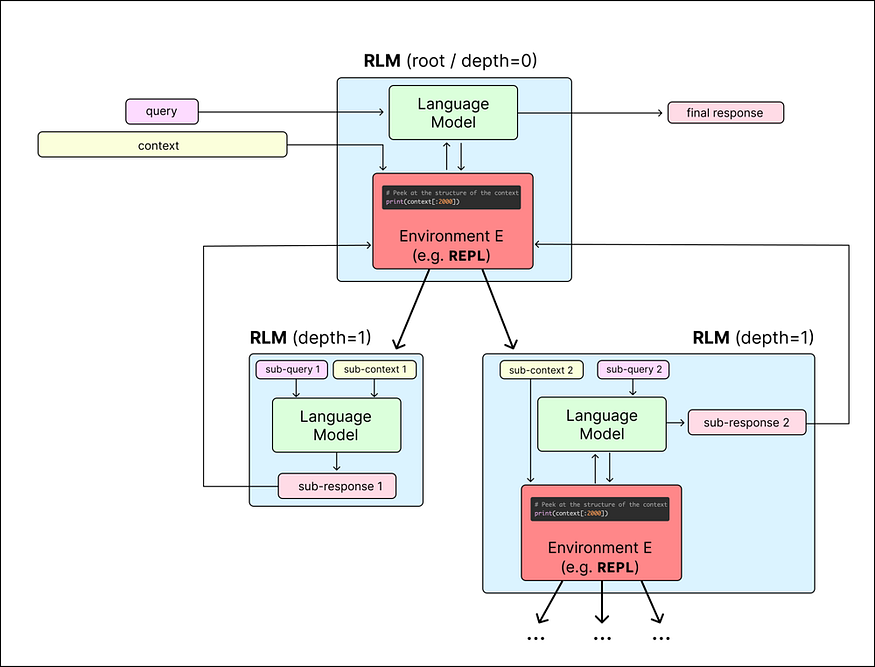
A conceptual diagram of a Recursive Language Model in action
Figure: A conceptual diagram of a Recursive Language Model in action. The Root LLM (depth=0) receives the user’s query and coordinates the process. It interacts with an external environment (like a Python REPL) where the entire context is stored as a variable (Context in this diagram). The root can execute code or commands in the environment to peek into the context, extract snippets, or manipulate data. It can also spawn Sub-LLM calls (depth=1) , essentially calling another instance of the language model , to analyze specific snippets of the context. Each sub-LLM processes only a small chunk (e.g., one document or a segment of text) and returns results (shown as “Sub-response”). The root LLM then uses those findings to inform its next steps. This recursive loop continues until the root LLM has gathered enough information to produce the final answer. In this way, the model effectively handles a huge context by breaking the reading into many smaller pieces, rather than trying to swallow the entire context at once.[19][15]
RLM vs. Traditional AI Agents: Active Reader instead of Passive Reader
If you’re familiar with AI agents like ReAct or tool-using systems, the above might sound similar , those systems also have the model take multiple steps, use tools like search or calculators, etc. However, RLMs have a unique focus and important distinction: agents typically decompose the task, whereas RLMs decompose the context[20]. In a traditional agent approach, a human designer often defines a sequence of steps (e.g., “first search for relevant docs, then read them, then summarize, then answer”). The model follows this game plan, breaking the problem into parts. In RLMs, by contrast, the model breaks the input data into parts on the fly. The strategy isn’t fixed in advance , the model dynamically decides how to traverse and explore the context during inference[17].
Crucially, the context itself becomes a first-class citizen. The entire body of text is accessible in the external environment like a database, not hidden inside a single prompt string[21]. The RLM can programmatically inspect it in arbitrary ways. The best analogy coined to date: a normal LLM is a reader, but a Recursive Language Model is a librarian[22]. A reader tries to read a book cover-to-cover and remember everything, which doesn’t scale if the book is a million pages. A librarian, on the other hand, doesn’t attempt to memorize the whole library. Instead, the librarian knows how to look things up. An RLM-equipped AI acts like a skilled librarian: it keeps notes, searches the catalog (the context), retrieves relevant volumes, consults them (with sub-models as assistants), and compiles the needed information[23]. By not forcing the model to cram all information into its immediate attention, RLMs avoid the trap of context rot[24]. The model isn’t suffocating under an “overloaded prompt” , it’s navigating a vast memory at its own pace, with tools to assist.
This is why RLMs can scale to handle millions of tokens without breaking a sweat[25]. The model never tries to read the entire 10 million tokens at once. It only ever reads the portions it asks for, one piece at a time, so there’s no point where the full load overwhelms it. Reading less, but smarter, lets it do more. In fact, the original paper’s core insight was just that: “long prompts should not be fed directly into the neural network, but instead treated as part of an external environment that the LLM can interact with”[19]. RLMs implement this insight in a general-purpose way.
A Simple Example: Finding a Needle in a Haystack (with RLM)
To make this concrete, let’s use a toy example. Suppose we give an RLM a ridiculously long text , say a billion random characters , and somewhere in there is a hidden secret code, like the number “42”. We ask: “What is the secret number hidden in the text?”
A regular LLM (with a huge context window, assuming the text even fits) would struggle or outright fail. It might miss the number or get confused by the vast irrelevant content. But an RLM would approach it cleverly:
· The root model might start by issuing a command in the environment to search for any numbers in the text (a simple regex or search function).
· The environment quickly finds the positions where numbers occur and returns, say, “Found a number at character position 7,891,234: it’s ‘42’.”
· The root model sees this and realizes the answer is likely “42”. Maybe it double-checks by calling a sub-model on the snippet around that position to ensure the context is correct (e.g., “…the secret number is 42…”). The sub-model confirms it.
· The root model then outputs the final answer: “42.”
This is a trivial case, but it shows how the RLM treats the context like a searchable database. The model didn’t read the entire billion characters. It strategically queried the context, found the relevant bit, and solved the task. In experiments, RLMs demonstrated this kind of capability, successfully locating specific needles in massive haystacks of text that far exceed normal LLM memory[26].
Now, not all tasks are as straightforward as a simple search. Some require reasoning over the content, combining information, or reading most of it to synthesize an answer. The power of RLM is that it can handle those too by decomposing the reading process into manageable chunks and intermediate questions. It’s like recursively breaking a big question into sub-questions about parts of the text. Humans do this naturally when dealing with long documents , we skim, we find relevant sections, we take notes, and we piece it together. RLMs aim to give LLMs that same flexibility.
How RLMs Perform in Practice
The RLM approach isn’t just a theoretical idea; it has shown remarkable results in research experiments. The authors of the Recursive Language Models paper put RLMs to the test on several challenging tasks that involve very long inputs. They compared RLM-driven models against standard LLM usage and other long-context methods (like summarization-based agents or retrieval-based pipelines). Here are some highlights:
· Handling Extreme Lengths: RLMs were able to successfully process inputs over 10 million tokens in length[27]. This is 100× beyond the context size of even cutting-edge models. For perspective, 10 million tokens is roughly equivalent to 8 million words , imagine an AI comprehending dozens of novels or an entire Wikipedia article collection in one go. Traditional LLM calls couldn’t even accept such input, and even if you somehow forced it, the quality would collapse. RLMs, on the other hand, navigated these huge inputs effectively, showing little to no performance degradation at extreme scales[28].
· Dramatic Quality Improvements: Even on inputs within a normal context window, RLMs often beat the base model’s performance by a wide margin[29][27]. In the paper, a range of tasks were tried , from deep research questions (which require pulling together info from many documents) to codebase understanding and synthetic reasoning puzzles. In most cases, the RLM approach outperformed not only the plain LLM, but also stronger baselines like “context compaction” (iteratively summarizing the text) or retrieval-based agents. The gains were often in the double digits (percentage points). For instance, on one particularly hard reasoning benchmark, the standard GPT-5 model essentially failed (near 0% success), while the RLM-augmented version of GPT-5 achieved about 58% , a huge leap from impossible to pretty decent[28][30]. This benchmark involved a task where the solution depended on considering many pairwise combinations of facts in the prompt, something a normal model couldn’t handle once the prompt got large and dense. RLM cracked it by systematically breaking down the reasoning over those pairs.
· “No More Context Rot”: Perhaps most intriguingly, RLMs showed no significant decline in performance as input length increased, up to the limits tested (10M+ tokens)[28]. Normally, as tasks feed in more and more text, model answers get worse (context rot kicks in). But RLM-based models maintained strong performance even as they scaled to inputs that would send regular models off the rails[31][27]. In one multi-document QA task, feeding 1,000 documents to a vanilla LLM yielded near-zero correct answers (it was overwhelmed), whereas the RLM version kept answering questions correctly because it could pick out the relevant info from that mountain of text[28].
· Cost Efficiency: One might think all these extra steps (multiple model calls, tool uses) would make RLMs slower or more expensive to run. Yet, the researchers report that RLMs were comparable in cost per query, or even cheaper in some cases, than baseline methods[32][27]. How is that possible? They cleverly used smaller models for the recursive sub-calls. For example, the experiments used a big model (GPT-5) as the root and a lighter-weight “GPT-5-mini” for the sub-model calls[33]. This way, each sub-task is handled efficiently, and the expensive big model only has to deal with the high-level orchestration and final answer. Moreover, by not processing tons of irrelevant text (only focusing on what’s needed), the model doesn’t waste its computation on useless tokens. It’s an efficient reader. In fact, the RLM method can be cheaper than naive long-context approaches that might try to stuff everything into a prompt or do repeated summarizations[28].
One concrete example from the paper: on a long-context question-answering benchmark called OOLONG, a Recursive LM using a smaller GPT-5-mini as the engine more than doubled the number of correct answers compared to a single-pass GPT-5, while also reducing the average cost per query[28]. On another task that required reading 1,000 documents to answer a question, the RLM approach soundly beat strategies like using a search tool or doing iterative summaries, achieving over 90% accuracy where others failed[28].
These results suggest that RLMs are not just a gimmick to handle long text , they actively improve the quality of reasoning. By giving the model an active role in deciding what to read and when, we get better outcomes than forcing the model to digest a huge input in a single sitting.
Why This Matters: Towards Unlimited Context AI
The advent of Recursive Language Models is a big deal for anyone excited about the future of AI capabilities. Here’s why RLMs could be a game-changer:
· Virtually Unlimited Context: RLMs break the shackles of fixed context windows. Need to feed 100 million tokens to the AI? No problem , the RLM will read it piece by piece. This opens the door to applications that were previously unthinkable, like an AI assistant that can truly read and analyze entire books, massive legal documents, or years of archival data in one session.
· Better Long-Horizon Reasoning: Long conversations or ongoing tasks where an AI needs to remember earlier events (say, an AI agent working with you throughout the day) stand to benefit. With RLMs, the AI can maintain an external memory of everything that’s happened and recall details when needed, without suffering context rot. It no longer has to fit the whole conversation history into a prompt at each turn , it can search and retrieve relevant bits as needed. This could make AI much more coherent and reliable over long interactions[34][35].
· Accuracy on Complex Tasks: As shown in the research, RLMs significantly boost accuracy on tasks that require combining information from many different parts of the input[28]. This is vital for tasks like research analysis, where answers are not localized to one paragraph but spread across many sources. RLMs excel at information aggregation , they can gather pieces from here and there and put them together correctly.
· Efficiency and Focus: RLMs encourage a model to focus its attention only where needed. This aligns with how humans approach information overload by skimming and drilling down selectively. By not reading irrelevant stuff, the AI saves time and cost. In technical terms, RLMs perform a form of context engineering automatically , they decide what subset of the text to pay attention to, rather than blindly consuming everything[36][37].
· General-Purpose Method: Importantly, RLM is a strategy, not a specialized solution for one domain. The same RLM approach could be used for code (imagine an AI coding assistant that can handle an entire codebase by opening files as needed, rather than hitting a file-size limit)[38], for vision (processing huge image datasets by tiling and searching), or any modality that can be chunked. The flexibility of using a programming environment means the model could, for example, run SQL queries on a database, or execute math on data, as part of its process. The context doesn’t even have to be plain text , anything that can be loaded into memory and queried with tools could be integrated[39]. This blurs the line between a pure language model and a more general AI agent with a working memory.
Looking Ahead: RLMs and the Future of AI Reasoning
Recursive Language Models represent a fresh direction in making AI systems more scalable and intelligent at inference time (i.e., when they’re actually being used, not just during training). The research community is excited about RLMs, considering them likely the next milestone in AI reasoning and tool use[40]. In recent years, we saw leaps in capability from techniques like Chain-of-Thought prompting (getting models to reason step-by-step) and ReAct (integrating reasoning and acting, e.g., using tools). RLMs could be the next such leap, adding an axis of scale: the ability to reason over truly vast context by organizing the work into a recursive process[40].
Of course, this is just the beginning. The current RLM implementations, while effective, are somewhat hacky in that they use off-the-shelf models (GPT-5, etc.) with prompting to make them act recursively. There’s lots of room to improve. Future research might train models explicitly to be good at this kind of recursive planning and reading[41]. If today’s RLM is like giving the model a new superpower, tomorrow’s models might be born with that superpower built-in and optimized. We might see specialized techniques for making recursive calls more efficient (like running many sub-calls in parallel, or having the model decide when to spawn multiple helpers at once)[42]. There is also the question of deeper recursion , the current experiments mostly limited to one level of sub-calls (depth=1). Could we have sub-models that themselves call sub-sub-models (depth=2) and so on, creating a deeper hierarchy for extremely complex tasks? Early results were strong with just one level, but perhaps some problems will benefit from multi-level recursion in the future[43].
Another exciting prospect is combining RLMs with training in a feedback loop. The sequence of actions a RLM takes (which parts to read, what questions to ask) can be seen as a form of reasoning trajectory[44]. Researchers speculate that we could apply techniques like reinforcement learning (RL) or imitation learning to teach models to produce better recursive strategies over time[45]. In other words, we might train the model not just to give a final answer, but to excel at the whole process of how it finds that answer in a large context. This could further boost performance and reliability.
In summary, Recursive Language Models transform how an AI interacts with information. Instead of drowning in data, the AI learns to surf it , navigating through an ocean of text by charting its own course. For AI enthusiasts and beginners trying to grasp this concept, think of RLMs as giving an AI the abilities of a smart librarian or a data detective: it doesn’t memorize everything at once, but it knows where to look, how to break a big job into small tasks, and how to put the pieces together. This approach helps the AI overcome the long-standing context limit problem and significantly improves its reasoning on large-scale tasks.
The development of RLMs is a compelling example of how researchers are pushing the boundaries of what AI can do without simply making the neural networks larger or the hardware more powerful. By reimagining the inference process, RLMs achieve more with the models we already have. It’s a paradigm shift from brute-force reading to reflective, controlled exploration of data. As this technique matures, we can expect AI systems that handle increasingly ambitious assignments , reading whole libraries, continuously learning from streams of data, or managing complex projects , all by recursively calling on themselves in a thoughtful way.
In essence, RLMs let AI “read less, but think more.” They mark a step towards AI that is not just bigger in memory, but smarter in how it uses that memory. And for anyone eager to see AI tackle ever larger problems, that’s a thrilling development[46][38].
References: Recursive Language Models (Zhang et al. 2025)[29][27]; Medium explainer by S. Jain[23][2]; Author’s blog (Alex L. Zhang)[28][47]; Anthropic context engineering post[36].
[1] [10] [19] [27] [29] [30] [31] [32] [33] [41] [42] [43] [44] Recursive Language Models https://arxiv.org/html/2512.24601v1
[2] [3] [4] [5] [6] [7] [8] [9] [11] [12] [13] [15] [16] [17] [18] [20] [21] [22] [23] [24] [25] [26] Recursive Language Models explained from first principles | by shashank Jain | Jan, 2026 | Medium https://medium.com/@jain.sm/recursive-language-models-explained-from-first-principles-ddaf73b78632
[14] [28] [34] [35] [39] [40] [45] [47] Recursive Language Models | Alex L. Zhang https://alexzhang13.github.io/blog/2025/rlm/
[36] [37] Effective context engineering for AI agents \ Anthropic https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
[38] [46] Why the Smartest LLMs Are Learning to Read Less | by Digvijay Mahapatra | Jan, 2026 | Towards AI https://pub.towardsai.net/why-the-smartest-llms-are-learning-to-read-less-17ab0a0166c2?gi=afea8fd2a201
Comments
Loading comments…