
Photo by Benjamin Voros on Unsplash
Over the past few months, tech giants like OpenAI, Google, Microsoft, Facebook, and others have significantly increased their development and release of large language models (LLMs). The release of ChatGPT, in particular, sparked a wave of new releases that took the world by storm. However, the rapid release of so many models by multiple companies in such a short period can make it difficult to navigate and compare them effectively. To address this issue, this article explores the latest advancements in large language models and provides a comprehensive overview of the newest and most advanced models currently available. Specifically, the overview will cover common information about the models and how to use them, whether they are open source or not, and whether they can be used commercially.
1 — ChatGPT
ChatGPT is a specific implementation of the GPT model that has been fine-tuned to perform well on conversational tasks, such as chatbot-style interactions, which was developed by OpenAI. GPT-3 (Generative Pre-trained Transformer 3) is a neural network-based language model that is trained on a massive amount of text data, allowing it to generate coherent and sophisticated language outputs. ChatGpt was trained using Reinforcement Learning from Human Feedback (RLHF), which is a machine-learning approach where an agent learns from feedback given by a human supervisor to improve its performance in a task. ChatGPT is a commercial product that can be used for various language tasks, including text generation, chatbot development, and content creation. It can be integrated with existing applications and platforms, such as social media, messaging apps, and e-commerce websites, to provide conversational interfaces and personalized experiences to users. The GPT-4 architecture is currently under development and is expected to be released in the near future. While there is limited information available about its capabilities and features, it is expected to build upon the advancements made by GPT-3 and offers even more sophisticated language processing capabilities. Both GPT-3 and ChatGPT can be used commercially, but their usage comes with certain limitations and pricing. OpenAI offers access to GPT-3 through their API, with usage fees based on the number of requests and the amount of data processed. However, OpenAI does offer some free access to GPT-3 through their API for non-commercial use. We can also use their WebUI for tasks like code generation, text generation, and so on.
2 — LLaMA
The LLaMA Model is an auto-regressive language model, based on the transformer architecture, developed by The FAIR team of Meta AI. The model was trained between December 2022 and February 2023, and it comes in different sizes: 7B, 13B, 33B, and 65B parameters. The primary intended users of the model are researchers in natural language processing, machine learning, and artificial intelligence. LLaMA is licensed for non-commercial use only. One of the most relevant factors for which model performance may vary in which language is used. The model has not been trained with human feedback, and can thus generate toxic or offensive content, incorrect information, or generally unhelpful answers The model was evaluated on several benchmarks and trained using various sources of data CCNet [67%], C4 [15%], GitHub [4.5%], Wikipedia [4.5%], Books [4.5%], ArXiv [2.5%], Stack Exchange[2%]. The paper provides additional information about the LLaMA Model. To access the model, you must apply for permission through the link provided.
3 — StableLM
StableLM is a new open-source language model suite released by Stability AI. The model is available in an alpha version with 3 billion and 7 billion parameters, and 15 billion to 65 billion parameter models to follow. The StableLM suite of models can generate text and code and will power a range of downstream applications. The model is transparent, open, and scalable, making it accessible to all. StableLM-alpha is trained on a new experimental dataset built on The Pile, which is an 825 GB diverse, open-source language modeling data set that consists of 22 smaller, high-quality datasets combined together. These models are intended for research use only and are released under a noncommercial CC BY-NC-SA 4.0 license. They open-source their models to promote transparency and foster trust. We can run the model ourselves using the Hugging face:
from transformers import AutoModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList
tokenizer = AutoTokenizer.from_pretrained("StabilityAI/stablelm-tuned-alpha-7b")
model = AutoModelForCausalLM.from_pretrained("StabilityAI/stablelm-tuned-alpha-7b")
model.half().cuda()
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [50278, 50279, 50277, 1, 0]
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
system_prompt = """<|SYSTEM|># StableLM Tuned (Alpha version)
- StableLM is a helpful and harmless open-source AI language model developed by StabilityAI.
- StableLM is excited to be able to help the user, but will refuse to do anything that could be considered harmful to the user.
- StableLM is more than just an information source, StableLM is also able to write poetry, short stories, and make jokes.
- StableLM will refuse to participate in anything that could harm a human.
"""
prompt = f"{system_prompt}<|USER|>What's your mood today?<|ASSISTANT|>"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
tokens = model.generate(
**inputs,
max_new_tokens=64,
temperature=0.7,
do_sample=True,
stopping_criteria=StoppingCriteriaList([StopOnTokens()])
)
print(tokenizer.decode(tokens[0], skip_special_tokens=True))
However, the model is still quite large and requires a significant amount of RAM, making it difficult to load on platforms like Google Colab’s free version.
4 — Dolly
Dolly is a large language model created by Databricks, trained on their machine learning platform, and licensed for commercial use. Derived from EleutherAI’s Pythia-12b and fine-tuned on a dataset of ~15K instruction/response records generated by Databricks employees. However, it is not a state-of-the-art generative language model and has limitations in performance, such as struggling with syntactically complex prompts, programming problems, mathematical operations, and open-ended question answering. The model is available on Hugging Face and can be used using the following code:
import torch
from transformers import pipeline
generate_text = pipeline(model="databricks/dolly-v2-12b", torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto")
res = generate_text("Explain to me the difference between nuclear fission and fusion.")
print(res[0]["generated_text"])
Or can be downloaded locally using the following code:
import torch
from instruct_pipeline import InstructionTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-12b", padding_side="left")
model = AutoModelForCausalLM.from_pretrained("databricks/dolly-v2-12b", device_map="auto", torch_dtype=torch.bfloat16)
generate_text = InstructionTextGenerationPipeline(model=model, tokenizer=tokenizer)p
However, the model is also quite large and requires a significant amount of RAM, making it difficult to load on platforms like Google Colab’s free version.
5 — Gpt4all
GPT4All is an Apache-2 licensed chatbot developed by a team of researchers, including Yuvanesh Anand and Benjamin M. Schmidt. The model was trained on a massive curated corpus of assistant interactions, which included word problems, multi-turn dialogue, code, poems, songs, and stories. The team used several publicly available datasets and curated their own set of prompts to build the GPT4All-J dataset, which is a superset of the original 400k points GPT4All dataset. GPT4All-J can be used commercially and is capable of writing poems, songs, and plays with increased competence. The training data curation procedure, training code, and final model weights are openly released to promote open research and reproducibility. Finally, the model comes with Python bindings and a Chat UI to a quantized 4-bit version of GPT4All-J, which allows virtually anyone to run the model on CPU. We can download the model locally and have a local ChatGPT-like service that is free and always exesible to us. Here is the link to theGithub repository.
6 — Alpacha
The Stanford Alpaca project has developed an instruction-following language model that was fine-tuned on a dataset of 52K examples using a technique called Self-Instruct. The project provides the data, the code for generating the data, and the code for fine-tuning the model. The current Alpaca model is not yet safe and harmless, so it is only intended and licensed for research use. The data is licensed under CC BY NC 4.0, and models trained using the dataset should not be used outside of research purposes. The dataset provided by the Stanford Alpaca project contains instructions, input, and output fields. The input field provides context or additional information for the task described in the instruction, while the output field contains the answer generated by text-davinci-003 (Text-davinci-003 is one of the language models created by OpenAI, which is part of the GPT-3 family of models). The project intends to release the model weights if given permission by the creators of LLaMA. The data generation process and dataset are discussed in detail in the project’s release blog post.
7 — Vicuna
Vicuna-13B, an open-source chatbot developed by a team of researchers from UC Berkeley, CMU, Stanford, MBZUAI, and UC San Diego. The chatbot was trained by fine-tuning LLaMA on user-shared conversations collected from ShareGPT. There is a 13b and 7b parameter models that are available on Huggingface. The authors claim that Vicuna-13B achieves more than 90% quality of OpenAI ChatGPT and Google Bard while outperforming other models like LLaMA and Stanford Alpaca in more than 90% of cases. The code and weights, along with an online demo, are publicly available for non-commercial use. To use the model you need to install LLaMA weights first and convert them into hugging face weights to be able to use this model.
8 — Koala
Koala was created by a team of researchers led by Xinyang Geng. The model was trained by fine-tuning Meta’s LLaMA on a carefully curated dataset of dialogue data collected from the web, which includes interaction with highly capable closed-source models such as ChatGPT, Bingchat, and so on. The results of a user study comparing Koala with ChatGPT and Stanford’s Alpaca showed that Koala can effectively respond to a variety of user queries, generating responses that are often preferred over Alpaca and tied with ChatGPT in over half of the cases. Koala has the same licensing terms as the LLaMA model and is not permitted for commercial use.
Table Summary
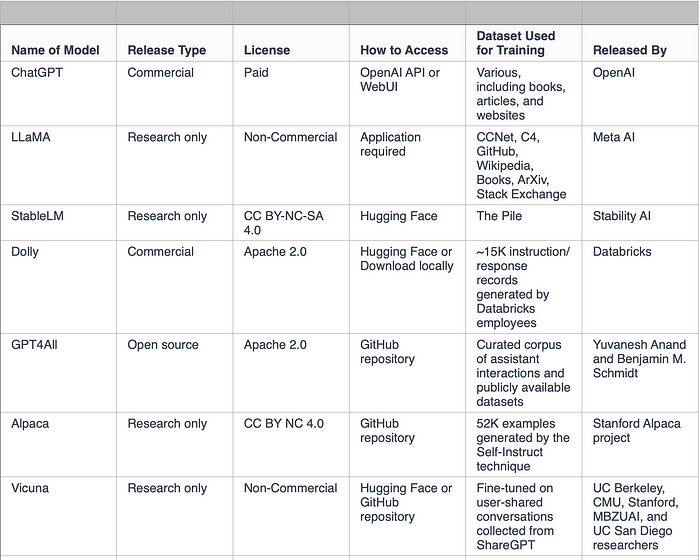
Image by the author
Conclusion
Recent advances in large language models have revolutionized the field of natural language processing, making it possible to generate high-quality human-like text with remarkable accuracy. However, the recent release of multiple models has made it increasingly difficult to keep track of the changes and understand how to use each one effectively. Fortunately, with the addition of the table provided in this article, you can now get a better overview of the different choices available and their specific capabilities. This table serves as a useful guide that can help researchers, developers, and businesses alike navigate the rapidly evolving landscape of large language models. I hope that you found this article useful and helped you get a better overview of the different Large language models out there and how to use them ❤ If you would like to support other writers and me in creating such content, make sure to subscribe to medium premium using this link. If this article provided you with the solution, you were seeking, why not express your appreciation by getting me a coffee using my personal account? Your support would be greatly appreciated, and I would love the opportunity to connect with you and hear about your experience ❤.
Comments
Loading comments…