What is MultiIndex in Pandas?
A MultiIndex is a hierarchical index that allows you to have multiple levels of indexing in your data. In Pandas, you can create a MultiIndex on both rows and columns of a DataFrame.
Why flatten MultiIndex columns and rows?
MultiIndex columns and rows can be challenging to work with, especially when it comes to data manipulation, analysis, and visualization. By flattening MultiIndex columns and rows, you can simplify your DataFrame and make it easier to work with.
How to flatten MultiIndex columns and rows?
You can use the reset_index() method to flatten MultiIndex columns and rows in a Pandas DataFrame. The reset_index() method moves all the row or column index levels to columns, resulting in a flattened DataFrame. You can then use the rename() method to give meaningful names to the new columns.
👉 Check out some Python libraries for data analysis:
Key Python Libraries for Data Analysis and Code examples
Here’s some examples to illustrate how to flatten MultiIndex columns and rows:
Data in this article can be downloaded here.
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
fruits = pd.read_table('../Data/fruit_data_with_colors.txt')
fruits.head()
When using groupby
df = fruits.groupby(['fruit_label', 'fruit_name', 'fruit_subtype'])[['mass', 'width', 'height',
'color_score']].mean()
df.head()
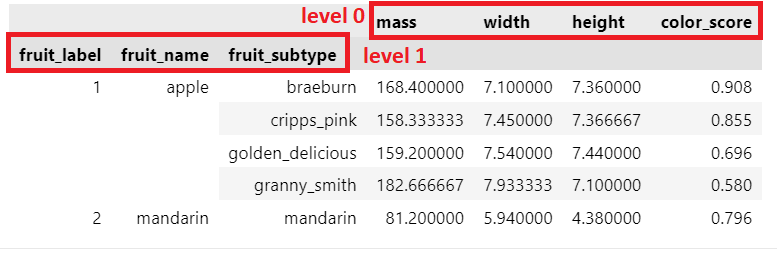
df.reset_index([0, 1, 2])
df = df.reset_index(['fruit_label','fruit_name','fruit_subtype'])
df.head()
💡 Speed up your blog creation with DifferAI.
Available for free exclusively on the free and open blogging platform, Differ.
Multiple levels of indexing
import pandas as pd
# create a sample DataFrame with MultiIndex columns and rows
data = {('A', 'B'): [1, 2, 3], ('A', 'C'): [4, 5, 6], ('D', 'E'): [7, 8, 9]}
df = pd.DataFrame(data, index=['X', 'Y', 'Z'])
# print the original DataFrame
df.head()
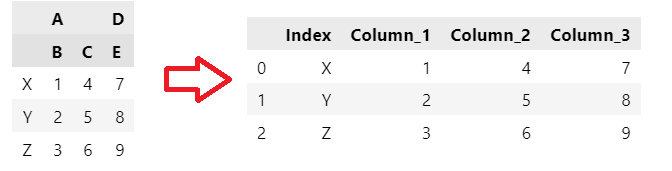
# flatten MultiIndex columns
df_flat_cols = df.reset_index()
df_flat_cols.columns = ['Index', 'Column_1', 'Column_2', 'Column_3']
# print the flattened DataFrame with MultiIndex rows and flattened columns
df_flat_cols.head()
Flatten a specific level
import pandas as pd
# create a sample DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Gender': ['F', 'M', 'M'],
'Height': [165, 180, 175],
'Weight': [60, 80, 70]}
df = pd.DataFrame(data)
df.head()
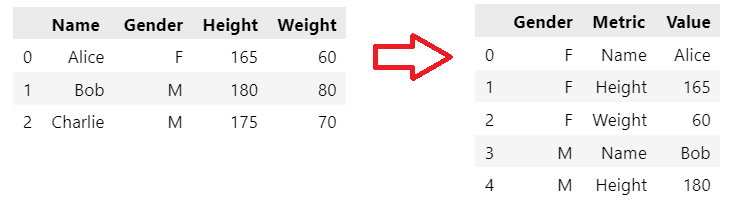
# set the index to 'Gender' column
df.set_index('Gender', inplace=True)
# stack the first level of row index to column index
df_stacked = df.stack(level=0)
# rename the columns
df_stacked = df_stacked.rename_axis(index=['Gender', 'Metric']).reset_index(name='Value')
# print the flattened DataFrame
df_stacked.head()
Full code here.
Thanks for reading!
Comments
Loading comments…