
In the world of Product-Led Growth (PLG), where elegant product design drives customer adoption, a company's website is often the entry and arguably the most critical point for the product experience.
In many ways, this is why company websites for product-led companies are slowly starting to merge with the product experience.
Let me explain.
Say a user visits your website and registers for an online event. At this time, they provide some information about themselves and maybe even set up their profile to view pre and post-event details.
After the event, they then decide to sign up for a product trial. During the product trial signup, do you ask for the details again, or do you recognize the same user by their email and seamlessly drop them into your product experience with the least amount of friction?
Further, is the onboarding experience customized for that user based on the information they had already provided along with their intent signals when they visited your website?
A proper PLG stack should enable companies to build a seamless user journey from visiting the website to trying the product and finally using the product.
We have been building this for our startup, and in this article, I will go over some of the key features of a PLG stack and some best practices.
In my experience, there are three main requirements for an efficient PLG technology stack:
-
The ability to have single signup and sign-in experience across all company web properties.
-
The ability to capture all details around users' behavior across multiple channels (website, app, etc.).
-
The ability to act on that information to customize the user's experience along the way.
As an icing on the cake, your company should be able to engage with your users in real-time if and when they have an issue/question, and your company should react to their requests and intent signals promptly and efficiently.
Let's look at each of these requirements and look at the architecture and some choices.
1. Presentation layer: The website
In my past experiences, I have seen many websites that rely on an architecture where the code and content are tightly coupled. This architecture becomes problematic when your site has more pages and additional languages and eventually starts having mini apps, for example, a community portal, an event portal, etc.
So we decided to use a JAM stack architecture that talks to a headless CMS. This allowed us to have a separation of code and content. The developers use their IDE of choice and can make code changes directly into the code repository, and with our CI/CD pipeline, we can make code releases as often as we want.
On the other hand, the content writers work directly in a WYSIWYG headless content management system that triggers a website build in our CI/CD pipeline so any changes in code or content can deploy to our dev, staging and eventually to our prod site without any downtime.
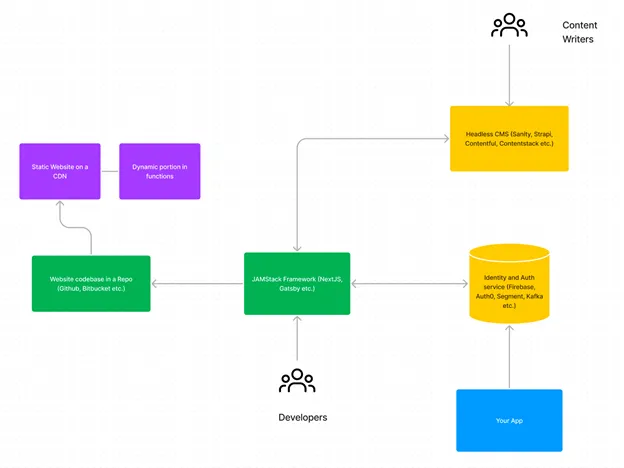
2. Data layer: User Identity and Auth
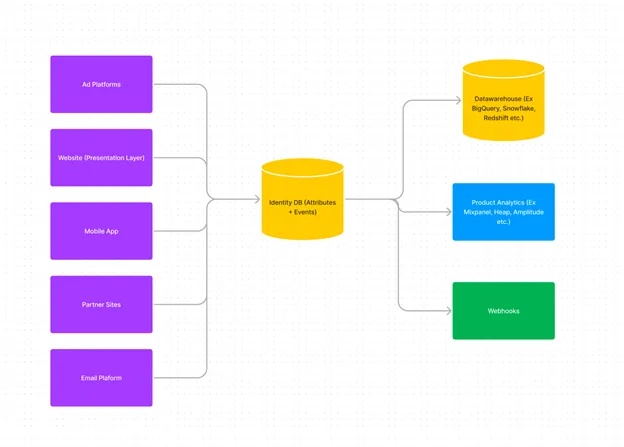
Early on, we decided this would be the glue between users coming to the company website and those signing up and using our product. From a user identity standpoint, we decided we needed to have a way to manage both user attributes (for example, name, email, member type, etc.) and user actions (did they read a blog, did they attend an event, did they sign up for a trial, etc.).
In several ways, think of this as a user object with a time-series database for events associated with the user.
There are several ways to build user identity and events databases, but we also wanted a seamless authentication experience for signup and sign-in, which gave us the flexibility to do single sign-on across multiple "apps" on our website. So we ended up building our own solution for identity and an off-the-shelf solution for authentication that currently allows us to manage user identity in one place with the ability to view and react to user events through a workflow.
The image below gives a high-level overview of this data architecture and some choices available off the shelf.
3. Orchestration layer
Finally, we wanted an efficient workflow system that allowed us to interact with our users through multiple channels like email, SMS, etc. Initially, we did this with an open-source Lambda function-like platform that allowed us to listen to webhook events and trigger actions through APIs like sending emails through Sendgrid.
More recently, we have started to build our workflow for our customers and us, which is far more flexible and adaptable.
For real-time communication with our users, we use one of our product features, PLuG. The PLuG is enabled directly into our logged-in community experience. This allows us to interact with our customers in real time.
Every conversation is then connected to our user identity database on one side and our product features and capabilities on the other. This means as and when issues and questions arise, our employees can help our users in a timely manner.
Summary
PLG has merged the experience for users visiting a company's website, browsing through the content, signing up for trials, and eventually driving growth and adoption for users. In this world, the technology stack should be decoupled and efficient to react to users and customize their experience with the least amount of friction.
There are several choices for technology to build this architecture, but the key ones include designing around the user identity and authentication, the presentation, and finally, the orchestration layers.
Comments
Loading comments…