
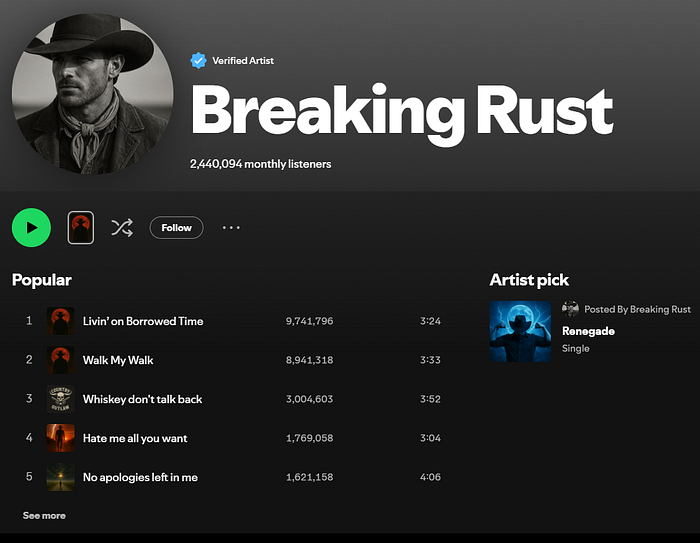
Who had artists entirely generated by AI going viral on Spotify**** on their bingo card for 2025? Yeah, me neither. When I say “generated”, I’m talking everything from band promo shots, to members’ backgrounds, and instruments and vocals.
The Velvet Sundown went viral recently, as did Aventhis — who has over a million monthly listeners. Heck, a song by the AI-created act Breaking Rust was topping the U.S. Billboard Country Digital Song Sales chart in November this year. Breaking Rust has a whopping 2.5 million monthly listeners on Spotify.
Needless to say, this makes for a very lucrative business model. 👀
In 2025, Spotify pays artists roughly $0.003–$0.005 per stream, meaning 1 million streams earns about $3,000–$5,000, with most of that flowing to rights holders….but consider that GenAI-for-music tools like Suno**** and Udio cost under $10/month, or $30–$50/month for commercial rights, and that you’d have zero traditional expenses like studios, bands, or touring. In that context, a single AI-generated track hitting ~10 million streams could gross $30,000–$50,000, minus trivial distributor fees — an insanely low-cost, high-scale setup.
And that’s just Spotify.
So this piqued my curiosity. Sure, perhaps GenAI for music is more accessible than ever — but creating AI music that not only sounds polished but also earns plays, likes, and real listener engagement? That’s no easy task. For every AI-driven success story, there are thousands of boring Suno-created “lofi” playlists sitting at paltry 25–50 views on Spotify or YouTube.
What, then, are the standout AI artists — more accurately, the people behind them — doing differently? Which real artists do they want to sound like? Can we find out, acoustically speaking, how these algorithmic creations compare to the history of human-made music?
To explore that, I focused on three of the most prominent AI artists — Velvet Sundown, Breaking Rust, and Aventhis — collecting 30-second Spotify previews + lyrics (via a Bright Data proxy once I started getting HTTP 429's), breaking down their acoustic “fingerprint” using OpenL3, and comparing them against Spotify’s Top 2000 songs (up to 2020) + Spotify’s top 10 for each of their official (non-hidden) genres (obtained via Volt.fm) to see where their sound might sit in the broader musical landscape.
GitHub - marl/openl3: OpenL3: Open-source deep audio and image embeddings
Residential Proxies Trusted by Fortune 500 Companies - Free Trial
Here’s what I found. If you’d like to read at your own pace, here’s the Table of Contents. Enjoy!
Table of Contents
2. Repetitive Catalogues, Optimized for Recommendation Engines
3. Simple, Emotionally Nonexistent Lyrics.
- Velvet Sundown: Aesthetic Without Substance
- Aventhis: Performative Masculine Trauma
- Breaking Rust: Simple, Repetitive, and Chorus-Forward
4. The Bigger Pattern…is Depressing.
5. Methodology
AI Music Isn’t Doing Anything New — It’s Banking on What Already Works.
First of all, I should mention that all of these artists sound….perfect. There is no obvious artifacting, vocals being off key, instruments tuned incorrectly or cutting in/out abruptly. Whatever software they’re using to generate instruments and vocals — it’s working just fine. But this study is about far more than simple correctness.
You’d think that artists generated programmatically — yes, I know how AI works; I’m generalizing — would gravitate toward tightly defined, algorithmic genres (EDM substyles, algorithm-friendly lo-fi, etc.), or swing the other way entirely and lean into something aggressively experimental. After all, if you have an AI model at your fingertips and don’t try to push boundaries, what are you even doing? 😅
But that’s not what shows up in the data. Rather than sounding novel or genre-breaking, the most successful AI artists consistently map onto a very familiar musical space: melody-forward, mid-tempo, harmony-rich songs that sit comfortably alongside decades of mainstream, human-made music, and are guaranteed to get heavy airplay.
Here’s what scored a ~0.685 similarity according to my code.
In fact, let’s start with The Velvet Sundown.
AI Artist #1 — The Velvet Sundown

Sonically, they’re going hard for a warm, soft-focus, 1970s-era rock aesthetic — and the data backs that up almost embarrassingly well. Across 39 query tracks, the closest real-world matches are dominated by The Beatles and Fleetwood Mac, which land as the top two most similar artists overall. The Beatles take the top spot with a final similarity score of ~0.68, appearing in 37 out of 39 query songs, while Fleetwood Mac follows closely behind at ~0.66, matching 38 out of 39 queries. These aren’t marginal hits either, tracks like Here Comes the Sun, In My Life, Landslide, and Rhiannon repeatedly surface as high-similarity neighbors
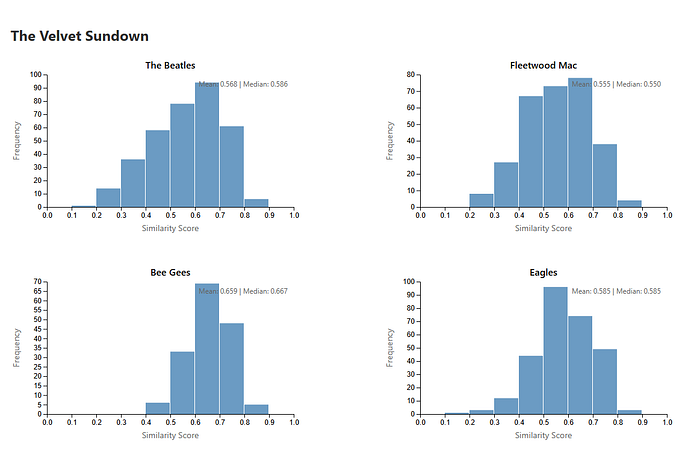
Similarity Score (X-axis): Cosine similarity between each AI artist track and historical tracks from the artist. Scores range from 0 to 1, where higher values indicate greater similarity.Frequency (Y-axis): The number of track comparisons that fall into each similarity score range. Higher bars mean more tracks matched at that similarity level. A distribution skewed toward higher scores indicates consistent similarity across many tracks.
What’s interesting is that this alignment matches subjective listening almost perfectly. While their harmonies, pacing, and production texture feel straight out of the mid-70s “warm, analog” playbook (Fleetwood Mac, The Eagles), The Velvet Sundown’s vocals and melodic swells sound exactly like late-period Beatles balladry.
Like I said, whatever model + prompt they’re using isn’t inventing a new genre — it’s triangulating toward one of the safest, most historically successful regions of the musical embedding space.
And it doesn’t stop there. Their next tier of similar artists includes The Eagles, Bee Gees, going on to Queen, Dire Straits, Neil Young, and even modern successors like Coldplay and John Mayer — all artists known for emotionally legible songwriting, strong melodic hooks, and broad mainstream appeal.
Jesus. The Velvet Sundown is basically a statistically optimal blend of classic rock lineage, factory-made for familiarity. 😅
“Statistically optimal” is a great way to describe these artists, actually. None of them do anything wild, original, or creative. They’re AI-generated comfort food for your ears.
AI Artist #2 — Aventhis
If The Velvet Sundown felt like a near-perfect acoustic cosplay of a specific era and band, Aventhis is more diffuse. The model has no trouble identifying where Aventhis lives — firmly within modern country and Americana — but it’s noticeably less decisive about who they’re trying to sound like.
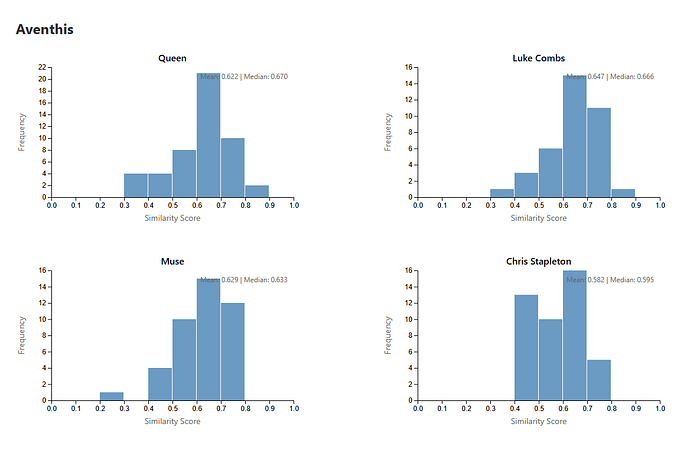
On paper, the genre match is strong. Across all songs Aventhis has on Spotify, they consistently map to contemporary country artists like Luke Combs, Morgan Wallen, and Chris Stapleton, all of whom appear in the top tier of results with solid similarity scores and high cross-query consistency.
So the system is correctly picking up on the hallmarks of modern country production: mid-tempo arrangements, prominent acoustic guitars, restrained percussion, and vocal-first mixes.
Where things get interesting is that no single artist fully dominates the similarity space the way Fleetwood Mac and The Beatles did for Velvet Sundown. Artists like Creedence Clearwater Revival, Queen, and even Muse creep into the top results — not because Aventhis sounds like them stylistically, but because some of these representative songs share broad acoustic properties: strong melodic arcs, clear harmonic structure, and emotionally legible song forms.
My theory is that the Aventhis project feels more like someone playing around with the software, and those early “feeling out” era tracks skew the analysis. Their more recent songs crystallize fairly well.
Regardless of era, Chris Stapleton shows up as the clearest vocal anchor — which aligns well with Aventhis’ branding as an “outlaw country” act.
Stapleton’s influence appears more in timbre: the gravel, the sustained notes, the emotional weight carried by the voice rather than the arrangement.
AI Artist #3 — Breaking Rust
Speaking of outlaw country…we have Breaking Rust which seems to exclusively create a monotonous sound that isn’t only mimicking the genre, it’s optimizing for a radio-friendly, familiar, “epic” image of it, engineered to sit dead-center in today’s casual-listener Spotify ecosystem.
This is a commercially attractive interpretation of what rebel/outlaw country music is supposed to be. (And that doesn’t have that much of an outlaw in there, unsurprisingly. 😅)
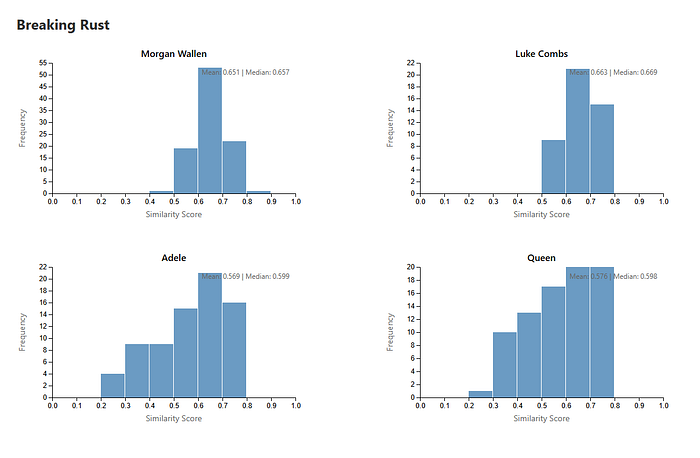
Morgan Wallen dominates the comparison set with a final score of ~0.71 and a 100% consistency ratio, meaning every single Breaking Rust track consistently mapped to Wallen’s catalog with high similarity
Luke Combs follows closely behind, again with perfect consistency.
Adele shows up here because of the clean, soaring vocals, and Queen does so because of the “thump & clap” routine that Breaking Rust seems to employ frequently.
There’s also very little experimentation here. Classic country influences (Cash, Jennings, early outlaw archetypes) do show up in the data, but barely surface acoustically. Even older rock-adjacent matches like Creedence Clearwater Revival appear only as secondary signals. After The Velvet Sundown, Breaking Rust is easily the most “engineered” sound — created not to reinvent the country genre but almost like it’s trying too hard to win at it, by anchoring itself squarely to the most commercially successful sound of the past decade.
And based on both chart performance and these similarity scores, that strategy appears to be working. Here’s another ~0.6 similarity match. While Breaking Rust is topping Billboard charts, Bryan Elijah Smith — while still successful — isn’t.
Breaking Rust is the perfect opportunity to talk about another big problem with these artists — they’re far too monotonous.
Repetitive Catalogues, Optimized for Recommendation Engines
Up to this point, we’ve been asking a fairly intuitive question: which real artists do these AI projects sound like? But there’s another, arguably more revealing angle here — how similar an AI artist’s songs are to each other.
To answer that, I ran the same embedding pipeline again, but this time comparing each AI Artist track against every other track from the same artist, producing three full intra-artist similarity matrices.
Conceptually, this tells us how tightly clustered the catalog is in embedding space — whether the artist has a recognizable sonic “center,” or whether the songs scatter across different musical regions.
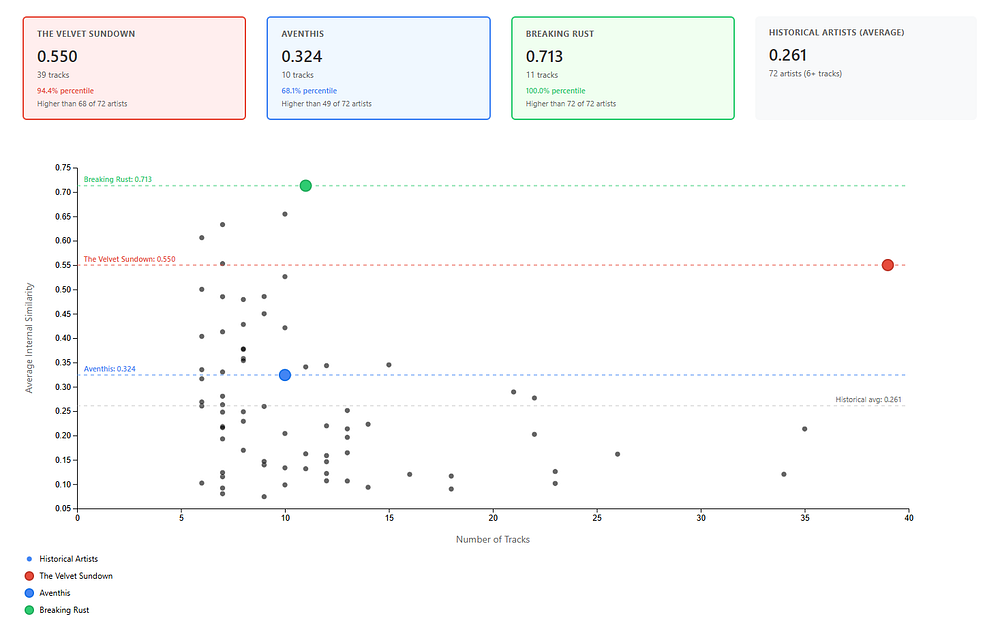
If you were wondering, the artists/data points with the most variation in their internal catalogues (bottom right) here are Queen (0.120), David Bowie (0.162), and The Beatles (0.213). The least (top left) are Kensington (0.655), Doe Maar (0.633) and AC/DC (0.606).
The Velvet Sundown are extremely internally consistent. Most track-to-track cosine similarities land in the ~0.6–0.8 range, with many pairs pushing even higher. That’s near-homogeneity in tempo, timbral palette, harmonic structure, and arrangement style. In other words, once you’ve heard 3–4 Velvet Sundown tracks, you’ve essentially heard ’em all.
Breaking Rust is even worse.
Their intra-similarity scores are ridiculously high across the board, with a strong average, a high median, and low variance compared to the other two artists
Even more than Velvet Sundown, almost every Breaking Rust song sounds a lot like every other Breaking Rust song. Close enough that just one song could describe its entire catalog.
This is especially evident in the most similar pairs, where similarities routinely exceed 0.85 — values you’d normally expect from alternate takes, or remixes, not individual songs. Even from the same album. Tempo, instrumentation, vocal tone, and structure are nearly one-dimensional.
Strictly from an algorithmic POV, this explains why Breaking Rust works so well on Spotify: it’s predictable in the best possible way. If you like one song, the Spotify algorithm can safely serve you ten more without risking a skip. From a modeling perspective, it’s also the clearest example of how AI systems naturally converge on a local optimum when the people behind it get lazy — once a sound “works,” it gets reused aggressively unless you’re actively correcting for it.
Depressing, but further proof that rather than artistic intent, these AI musicians seem to have been designed for streaming efficiency — music engineered to sound “right enough” to play to the algorithm of major recommendation engines.
Aventhis is a statistical anomaly here for reasons mentioned before. While it does show lower average similarity and higher variance, including a few pairs that are barely related at all, the issue is that their songs jump genres often, making such analysis misleading.
Lyrics Are Technically Correct, But Emotionally Nonexistent.
Once you strip away production, vocals, and genre cues, lyrics are where artistic intent — or its absence — tends to leak through. This is what actually ties our quantitative results and the “felt experience” together.
So instead of overfitting on rhyme schemes or clever metaphors, I looked at three broad dimensions:
- Lexical & syntactic complexity (how varied and structurally complex the language is)
- Rhyme density & repetition (how “song-like” vs templated the writing feels)
- Sentiment & emotion (what emotional space these songs consistently occupy)
First of all, there’s not much to distinguish these artists in terms of word/sentence sizes or lengths. Breaking Rust has the most words per song, but they’re all pretty uniform.
The patterns that emerge upon deeper analysis though are… telling. If the audio analysis showed that these AI artists sit comfortably inside well-worn musical lanes, the lyric analysis confirms this: across all three artists, the lyrics read less like authored statements and more like statistical averages of their genre.
Velvet Sundown: Aesthetic Without Substance
Their lyrics are the most revealing case because they sound poetic on first pass. There’s no shortage of imagery: “boots in the mud,” “smoke in the sky,” “shadows falling,” “voices whisper,” “marching ghosts”. And War, peace, rebellion, fire, silence — repeated endlessly, rarely developed.
Lines like:
Dust on the windBoots on the groundSmoke in the skyNo peace foundRivers run redThe drums roll slowTell me brother, where do we go?
Sound meaningful if you’re 14, but are basically just symbolic placeholders rather than narrative beats. This is proven by the metrics: Velvet Sundown has low word entropy, short lines, and extremely low readability scores — they’re easily digestible. High TTR (0.61) and longer average word length (~4.1) give the illusion of richness, but the lyrics are syntactically simple and emotionally generic.
Their rhyme density is fairly low, but that’s misleading — this is because their lyrics are sparse by design.
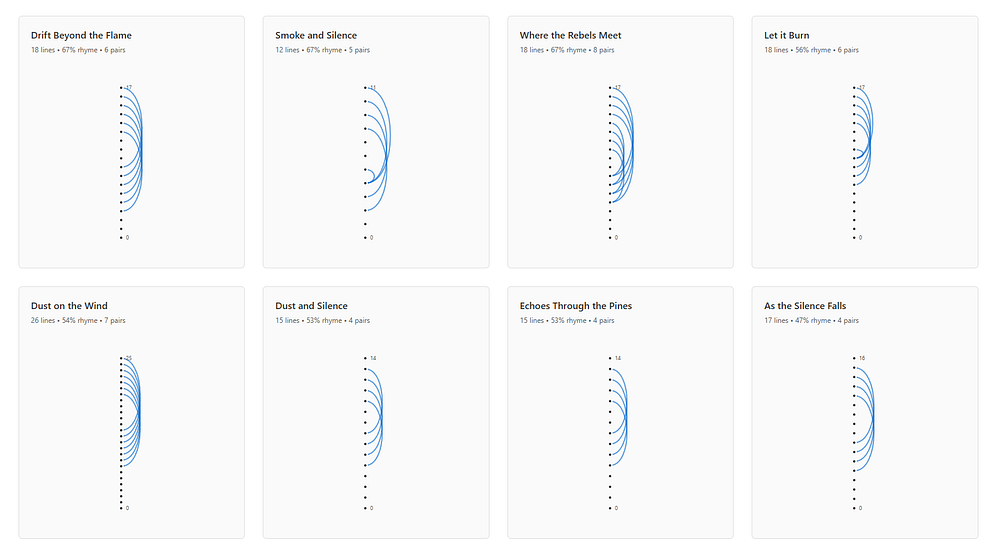
Visual representation of rhyming line pairs for all songs by the selected artist. Lines are shown as dots on a vertical axis, with curved arcs connecting rhyming lines. Thicker arcs indicate more frequent repetitions, revealing chorus recycling patterns and repetition across long distances.
Really, it’s when you actually read the lyrics end-to-end that the cracks show hard:
- Almost every song collapses into very brief (3–4 word) phrases, and the same moral binary: war bad, peace good
- No characters, no storytelling, no deeper narratives or themes, no temporal progression. Oh, and “flag” and “dust” are mentioned a ton, for some reason.
- Choruses recycle very abstract imperatives: “raise your voice,” “don’t look away,” “we won’t fade”
The language gestures at a seriousness without ever committing to specifics. It’s protest music with the protest removed. It’s more like protest aesthetic — a Spotify-ready approximation of “serious rock” that never risks alienating anyone by saying anything precise.
Aventhis: Performative Masculine Trauma
Aventhis is more coherent than Velvet Sundown, but only because it is far less poetic and commits fully to a single archetype: the wounded, defiant outlaw. Every song reinforces the same emotional posturing — mistrust, self-reliance, pain turned inward — to the point that they all blur together.
The lyrics are packed with stock phrases of what could only be called masculine suffering:
“Scars where I never kept my mouth shut” “I ride through hell with my head held high” “I walk with ghosts that don’t disappear” “I don’t kneel or cry”
Unlike Velvet Sundown’s abstract collectivism, Aventhis is intensely first-person — but still vague. The pain is constant. And also (conveniently!), undefined. Abuse, regret, sin, and violence are all implied, and occasionally they’ll include superficial country-genre specifics (whiskey, barbed wire, boots, fire).
Things you’ve heard a thousand times before from a thousand one-note Top 40 Country Billboard artists.
Lexically, Aventhis sits in the middle: moderate vocabulary diversity, average word length, and fairly standard line lengths. But the real signal is consistency. Their MATTR is high and stable, entropy is middling, and syntactic measures are tightly clustered across songs.
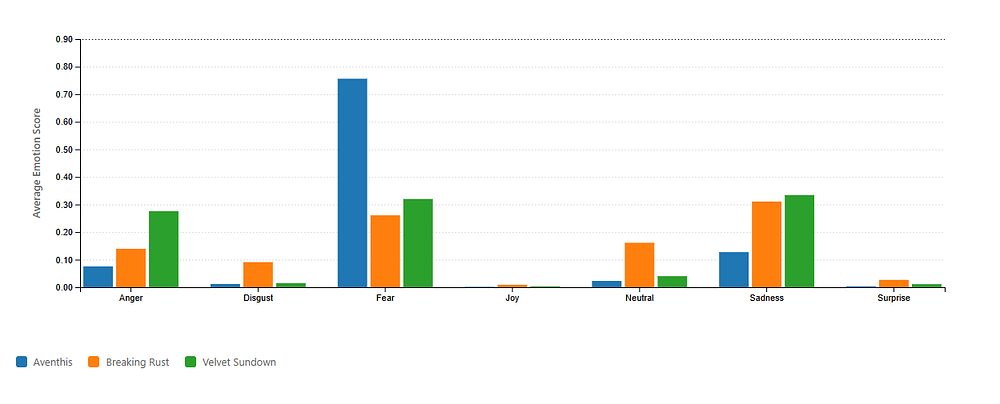
Emotional distribution is comically negative, and arguably, this is engineered for more engagement.
Emotionally, however, Aventhis is almost comically narrow compared to the others: Fear dominates the emotional distribution, but not in a nuanced way — it’s fear as some sort of… aesthetic texture, nothing that ever feels like a lived experience. Even empowerment anthems like “Burn What Held You” resolve into catchy slogans rather than anything deep.
Tension, threat, perseverance, moral conflict. They’re cosplaying as the “gritty outlaw” archetype, and they’re doing it efficiently, repeatedly, and in a way that slots neatly into modern outlaw-country playlists.
Breaking Rust: Simple, Repetitive, and Chorus-Forward
They are the most structurally “song-like” in the traditional sense — and also the least complex.
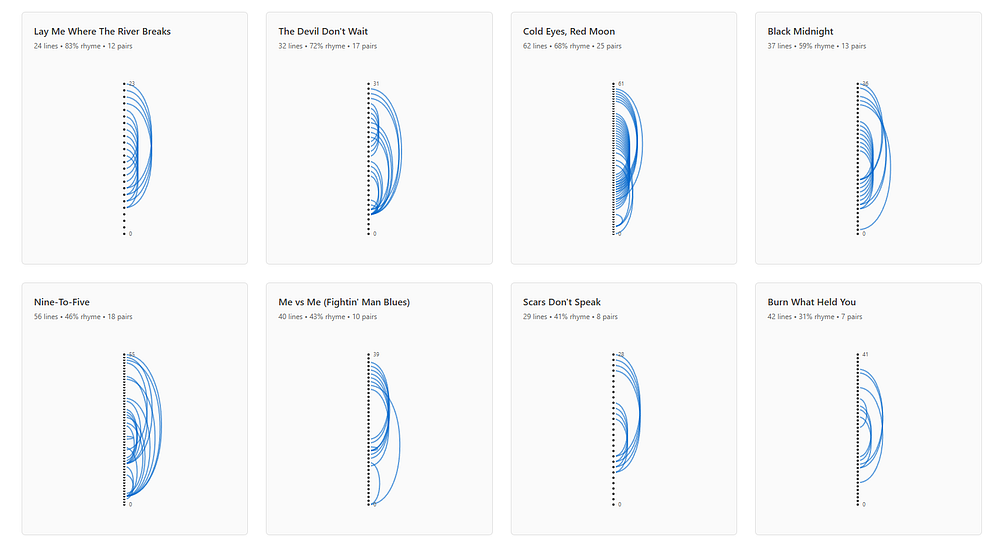
Lexical diversity is the lowest of the three, sentences are shorter, and syntactic depth is shallow. That’s not inherently bad, but it does correlate with what shows up elsewhere: extremely high rhyme and repetition.
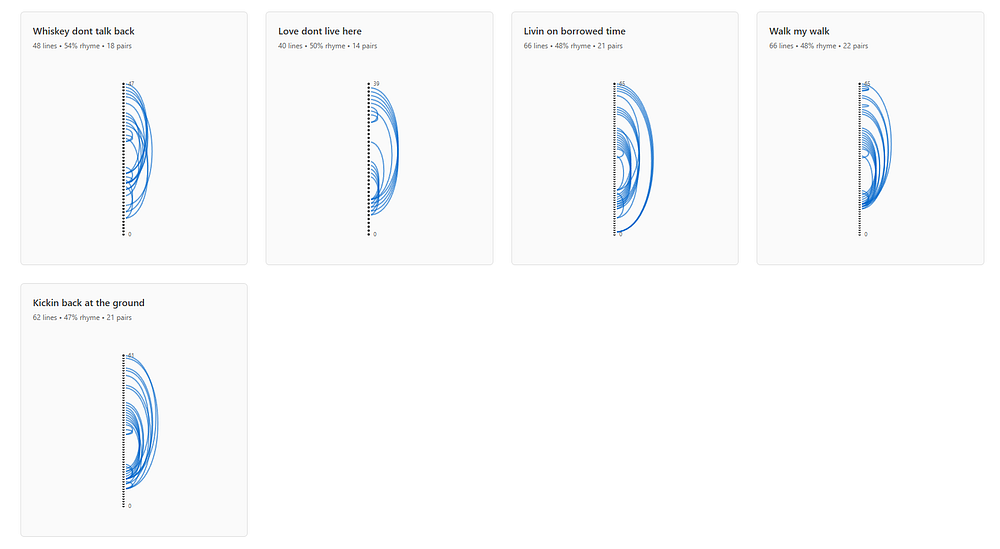
This is music designed to be instantly familiar and easy to latch onto. The sentiment is mostly neutral, with sadness edging out fear and anger. Emotionally, it’s less intense than Aventhis and less layered than Velvet Sundown.
Songs like “Kicking Back at the Ground”, “Livin’ on Borrowed Time”, and “Whiskey Don’t Talk Back” are built from familiar country scaffolding: hard work, pride, scars, drinking, resilience. The imagery is clearer than Velvet Sundown’s and (thankfully!) less theatrical than Aventhis’s, but the emotional range is easily the narrowest here.
You see the same ideas recycled with small lexical swaps:
“Dust on my boots” “Scars that sing” “Pour another glass” “I was born this way”
The metrics show high repetition, high readability, and very stable sentiment — almost aggressively neutral.
There are no lines that reframe a familiar idea or linger on an uncomfortable detail. Everything resolves cleanly into affirmation: keep going, stay true, don’t quit. It’s music designed to be nodded along to, not sat with, or thought about for any length of time.
The Bigger Pattern…is Depressing.
Across all three artists, we keep seeing the same things:
- Low semantic risk; short, uncomplicated words, in short sentences. I imagine this is done for wide appeal as well as not risking their AI vocal generation tripping up on complex words or phrasing.
- High emotional clarity, but extremely low emotional depth
- Heavy reliance on genre signifiers. Again, see: mimicking known archetypes.
- Heavy emphasis on rhyming (combined with #1)
- Lyrics optimized for recognizability, not memorability
These songs all feel like the lyrical equivalent of stock photography — technically correct, emotionally legible, and instantly forgettable.
They don’t challenge the listener. They don’t demand interpretation. They don’t risk failure. And in a streaming economy that rewards familiarity over depth, that might be exactly the point.
More proof that these AI musicians seem to have been designed for maximum playlist compatibility and minimum listener friction.**** Real artists sound like they’re discovering a voice. These sound like systems that already know exactly which one performs best.
That’s everything. If you want to learn about my methodology in detail, read on. Else, click this to go back to the table of contents.
Methodology
To compare AI-generated music with historical human-made songs in a way that’s both scalable and acoustically grounded, I treated this as a representation-learning + similarity search problem rather than a genre-labeling or metadata exercise.
First of all, I collected those 30-second Spotify preview clips for:
- Everything the three AI artists (Velvet Sundown, Breaking Rust, and Aventhis) had on Spotify,
- 10 songs for every track in the Volt.fm charts for Spotify’s 26 official genres
- Everything in the Spotify Top 2000 dataset.
So that’s a total of about ~2500 tracks. Then, I used the Spotify API to programmatically search and find the track URLs + scraped those URLs using Bright Data’s proxies to stop me from getting blocked.
Spotify’s 30-second previews are short, but they’re consistent, legally accessible, and widely used in MIR research — making them a reasonable proxy for a song’s overall sonic fingerprint.
Scraping Spotify preview audio (the slightly hacky part)
My solution was to programmatically go through a list of song + artist name combos like:
{"song": "Let it Burn", "artist": "The Velvet Sundown"}
And use the Spotify API (registration required, but free) — specifically, the /search endpoint — to grab the Spotify Web Player link for that song contained in the external_urls field of the response object. This looks like:
https://open.spotify.com/track/64JjvzPdH2h3u5cJDF4y96
Why get this? Well, Spotify does not expose preview_url via their public API anymore. However, the preview URLs do exist in the page metadata — specifically in the og:audio Open Graph tag — but only under certain conditions.
When requesting a track page with bot-like headers (say, your standard axios user-agent), Spotify returns server-rendered HTML that includes:
<meta property="og:audio" content="https://p.scdn.co/mp3-preview/..." />
But when requesting the same page in the browser, or with browser-like headers, Spotify instead serves a JavaScript-driven React shell with no audio metadata present in the initial HTML. This is why you won’t see preview URLs via “View Source” in a normal browser session.
That makes it easy for us to scrape them. All we have to do is get the track URL, fetch the HTML for that page, and search for the CDN pattern on it.
import os
import sys
import json
import ssl
import time
import argparse
from urllib.parse import urlencode
import urllib.request
import requests
from bs4 import BeautifulSoup
from dotenv import load_dotenv
ssl._create_default_https_context = ssl._create_unverified_context
load_dotenv()
# example: list of songs with artist names
# format: [{"song": "Song Name", "artist": "Artist Name"}, ...]
# if INPUT_FILE is provided, it will load from that file instead
SONGS = [
# example entries - replace with your own or use an inputfile JSON
{"song": "Let it Burn", "artist": "The Velvet Sundown"},
{"song": "As the Silence Falls", "artist": "The Velvet Sundown"},
]
def build_brightdata_proxy():
proxy_user = os.environ.get("BRIGHT_DATA_PROXY_USER", "")
proxy_pass = os.environ.get("BRIGHT_DATA_PROXY_PASS", "")
if not (proxy_user and proxy_pass):
return None
proxy_url = f"@brd.superproxy.io:33335">http://{proxy_user}:{proxy_pass}@brd.superproxy.io:33335"
return proxy_url
def get_spotify_access_token():
token = os.environ.get("SPOTIFY_ACCESS_TOKEN")
if not token:
raise RuntimeError("SPOTIFY_ACCESS_TOKEN environment variable is required")
return token
def search_spotify_tracks(song_name, artist_name, limit=5):
query = f'track:"{song_name}" artist:"{artist_name}"'
params = {
"q": query,
"type": "track",
"market": "US",
"limit": str(limit),
}
headers = {"Authorization": f"Bearer {get_spotify_access_token()}"}
resp = requests.get("https://api.spotify.com/v1/search", params=params, headers=headers)
resp.raise_for_status()
return resp.json().get("tracks", {}).get("items", [])
def get_spotify_links(url):
proxy_url = build_brightdata_proxy()
if proxy_url:
opener = urllib.request.build_opener(
urllib.request.ProxyHandler({'https': proxy_url, 'http': proxy_url})
)
response = opener.open(url)
html = response.read().decode('utf-8')
else:
resp = requests.get(url)
resp.raise_for_status()
html = resp.text
soup = BeautifulSoup(html, "html.parser")
scdn_links = set()
for element in soup.find_all(True):
for attr_name, attr_value in element.attrs.items():
if isinstance(attr_value, (list, tuple)):
attr_values = attr_value
else:
attr_values = [attr_value]
for value in attr_values:
if value and "p.scdn.co" in value:
scdn_links.add(value)
return list(scdn_links)
def find_preview_url(track_name, artist_name):
"""find preview URL for a track using Spotify API search and scraping"""
try:
tracks = search_spotify_tracks(track_name, artist_name, limit=3)
if not tracks:
return None
# find best match by checking artist similarity
best_match = None
artist_lower = artist_name.lower()
for track in tracks:
track_artists = ', '.join(artist_obj['name'] for artist_obj in track['artists'])
if artist_lower and artist_lower in track_artists.lower():
best_match = track
break
# if no exact match, use first result
if not best_match:
best_match = tracks[0]
# get Spotify URL and scrape for preview
spotify_url = best_match.get("external_urls", {}).get("spotify")
if not spotify_url:
return None
preview_urls = get_spotify_links(spotify_url)
if preview_urls and len(preview_urls) > 0:
return preview_urls[0]
return None
except Exception as error:
print(f"Error finding preview for {track_name}: {error}", file=sys.stderr)
return None
def load_songs(input_file):
"""load songs from input file or use SONGS list"""
if input_file and os.path.exists(input_file):
print(f"Loading songs from: {input_file}")
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
# support both array format and object format
if isinstance(data, list):
return data
elif isinstance(data, dict) and "songs" in data and isinstance(data["songs"], list):
return data["songs"]
else:
raise ValueError('Input file must contain an array of {"song", "artist"} objects or {"songs": [...]}')
return SONGS
def get_previews(input_file=None, output_file='spotify-preview_urls.json'):
"""main function to get preview URLs for all songs"""
songs = load_songs(input_file)
# validate songs format
if not isinstance(songs, list) or len(songs) == 0:
print('Error: No songs found. Please provide songs in the SONGS list or via INPUT_FILE.', file=sys.stderr)
print('Format: [{"song": "Song Name", "artist": "Artist Name"}, ...]', file=sys.stderr)
sys.exit(1)
# validate each entry has song and artist
for i, song in enumerate(songs):
if not song.get("song") or not song.get("artist"):
print(f"Error: Entry {i + 1} is missing 'song' or 'artist' property.", file=sys.stderr)
print('Format: {"song": "Song Name", "artist": "Artist Name"}', file=sys.stderr)
sys.exit(1)
preview_urls = {}
found_count = 0
not_found_count = 0
total_tracks = len(songs)
print(f"Found {total_tracks} songs to process\n")
print('=' * 60)
# process each song
for i, song_entry in enumerate(songs):
song_name = song_entry["song"].strip()
artist_name = song_entry["artist"].strip()
print(f"\n[{i + 1}/{total_tracks}] Searching: {song_name} - {artist_name}")
# find preview URL
preview_url = find_preview_url(song_name, artist_name)
if preview_url:
# use song name as key, or song + artist for uniqueness
key = f"{song_name} - {artist_name}"
preview_urls[key] = preview_url
found_count += 1
print(f" ✓ Found: {preview_url[:70]}...")
# save immediately when preview URL is found
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(preview_urls, f, indent=2, ensure_ascii=False)
print(f" Saved to JSON ({found_count} found so far)")
else:
not_found_count += 1
print(f" ✗ No preview URL found")
# rate limiting between tracks
if i < len(songs) - 1:
time.sleep(0.5)
# final save
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(preview_urls, f, indent=2, ensure_ascii=False)
# summary
print('\n' + '=' * 60)
print('Summary:')
print('=' * 60)
print(f"Preview URLs found: {found_count}")
print(f"Preview URLs not found: {not_found_count}")
print(f"Total tracks processed: {total_tracks}")
print(f"\nResults saved to: {output_file}")
def main():
parser = argparse.ArgumentParser(
description='Get Spotify preview URLs for a list of songs and artists'
)
parser.add_argument(
'input_file',
nargs='?',
default=None,
help='Optional JSON input file with songs list'
)
parser.add_argument(
'output_file',
nargs='?',
default='spotify-preview_urls.json',
help='Output file path (default: spotify-preview_urls.json)'
)
args = parser.parse_args()
try:
get_previews(args.input_file, args.output_file)
except Exception as error:
print(f'Fatal error: {error}', file=sys.stderr)
sys.exit(1)
if __name__ == "__main__":
main()
If you’re following along and are using a proxy, you need to sign up here for the username, password, zone, etc.
Bright Data - All in One Platform for Proxies and Web Scraping
Anyway, I collected those CDN URLs for all the songs I wanted, dumped them to a JSON, and downloaded them directly from Spotify's CDN (p.scdn.co) for offline processing.
Song Fingerprinting with OpenL3
Then, each audio clip was converted into a fixed-length representation using OpenL3, a deep audio embedding model trained to capture perceptual and musical characteristics beyond simple features like tempo or key.
Here’s a minimal representation.
import numpy as np
import openl3
import librosa
import pickle
from pathlib import Path
def extract_embedding_from_mp3(filepath: Path) -> np.ndarray:
"""
extract OpenL3 embedding from an MP3 file
Args:
filepath: path to MP3 file
Returns:
embedding vector (512-dimensional by default)
"""
# load audio file at 48kHz (required by OpenL3)
audio, sr = librosa.load(str(filepath), sr=48000)
# extract embedding using OpenL3
# returns (embeddings, timestamps) where embeddings is (n_frames, 512)
emb, _ = openl3.get_audio_embedding(
audio,
sr,
content_type='music',
input_repr='mel256',
embedding_size=512
)
# average over time frames to get a single embedding vector
embedding = np.mean(emb, axis=0)
return embedding
def process_mp3_directory(directory: Path) -> tuple[list, list]:
"""
process all MP3 files in a directory and extract embeddings with metadata
Args:
directory: directory containing MP3 files
Returns:
tuple of (embeddings_list, metadata_list)
"""
mp3_files = sorted(list(directory.glob("*.mp3")))
embeddings = []
metadata = []
for filepath in mp3_files:
# extract embedding
embedding = extract_embedding_from_mp3(filepath)
# parse filename for metadata (assumes format: "Track Name - Artist Name.mp3")
if " - " in filepath.stem:
parts = filepath.stem.rsplit(" - ", 1)
track_name = parts[0].strip()
artist_name = parts[1].strip()
else:
track_name = filepath.stem
artist_name = "Unknown"
# build metadata dict
meta_dict = {
"file_path": str(filepath),
"track_name": track_name,
"artist": artist_name
}
embeddings.append(embedding)
metadata.append(meta_dict)
return embeddings, metadata
def save_embeddings(embeddings: list, metadata: list, output_dir: str = "embeddings"):
"""save embeddings and metadata to disk"""
output_path = Path(output_dir)
output_path.mkdir(exist_ok=True)
# convert to numpy array and save
embeddings_array = np.array(embeddings)
np.save(output_path / "embeddings.npy", embeddings_array)
# save metadata
with open(output_path / "metadata.pkl", 'wb') as f:
pickle.dump(metadata, f)
# example usage
if __name__ == "__main__":
mp3_dir = Path("previews")
embeddings, metadata = process_mp3_directory(mp3_dir)
save_embeddings(embeddings, metadata)
print(f"extracted {len(embeddings)} embeddings")
What this does:
- Loads audio from each MP3 file at 48kHz using
librosa. - Creates metadata dictionaries with file path, track name, and artist (parsed from filename, saved as pickle files)
- Extracts embeddings with
openl3.get_audio_embedding(). - Average over time frames to get a single vector, saved as a numpy array (.npy binaries)
OpenL3 produces frame-level embeddings, so I averaged them over time to obtain a single 512-dimensional vector per track.
To make cosine similarity meaningful at scale, I applied mean-centering to remove global bias, followed by L2 normalization, and indexed the historical songs using FAISS with an inner-product index.
import numpy as np
import faiss
import pickle
from pathlib import Path
def build_faiss_index(embeddings: np.ndarray, metadata: list) -> faiss.Index:
"""
build FAISS index from embeddings for cosine similarity search
Args:
embeddings: numpy array of embeddings (n_samples, n_features)
metadata: list of metadata dictionaries (must match embedding order)
Returns:
FAISS index
"""
n_samples, n_features = embeddings.shape
# normalize embeddings for cosine similarity
# subtract global mean to improve separation
mean_vec = np.mean(embeddings, axis=0, keepdims=True)
embeddings_centered = embeddings - mean_vec
# L2 normalize
norms = np.linalg.norm(embeddings_centered, axis=1, keepdims=True)
norms[norms == 0] = 1
embeddings_normalized = embeddings_centered / norms
# create inner product index (for cosine similarity on normalized vectors)
index = faiss.IndexFlatIP(n_features)
index.add(embeddings_normalized.astype('float32'))
return index
def save_index(index: faiss.Index, metadata: list, output_dir: str = "faiss_index"):
"""save FAISS index and metadata to disk"""
output_path = Path(output_dir)
output_path.mkdir(exist_ok=True)
# save index
faiss.write_index(index, str(output_path / "index.faiss"))
# save metadata (order must match FAISS IDs exactly)
with open(output_path / "metadata.pkl", 'wb') as f:
pickle.dump(metadata, f)
# example usage
if __name__ == "__main__":
# load embeddings and metadata
embeddings = np.load("embeddings/historical_embeddings.npy")
with open("embeddings/historical_metadata.pkl", 'rb') as f:
metadata = pickle.load(f)
# build index
index = build_faiss_index(embeddings, metadata)
# save index
save_index(index, metadata)
print(f"built index with {index.ntotal} vectors")
What this does:
- Loads embeddings (
npy) and metadata (pkl) from disk - Subtracts the global mean, then L2 normalizes each vector
- Builds a FAISS index: creates an inner product index (cosine similarity on normalized vectors) and adds the normalized embeddings
- Writes the FAISS index and metadata pickle (order matches FAISS vector IDs)
With all of it now being in a vector database I could simply query the index for each AI generated artist for its nearest neighbors, and then aggregate results at the artist level using a top-k similarity strategy (mean of the top three matching tracks per artist, k = 400), combined across all AI tracks.
For each query song, I retrieve the top 400 nearest neighbors from the FAISS index, then convert distances to similarity scores (0.0–1.0 range, where 1 = most similar. This is not a percentage.)
Code used in this step: https://gist.github.com/sixthextinction/863140ec9d9126b142f058629ab873a1
Things to remember:
- Historical embeddings are normalized when building the index. Query embeddings must be normalized the same way (using the saved mean vector) so they’re in the same space for similarity search.
- Artists that appeared consistently across many queries need to be weighted more heavily, while low-confidence matches need to be filtered out.
- Artists with fewer than 3 tracks are excluded (low confidence)
The result : three ranked lists of historical artists (I just took the Top 4) whose catalogs were acoustically closest — in embedding space — to each AI-generated artist.
Here’s how I’m scoring this. The final_score is:
mean_artist_score * (0.7 + 0.3 * consistency_weight)
With Range: 0.0 to 1.0 (higher = more similar)
Where:
- mean_artist_score: average of the top-3 track similarities across all query songs
- consistency_weight: ratio of query songs that matched this artist (capped at 1.0)
I put a 0.7 base weight on similarity and a 0.3 bonus for consistency across queries, so, for example: if an artist matches 5/10 query songs, consistency_weight = 0.5, so the multiplier is 0.7 + 0.3 × 0.5 = 0.85
Finally, I collected lyrics for all three artists from Genius and the artists’ own YouTube video descriptions, and ran a short lyrical analysis pipeline.
In it, rather than hand-waving about abstract “themes,” I quantified concrete lyrical properties. For each song, I measured lexical diversity using both Type–Token Ratio (TTR) and Moving-Average TTR (MATTR, more stable on short texts like lyrics), syntactic complexity (sentence length, subordination depth), sentiment and emotion distributions, and rhyme structure (rhyme density and reuse). These per-song metrics were then aggregated at the artist level to highlight patterns that persist across entire catalogs — not just individual tracks.
After that it was simply a matter of interpreting the data, and generating visualizations.
Limitations of This Study
- While the historical comparison set was large — the Spotify Top 2000 dataset plus top tracks across 26 major Spotify genres — it’s still finite and biased toward commercially successful music.
- My analysis also relies on short 30 second preview clips for audio embeddings and publicly available lyric transcriptions, which is good enough for a similarity analysis, but can never be a perfect comparison.
And that’s absolutely everything. Thank you for reading!
Thank you for reading! 🙌 This was the fourth in a series of data-driven deep dives I’m doing — forensic teardowns of things that are interesting, or things that shouldn’t work but do. If you want to see what else I find buried in data, follow along.
Comments
Loading comments…