Anthropic Claude has introduced a new generation of models via the Claude 3 model family. The three new models include: Haiku, Sonnet, and Opus, the last of which is said to be the most powerful. Claude has become popular quickly due to it’s powerful reasoning capabilities, larger context windows enabling large-scale RAG, and ease of use via the Anthropic SDK and services such as Amazon Bedrock.
In this article, we specifically take a look at Claude 3 Sonnet which is available via Amazon Bedrock. Sonnet comes with image to text capabilities as well as a 200K token context window. With that being said, let’s jump directly into the sample notebook, where we explore a few hands on examples.
NOTE: This article assumes a basic understanding of Python, LLMs, and AWS.
DISCLAIMER: I am a Machine Learning Architect at AWS and my opinions are my own.
Example Notebook
For this example, we’ll be working in a SageMaker Studio Notebook on a conda_python3 kernel backed by an ml.t3.medium instance. Ensure that you have Bedrock model access to Sonnet, you can toggle this directly on the Bedrock UI:
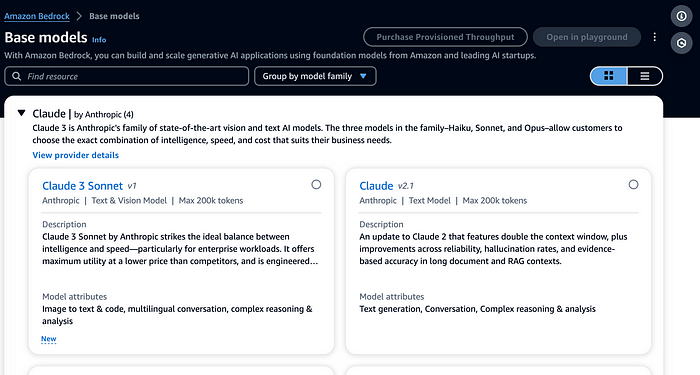
Available Models (Screenshot by Author)
Also ensure that your Studio Execution Role has full access to Bedrock so that you can invoke this model via the AWS Boto3 Python SDK.
All LLMs expect the model input to be structured in a format that the model understands. In the case of Claude 3 Sonnet, the Anthropic Messages API structure is expected so we structure our API request in that format:
text_content = [{'type':'text','text': "Who is Roger Federer?"}]
text_payload = {"messages":[{"role":"user","content":text_content}],
"anthropic_version":"bedrock-2023-05-31" ,"max_tokens":2000}
We can then invoke the Sonnet model by specifying the Model ID to the Bedrock Runtime Client with the payload we have just defined:
import json
import boto3
# setup bedrock client
runtime = boto3.client('bedrock-runtime')
model_id = 'anthropic.claude-3-sonnet-20240229-v1:0'
accept = "application/json"
contentType = "application/json"
response = runtime.invoke_model(
body=json.dumps(text_payload), modelId=model_id, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())
print(response_body['content'][0]['text'])
Truncated Output (Screenshot by Author):

In the case of image data we need to restructure the payload to specify an image. In this case we’ll take an image of my golden doodle Milo.

We Base64 encode this image and adjust the content type to be image in the payload. Note that we also give instructions to the model for what text to generate based on the image that we have provided:
import base64
# util function borrowed from: https://github.com/anthropics/anthropic-cookbook/blob/main/multimodal/best_practices_for_vision.ipynb
def get_base64_encoded_image(image_path):
with open(image_path, "rb") as image_file:
binary_data = image_file.read()
base_64_encoded_data = base64.b64encode(binary_data)
base64_string = base_64_encoded_data.decode('utf-8')
return base64_string
# structure content to specify an image in this case
image_content = [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": get_base64_encoded_image("milo.jpeg")
}},
{"type": "text",
"text": "What's in this image?"
}]
image_payload = {"messages":[{"role":"user","content":image_content}],
"anthropic_version":"bedrock-2023-05-31","max_tokens":2000}
Model Output (Screenshot by Author):

To further test Sonnet’s ability, I wrote a simple Python function on a notebook (excuse me for the handwriting in advance):
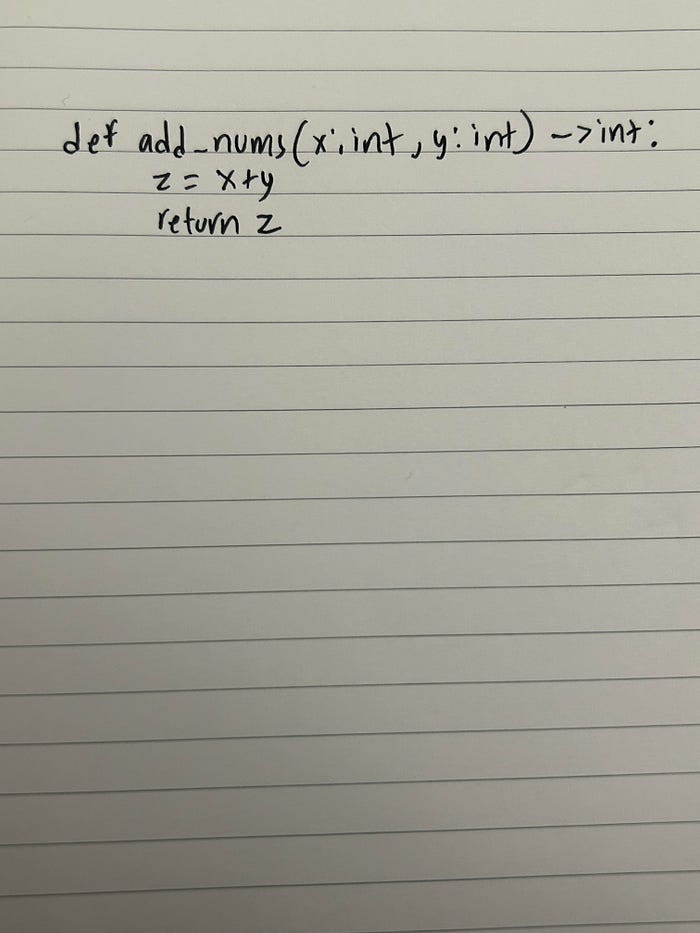
I then ask Sonnet to describe the Python function I’ve provided in the image, once again you can adjust these instructions as you need depending on your use-case.
# structure content to specify an image in this case
code_content = [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": get_base64_encoded_image("code-handwritten.jpeg")
}},
{"type": "text",
"text": "Describe the Python function in this image" #instructions
}]
code_payload = {"messages":[{"role":"user","content":code_content}],"anthropic_version":"bedrock-2023-05-31","max_tokens":2000}
# invoke model
response = runtime.invoke_model(
body=json.dumps(code_payload), modelId=model_id, accept=accept, contentType=contentType
)
response_body = json.loads(response.get("body").read())
print(response_body['content'][0]['text'])
Model Output (Screenshot by Author):

Pretty good! The model mistakenly takes z as a function parameter as well, but this could also potentially be attributed to the handwriting quality or the structuring of the image.
Additional Resources & Conclusion
GenAI-Samples/Bedrock-Claude-Sonnet at master · RamVegiraju/GenAI-Samples
The sample notebook for the example can be found at the link above. In this article, we just explored a few simple use-cases with utilizing Sonnet for multi-modal use-cases such as Vision to Text. We can expand from this for real-world use-cases such as document extraction and summarization, entity recognition, and more. I hope this article was a useful introduction to getting hands-on with the Claude 3 Sonnet model, stay tuned for more content in the Generative AI space!
As always thank you for reading and feel free to share it with others if you found it helpful.
If you enjoyed this article feel free to connect with me on LinkedIn and subscribe to my Medium Newsletter.
Comments
Loading comments…