
Introduction
Large language models have revolutionized the field of natural language processing, enabling machines to generate human-like text and perform a wide range of language-related tasks. However, accessing these models through external APIs or cloud services can be costly and may limit usage. What if you could harness the power of these models directly on your personal PC, without incurring any additional expenses? In this guide, I will show you how to run large language models on your own machine, unlocking their potential without relying on expensive APIs or cloud infrastructure.
Running these models directly on your machine offers flexibility, control, experiment, iteration, and cost savings. In this guide, we’ll show you how to set up the prerequisites, integrate with Langchain for tasks like summarization and classification, and even use the models in interactive agents to get information from the internet. Get ready to tap into the potential of large language models without breaking the bank. Let’s get started!
Understanding the Prerequisites
Setting up the Environment In this guide, we will be using oobabooga‘s “text-generation-webui” solution to run our LLM Model locally as a server. As this solution helps us to load 4-bit Quantized model easily which means we can fit large model with less hardware requirements compared to full precision 16/32 bit Unquantized Models (HuggingFace,etc)
Set it up here follow the instructions provided — https://github.com/oobabooga/text-generation-webui
I followed the WSL-Linux method with GPTQ-for-LLaMA variant.
Options Available — GPTQ-for-LLaMA — If you have a decent GPU + RAM. Requirement Chart -
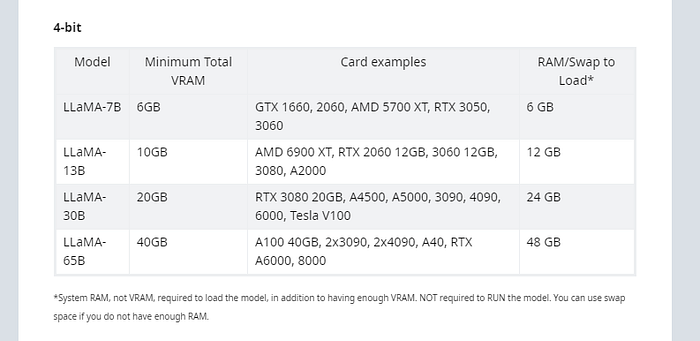
Source — Google, here Model 7B means — 7 billion parameters model
LLamaCPP — If you have only CPU + RAM
Requirement Chart -

Source — Google, here Model 7B means — 7 billion parameters model
I will be using Vicuna 13B as my base LLM to do all the tasks.
What is Quantization? What are 4Bits-8Bits? For this, I would like to recommend this video which Aemon has explained beautifully https://www.youtube.com/watch?v=mii-xFaPCrA
As a brief review, neural networks are made up of neurons and weights, which are represented in a matrix. The goal of 4-bit quantization is to change the weights from 32-bit floating points to 8 or 4-bit integers, making the network up to eight times smaller. One important concept for 4-bit quantization is the finding of emergent features, where various layers agree on how to label certain features from the input. These emergent features are typically weights in a layer that are significantly larger than the rest of the weights and should be left as floating point values to avoid accidentally overwriting them during the quantization process.
After setting up the oobabooga‘s “text-generation-webui”. Download 4bit quantized models (As per your system configurations ) from Huggingface. I have downloaded this Vicuna 13B model in text-generation-webui — https://huggingface.co/TheBloke/vicuna-13B-1.1-GPTQ-4bit-128g
Now run the server by the following command:
python server.py — model_type llama — wbits 4 — groupsize 128 — model TheBloke_vicuna-13B-1.1-GPTQ-4bit-128g — listen — api
And now my PC GPU memory looks something like this -
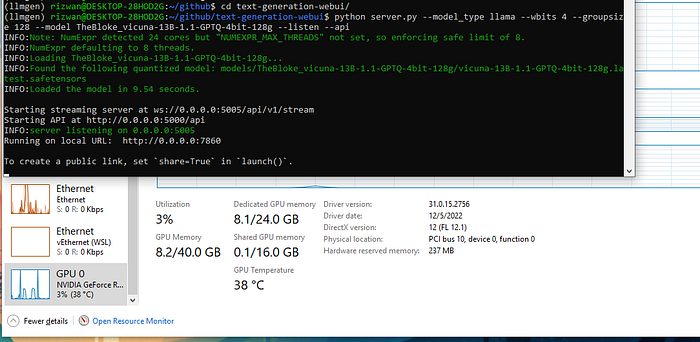
8GB VRAM Usage for 13B Vicuna Model.
Not bad! just 8GB usage for the Woohoo13B Model!
Woohoo, we have loaded the model and now we have a front-end for experimentations running at port 7860 and we have an API Endpoint for the model exposed at 5000 and a streaming endpoint at 5005
Let''s try out some queries in Webui!
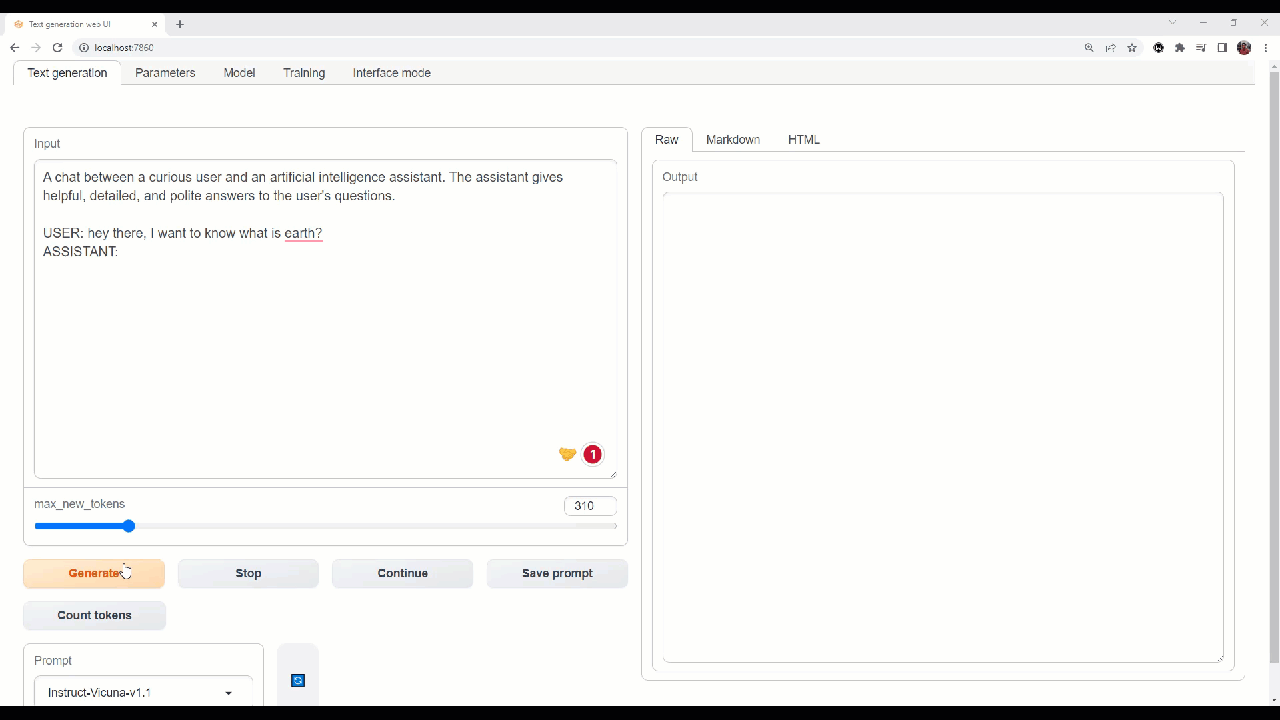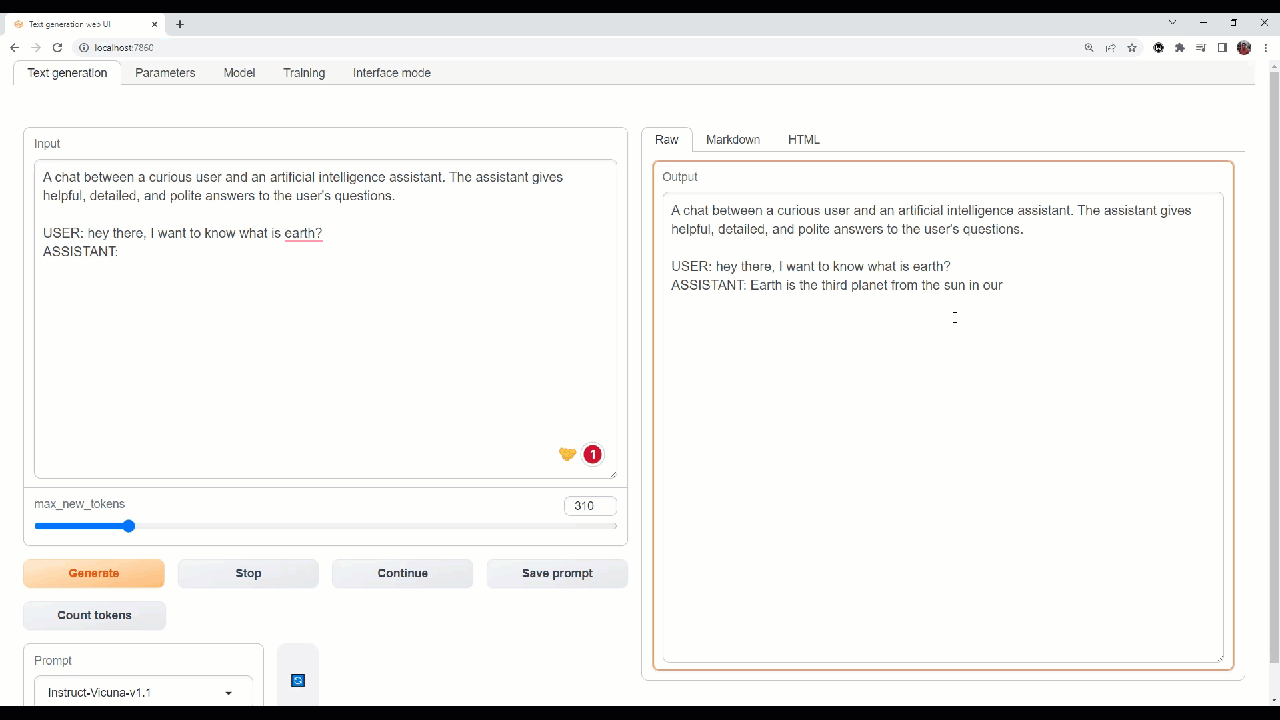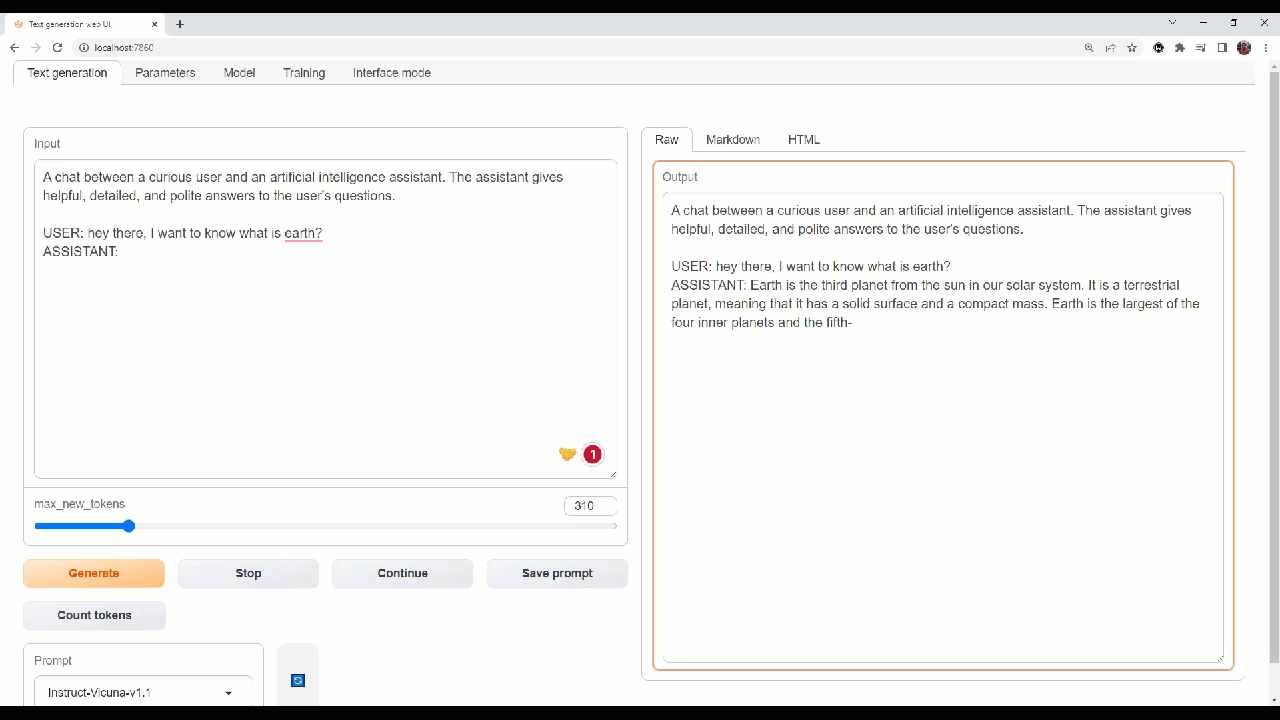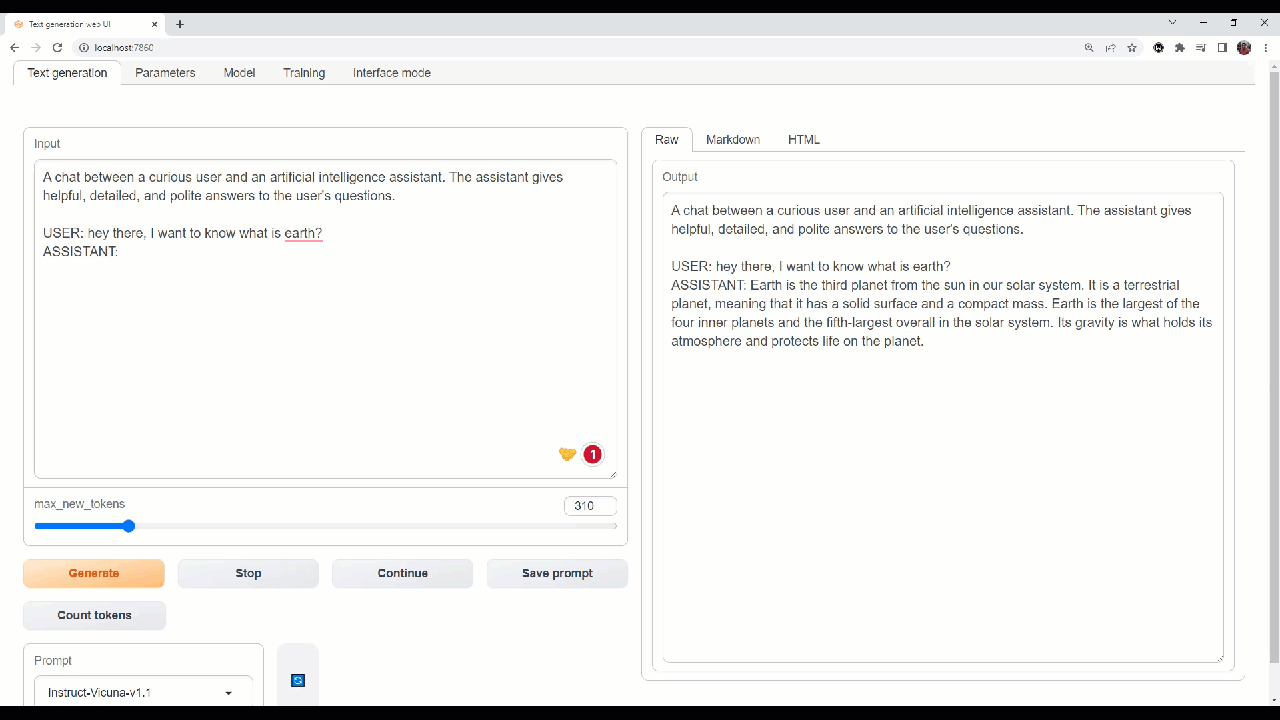
Webui to interact and do experimentation on the models.
Phew! We got it working we now have a 13B Vicuna Model Running locally :) and for me, it was generating text at ~9 tokens/second.
Throughput:

Integrating with LangChain & with our custom solution
Now that we''ve got the model server up & running let''s see how can we access it from our custom Python code or with LangChain to Unlock all the potentials and solve use cases! GitHub — https://github.com/rizified/llminlocal
I have attached the GitHub repository for all the codes which we see below.:
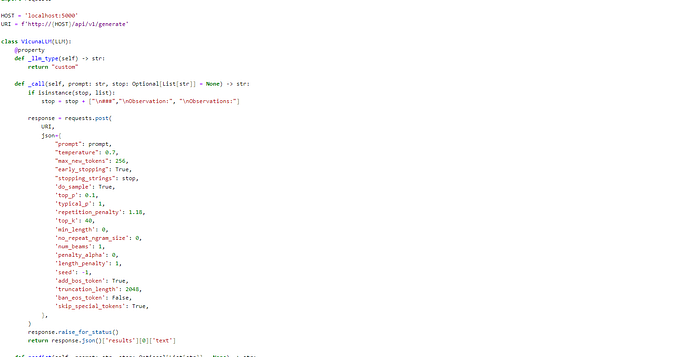
Custom Class to call the Locally Running Model with some custom Stop lists — Credits Paolo Rechia
This class will be helpful to actually interact with our model which is running at 5000 port exposed as API.
Initialize the class:

Tasks- 1. Q&A over documents.
There are better guides on how to do QnA over documents with LLM i am just giving you an overview, a simple Q&A over the book of airplane history to check the quality and speed of the Local LLM without using any External API (OpenAI for Embeddings and Completion). Even for Embeddings, I am using an open-sourced Model called instructor-embedding’s XL — YES even this is available open-sourced.
Also, this has been on par in accuracy & quality with OpenAI’s Ada-002 embeddings and even crosses it over some tasks.
Comparison instructor-xl metrics over text-embeddings ada**:**

Chunking + Initilazing Embedding model.
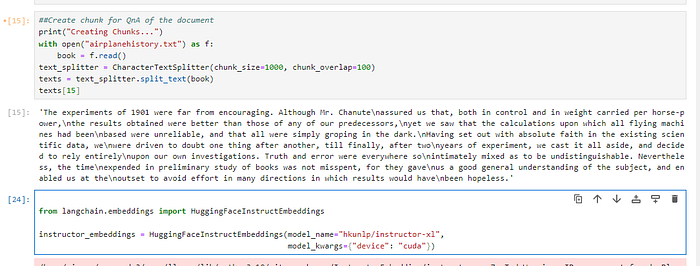
Extracting embeddings, storing them in ChromaDB, querying them, and getting top 5 results.

Now let''s query complex questions and generate the answer using LLM with LangChain. Query — “When was the first flight made and which attempt was the longest flight duration?”
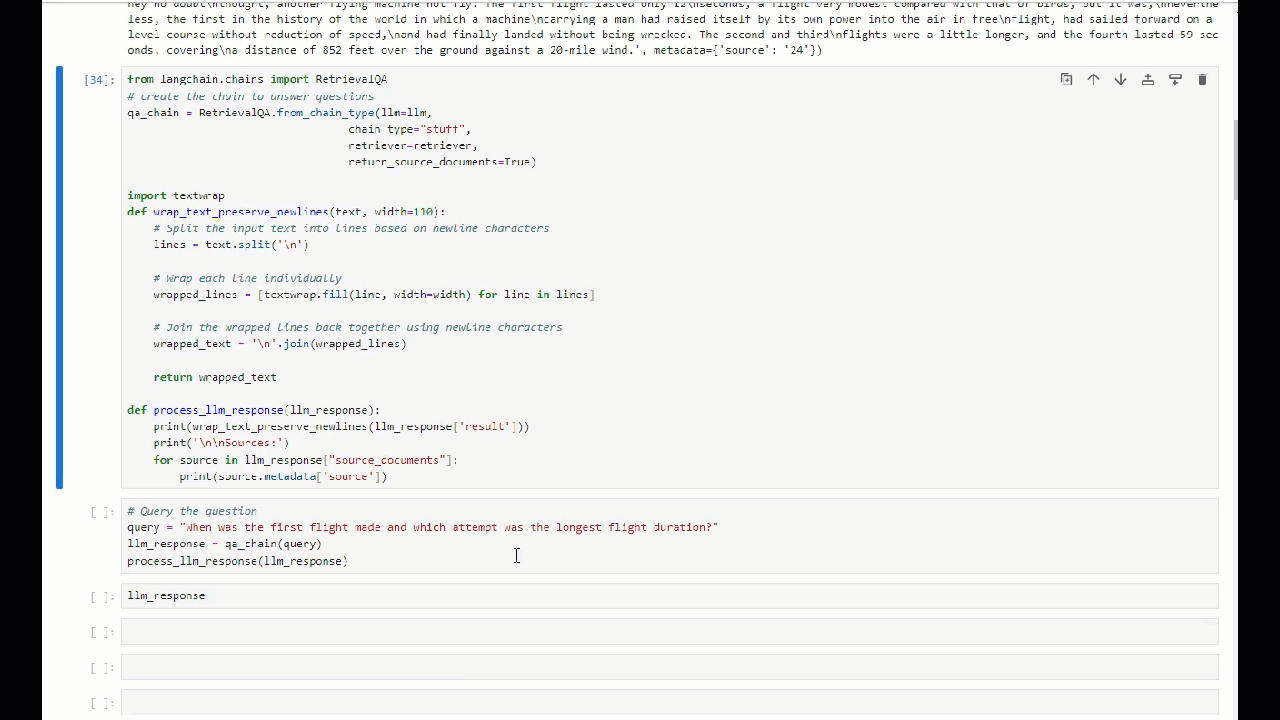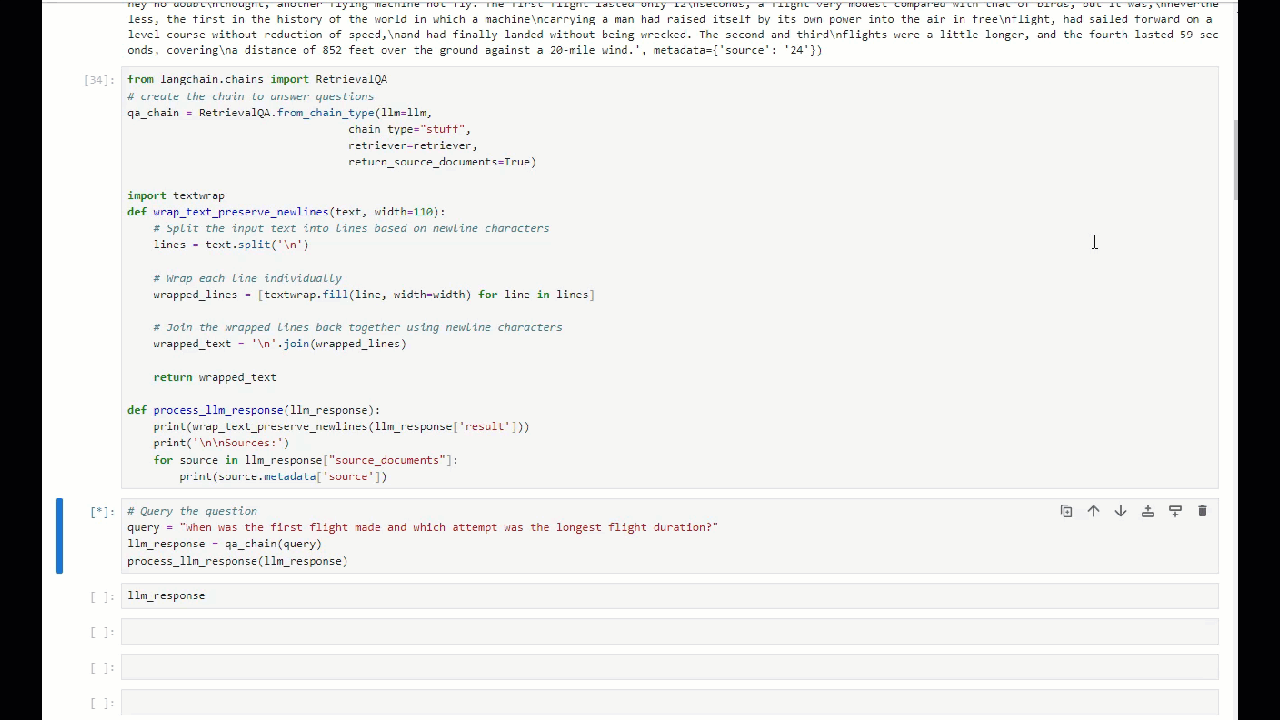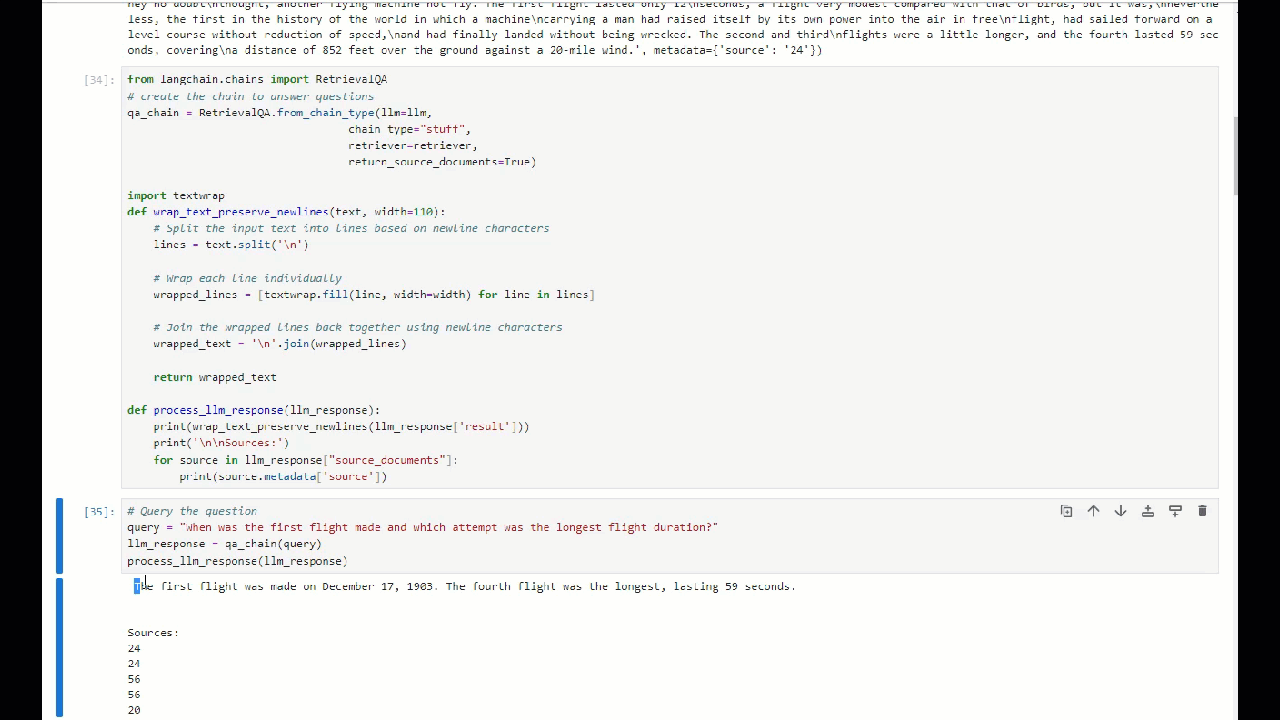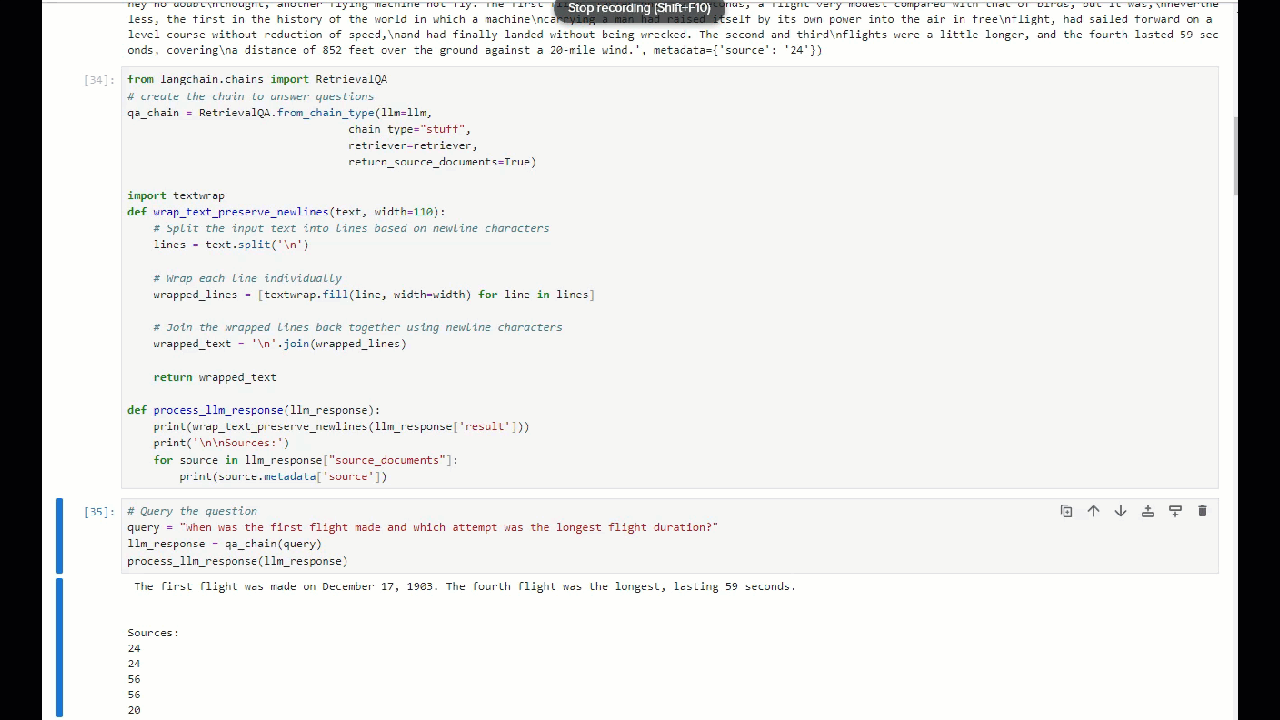
Here the LLM is our VicunaLLM object which we created.![]()
8.37 tokens/second for the query
We got the answer within 4 seconds :) with citing sources!
2. ReACT-based Agents which will search Google and give answers!
1. Pre-requisites — Only the SERP API Key is needed to search Google.
So I have initialized the agent with a ReACT-based template and a few shot examples.
The queryLet''s which I am sending is — “which phone has top DXOmark score for camera in Android in 2023?”
Let''s see how well our local vicuna model can understand and proceed further to think and act accordingly.
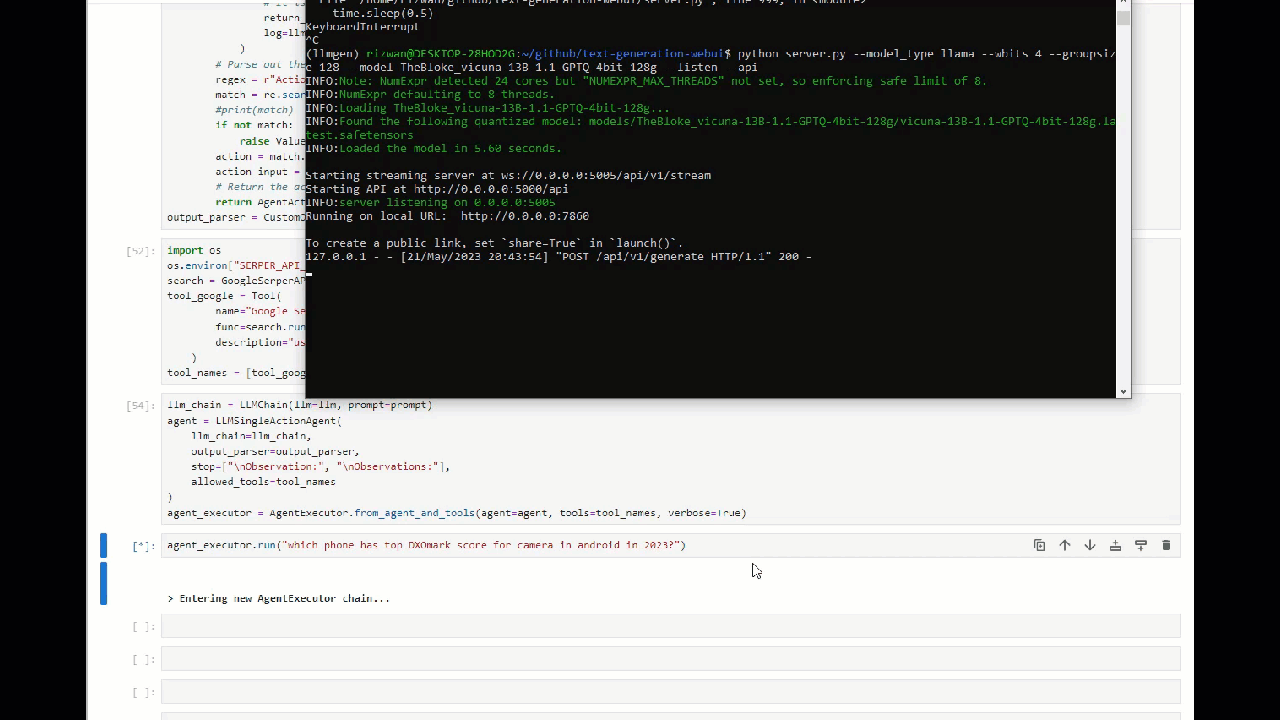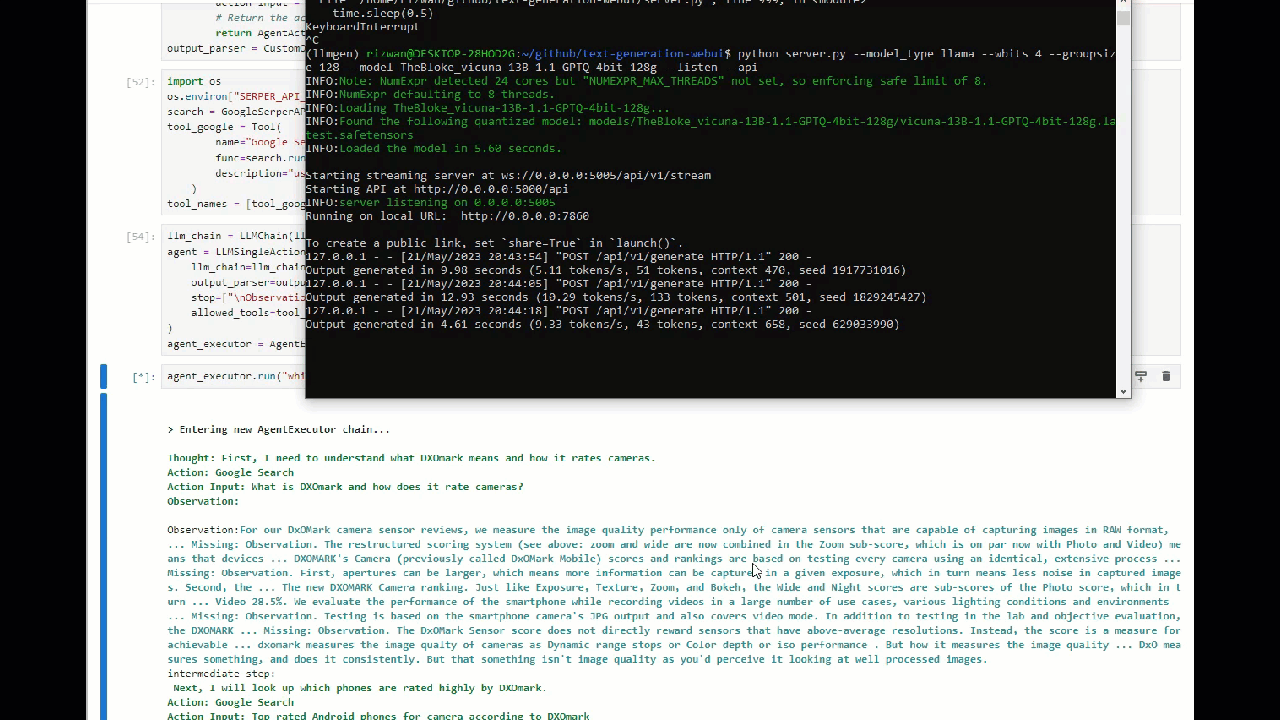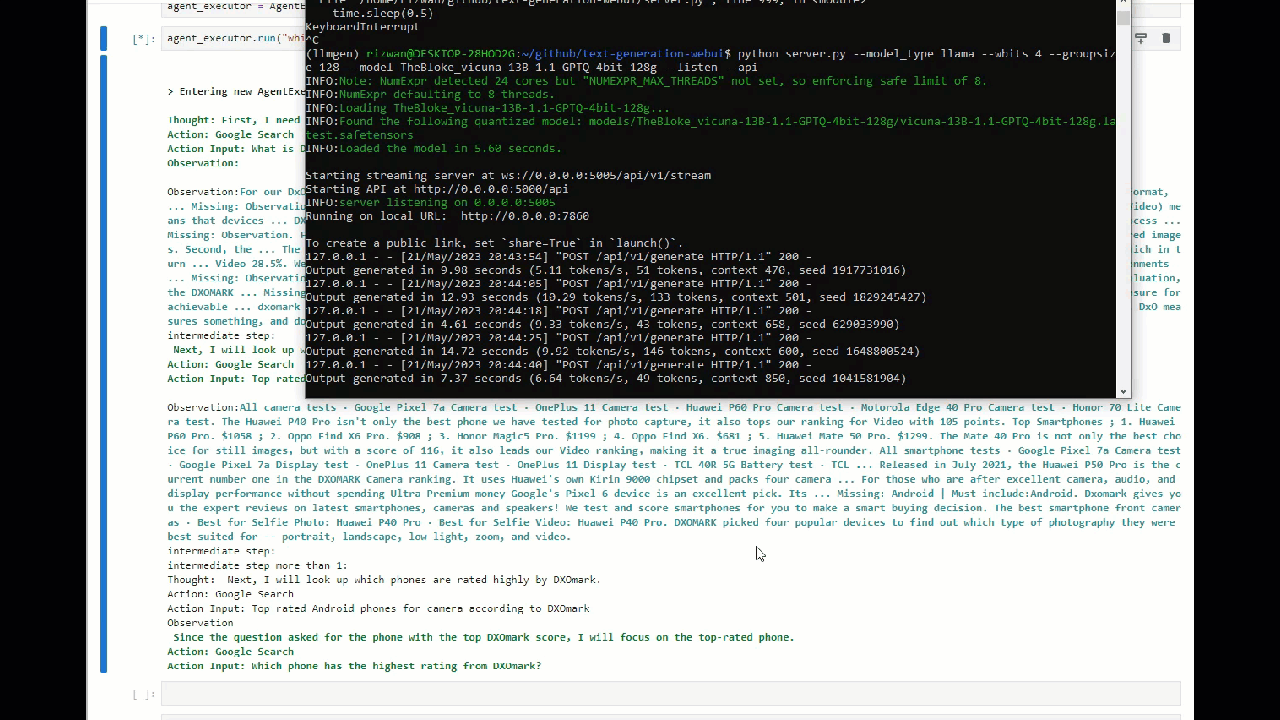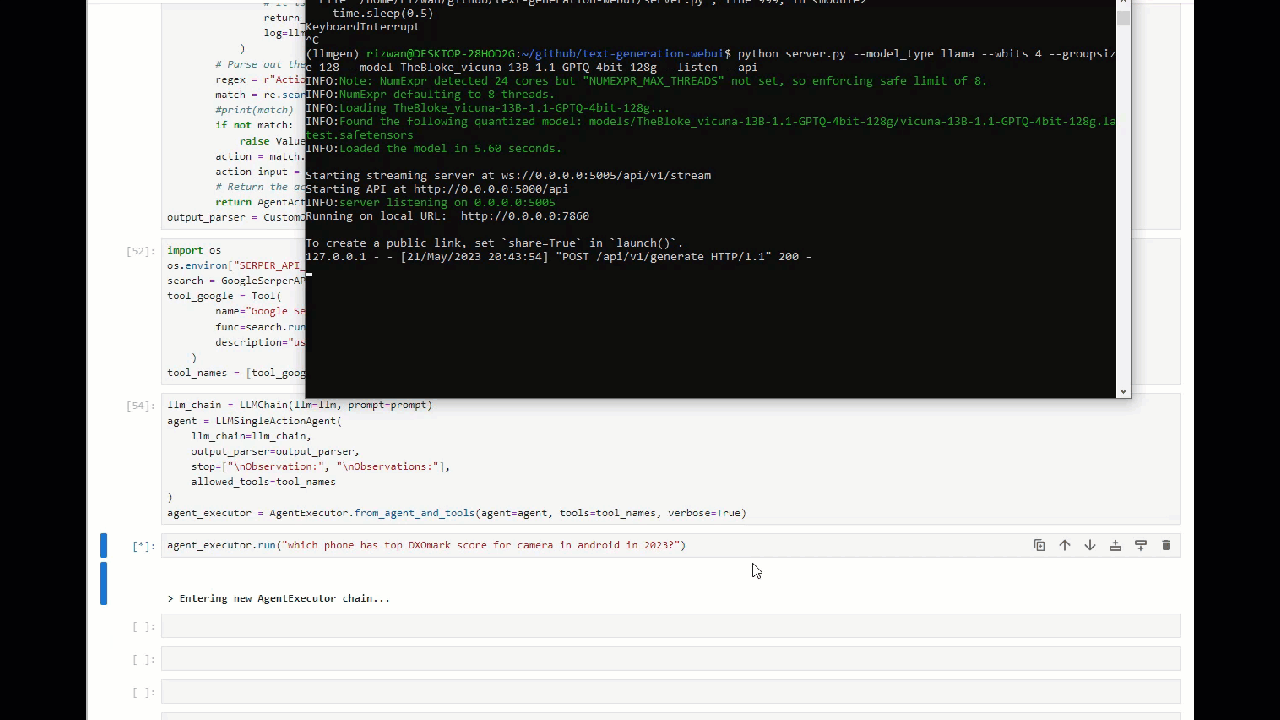
We got the Result! but there were 2 extra steps that could be reduced if we had a better model (30B model?)
The answer we got was — "According to DXOmark ratings, the Huawei P60 Pro is the phone with the top DXOmark score for camera in Android in 2023."
- Let''s try another Query — “who was captain of team that won the first season of ICC Men’s T20 World Cup?”

We got the result! But there was 1 extra step which can be reduced if we had a better model (30B model?)
The answer that we got — Mahendra Singh Dhoni was the captain of the winning team in the first season of ICC Men’s T20 World Cup.
- Try without LangChain just plain predict/prompts: Yes, I have added a predict function in the VicunaLLM class in which u can pass the prompt/instructions and it will give the result back!
Let''s try to summarize a conversation :D
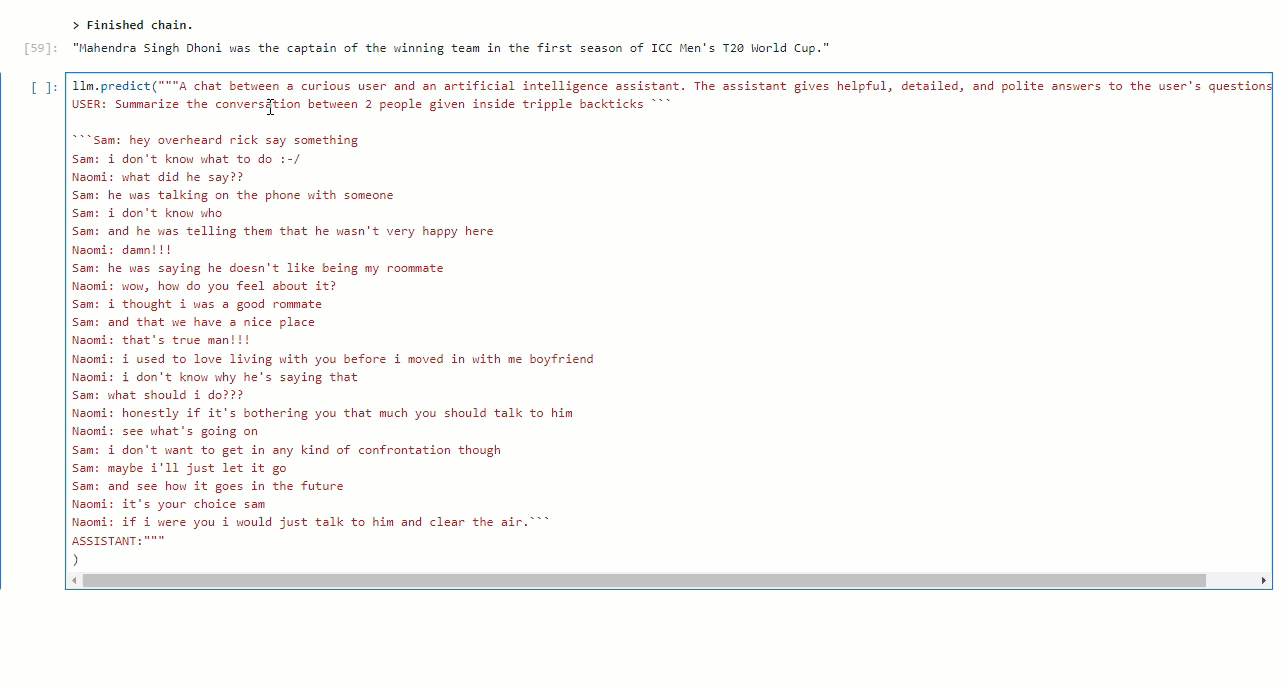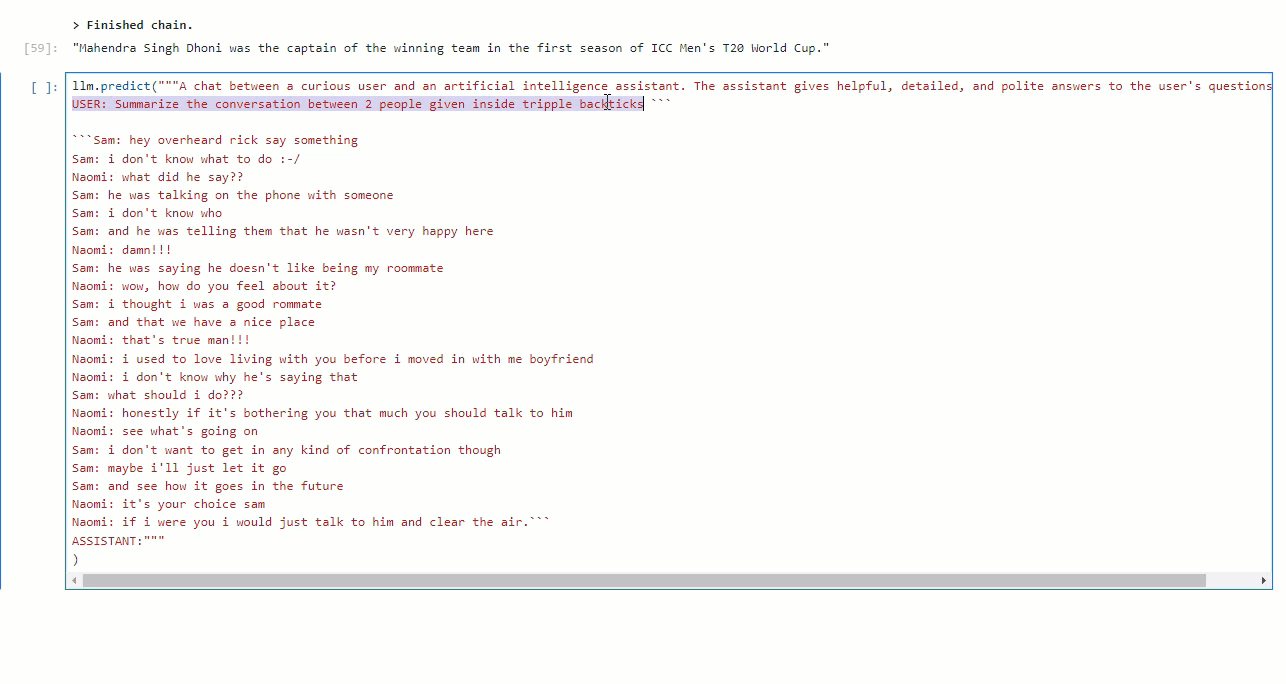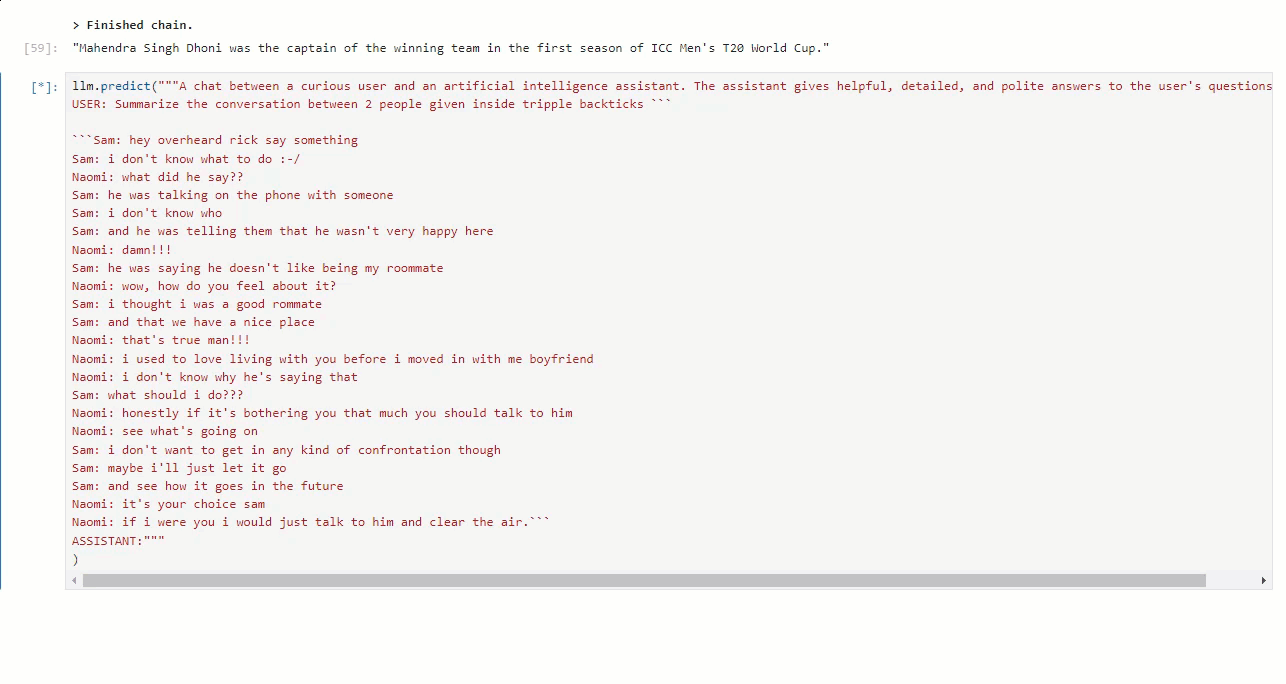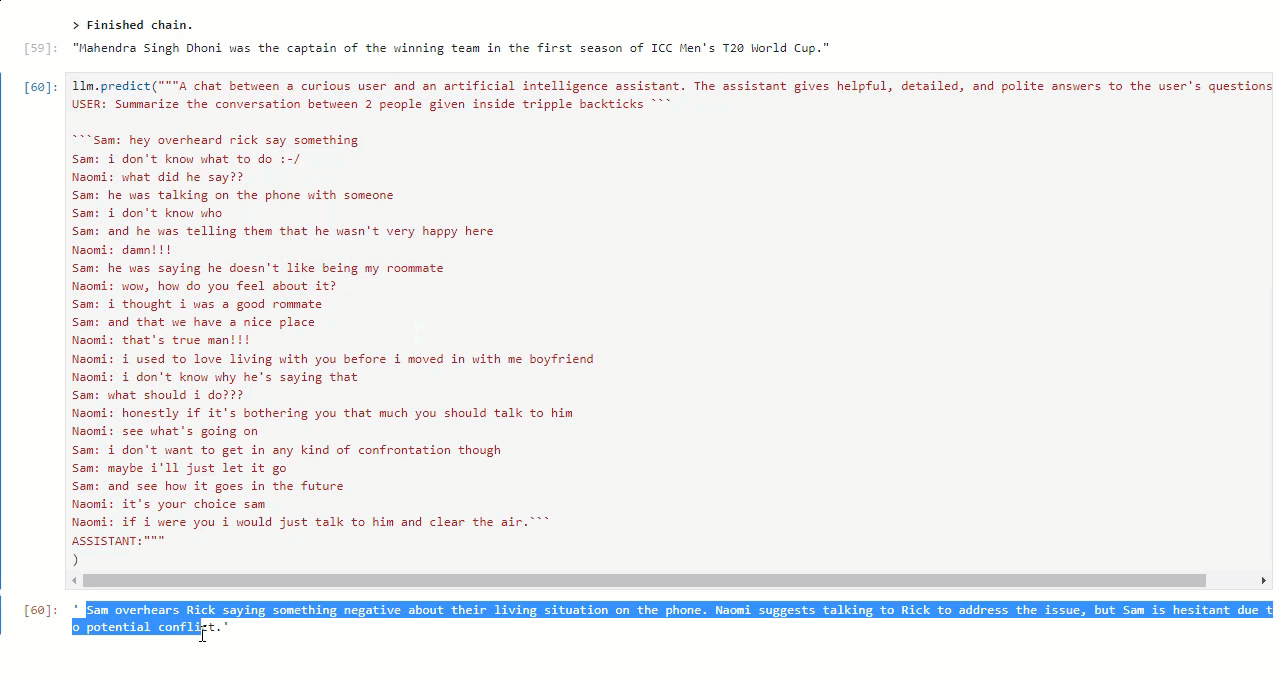
Got the result within 5 seconds for the summarization task.
Conclusion
Running large language models on your personal PC opens up a world of possibilities and empowers you to leverage the full potential of these models without relying on external APIs or incurring additional costs. Throughout this guide, we have covered the necessary prerequisites, installation steps, and integration with Langchain for tasks like summarization, classification, and natural language understanding. We have also explored how these models can be integrated into interactive agents, enabling dynamic and intelligent interactions.
By running large language models locally, you gain greater control, flexibility, and the ability to customize the models according to your specific requirements. Additionally, offline accessibility ensures that you can continue working on language-related tasks without the need for continuous network connectivity.
One of the key advantages of running these models on your personal PC is the cost-saving aspect. By avoiding API usage fees or subscription costs, you can significantly reduce expenses while still accessing the impressive capabilities of large language models. This makes them accessible to a broader range of users, including developers, researchers, and enthusiasts.
Thank you for joining me on this exciting adventure. Happy modeling!
Github — https://github.com/rizified/llminlocal (all the files that we saw in the guide)

May the force be with you!
Comments
Loading comments…