Ollama is the new Docker-like system that allows easy interfacing with different LLMs, setting up a local LLM server, fine-tuning, and much more.
What we are going to do is simple. I have a folder containing all my research articles. I want to chat with an LLM and seek information about the different aspects of my research. For example, this is what chatGPT says when I ask it something very specific about my work.

Incidentally, the paper was published in January 2022.
 Maybe it was not part of the training data.
Maybe it was not part of the training data.
However, when I ask a zephyr 7B connected to my research article pdfs, it has this to say:

It not only provides the complete acronym, but also delivers a concise definition, highlights its real-world applications, and even points out its limitations. What more could we possibly ask for in terms of information!
Let us set it up.
Operating System: Ubuntu (Should work on Mac as well)
Python: 3.10
RAM/GPU ≥ 8 GB
Setup Environment:
Installing Ollama (different for Mac, please check here)
sudo snap remove curl
sudo apt install curl
curl https://ollama.ai/install.sh | sh
For Ubuntu it was giving me an error in getting ollama. So I had to re-install curl as mentioned above (first two lines).
Next, pull the zephyr model from ollama. Make sure you have 8 GB RAM or GPU. For other models check here.
ollama pull zephyr
Next set up the Python env.
conda create -n ollamapy310 python=3.10
conda activate ollamapy310
pip install chromadb
pip install langchain
pip install BeautifulSoup4
pip install gpt4all
pip install langchainhub
pip install pypdf
pip install chainlit
Create a folder to contain your project
mkdir ollama_chainlit
cd ollama_chainlit/
mkdir data
mkdir vectorstores

Get Data
Download these pdf files and store them in the data folder.

Create Vector Store
We will use the following piece of code to create vectorstore out of these pdfs. You can name this file data_load.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader, DirectoryLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import UnstructuredHTMLLoader, BSHTMLLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import GPT4AllEmbeddings
from langchain.embeddings import OllamaEmbeddings
import os
DATA_PATH="data/"
DB_PATH = "vectorstores/db/"
def create_vector_db():
documents=[]
processed_htmls=0
processed_pdfs=0
for f in os.listdir("data"):
try:
if f.endswith(".pdf"):
pdf_path = ''./data/'' + f
loader = PyPDFLoader(pdf_path)
documents.extend(loader.load())
processed_pdfs+=1
except:
print("issue with ",f)
pass
print("Processed ",processed_pdfs,"pdf files")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
texts=text_splitter.split_documents(documents)
vectorstore = Chroma.from_documents(documents=texts, embedding=GPT4AllEmbeddings(),persist_directory=DB_PATH)
vectorstore.persist()
if __name__=="__main__":
create_vector_db()
When you run the code with:
python data_load.py
Creating vector embeddings:

The vector store is created in the vectorstores/db folder:

Run Model
Next, we set up the model, refer to the vectorstore, and create the user interface using chainlit. The following piece of code takes care of that. You can call it model.py:
from langchain import hub
from langchain.embeddings import GPT4AllEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import Ollama
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
import chainlit as cl
from langchain.chains import RetrievalQA
QA_CHAIN_PROMPT = hub.pull("rlm/rag-prompt-llama")
def load_llm():
llm = Ollama(
model="zephyr",
verbose=True,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
)
return llm
def retrieval_qa_chain(llm,vectorstore):
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
return_source_documents=True,
)
return qa_chain
def qa_bot():
llm=load_llm()
DB_PATH = "vectorstores/db/"
vectorstore = Chroma(persist_directory=DB_PATH, embedding_function=GPT4AllEmbeddings())
qa = retrieval_qa_chain(llm,vectorstore)
return qa
@cl.on_chat_start
async def start():
chain=qa_bot()
msg=cl.Message(content="Firing up the research info bot...")
await msg.send()
msg.content= "Hi, welcome to research info bot. What is your query?"
await msg.update()
cl.user_session.set("chain",chain)
@cl.on_message
async def main(message):
chain=cl.user_session.get("chain")
cb = cl.AsyncLangchainCallbackHandler(
stream_final_answer=True
)
cb.ansert_reached=True
# res=await chain.acall(message, callbacks=[cb])
res=await chain.acall(message.content, callbacks=[cb])
answer=res["result"]
answer=answer.replace(".",".\n")
sources=res["source_documents"]
if sources:
answer+=f"\nSources: "+str(str(sources))
else:
answer+=f"\nNo Sources found"
await cl.Message(content=answer).send()
Run this code with the following:
chainlit run model.py -w
Getting it exactly right:

While ChatGPT was blissfully unaware:

Some more questions:

And the answers are pretty fast. Maybe a wait of 2 or 3 seconds.
Also, the zephyr model is quite nifty. In this case, it only takes up around 5 GB of GPU.
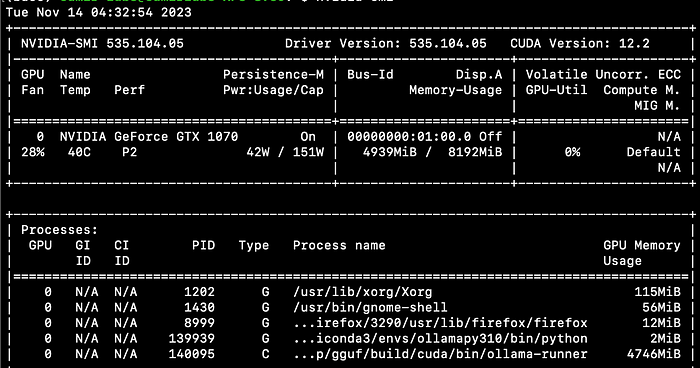
Ollama boasts a plethora of additional features waiting to be explored.
This concludes our discussion for now, but I hope you can successfully implement it on your system.
Comments
Loading comments…