
Define the problem
I want to properly tag my documents with the keywords which best define the content. The good thing is that I have a list of keywords that I use to organize my documents, such as Cloud, Security, Architecture, Digital, etc.
Get Started
I need a **Named entity recognition (NER) **library to extract entities from my document. Lucky for me, there are a few good libraries to choose from, e.g. NLTK and spaCy. I have no intention to get a degree in NER, so I made a quick decision to try spaCy. With a few lines of code, I am all set.
pip install - U spacy
python -m spacy download en_core_web_sm
#side note: you may run into issue if your Python is 32-bit version, which is what happened to me. Just install the 64-bit version, you should be all set
A few basics about spaCy
spaCy can be used to build information extraction or natural language understanding systems, or to pre-process text for deep learning. It’s good for tokenization, NER, Rule-based Matching, Text Classification. More details refer to the spaCy online doc. To start simple, rule-based matching is good enough for my problem. There are 2 types of rule-based matchers provided by spaCy: Token Matcher and Phrase Matcher.
-
Phrase Matcher provides a very simple interface to use spaCy. You just need to define a list of matching phrases, then spaCy will get the job done.
-
However, Token Matcher provides more flexible control on how the matching should be done, such as using a Token to define a match pattern.
I have another article discussing more interesting rule-based matching with EntityRuler A Closer Look at EntityRuler in SpaCy Rule-based Matching
Give it a try
Let’s start with the simpler one: Phrase Matcher.
nlp = spacy.load('en_core_web_sm')
phraseMatcher = PhraseMatcher(nlp.vocab, attr='LOWER')
terms = ["cloud computing", "it", "information"]
patterns = [nlp.make_doc(text) for text in terms]
phraseMatcher.add("Match_By_Phrase", None, *patterns)
doc = nlp(content)
matches = phraseMatcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
10 lines of code exactly, haha. Well, you need more code to complete the script. However, you get the idea of how simple it is to use spaCy. What it does is to create a match pattern from phrases defined in the terms list. Then add the pattern to phraseMatcher. “matches” are the matched output from spaCy, which give you the match id, start and end position of the match in the input document. So a simple for loop can help to print out the result more friendly.
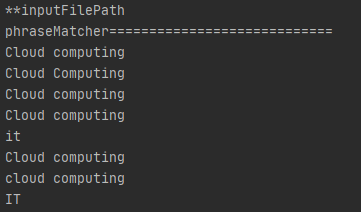
However, there is a problem. I was trying to find out instances of IT, in the upper case as Information Technology. But phrase matcher gave me IT and *it *as well. This is where Token matcher comes in. The attribute LOWER lets you create case-insensitive match patterns, but it applies to the matcher level. Token Matcher allows you to control the token at each token level.
nlp = spacy.load('en_core_web_sm')
matcher = Matcher(nlp.vocab)
print("Match_By_Token============================")
pattern1 = [{"LOWER": "cloud"}, {"LOWER": "computing"}]
pattern2 = [{"TEXT": "IT"}]
pattern3 = [{"TEXT": "EDI"}]
pattern4 = [{"LOWER": "interface"}]
matcher.add("Match_By_Token", None, pattern1, pattern2, pattern3, pattern4)
doc = nlp(content)
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
You can see token matcher takes in patterns, which allows you to define a
-
case-insensitive match on “cloud computing” [{“LOWER”: “cloud”}, {“LOWER”: “computing”}]
-
case-sensitively match on “IT” [{“TEXT”: “IT”}]
-
match with lemmatization, part-of-speech tags, etc. e.g. [{“LEMMA”: {“IN”: [“like”, “love”]}}, {“POS”: “NOUN”}]
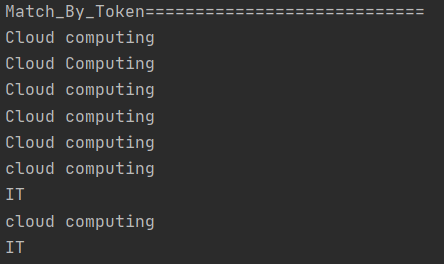
Try the code, and it works! It only matches the upper case “IT”, instead of “it” or “It”.
Make it useable
I’d like to find the most mentioned terms in the documents so that I can eventually classify/tag them. Counter library is handy to get it done. It simply counts the occurrence of match terms and picks the top 3 as in my case.
matchedTokens = []
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
matchedTokens.append(span.text.lower())
c = Counter(matchedTokens)
for token, count in c.most_common(3):
print('%s: %7d' % (token, count))

Now, I know the above input document is more about cloud computing!
Give it a try with other token attributes (LEMMA, IS_NUM, LIKE_EMAIL, etc.) and extended patterns (IN, NOT_IN, etc.), you can achieve much more with spaCy.
The full code is here:
import os
from spacy.matcher import Matcher, PhraseMatcher
import spacy
from collections import Counter
# This is the testing file
filePath = 'C:/xxx/testSpaCy.txt'
def getInputContent(inputFilePath):
print('**inputFilePath')
docContent = []
if os.path.isfile(inputFilePath):
try:
file = open(inputFilePath, 'r', encoding="utf8")
docContent = file.read()
return docContent
except Exception as err:
print(err)
return docContent
def myPhraseMatcher(content):
nlp = spacy.load('en_core_web_sm')
phraseMatcher = PhraseMatcher(nlp.vocab, attr='LOWER')
terms = ["cloud computing", "it", "information"]
# Only run nlp.make_doc to speed things up
patterns = [nlp.make_doc(text) for text in terms]
phraseMatcher.add("Match_By_Phrase", None, *patterns)
doc = nlp(content)
matches = phraseMatcher(doc)
print("phraseMatcher============================")
matchedTokens = []
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
matchedTokens.append(span.text.lower())
c = Counter(matchedTokens)
for token, count in c.most_common(3):
print('%s: %7d' % (token, count))
def myTokenMatcher(content):
nlp = spacy.load('en_core_web_sm')
matcher = Matcher(nlp.vocab)
print("Match_By_Token============================")
pattern1 = [{"LOWER": "cloud"}, {"LOWER": "computing"}]
pattern2 = [{"TEXT": "IT"}]
pattern3 = [{"TEXT": "EDI"}]
pattern4 = [{"LOWER": "interface"}]
matcher.add("Match_By_Token", None, pattern1, pattern2, pattern3, pattern4)
doc = nlp(content)
matches = matcher(doc)
matchedTokens = []
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
matchedTokens.append(span.text.lower())
c = Counter(matchedTokens)
for token, count in c.most_common(3):
print('%s: %7d' % (token, count))
def main(argv=None):
# myPhraseMatcher(getInputContent(filePath))
myTokenMatcher(getInputContent(filePath))
if __name__ == "__main__":
main()
Comments
Loading comments…