As Bedrock unveiled a few weeks ago, there is still a lot of turmoil in the domain, and I felt that my personal AI assistant, created earlier this year, had to keep up the pace by using its own data as part of its “knowledge”. Let’s recap the journey.
The first article presented the AI assistant based on OpenAI ChatGpt.
Build your personal speaker assistant with Amplify and ChatGPT
As soon as Bedrock was generally available, I re-purposed the assistant to utilize Bedrock A21Labs’ Jurassic Ultra foundation model to achieve similar behaviour.
Bedrock unveiled: A Quick Lambda example
This article, instead, outlines how to use the Bedrock Embedding Titan model to index documents towards an OpenSearch Serverless vector database.
The ultimate goal, outlined in the next article, is to use such indexed documents and more information (chat memories and Bedrock FM) so that the AI assistant provides more contextual answers.
A RAG-based AI speaker assistant with Langchain and Bedrock
Architecture
As the assistant needs data to augment the foundational models, it will add two flows:
- Indexing documents. In this flow, the subject of this article, the user will upload documents from UI to an S3 bucket. This will trigger a lambda indexing function to index its documents’ embeddings into an Amazon OpenSearch Serverless vector database.
- Assistant enquiry. This flow (scope of the next article of the series) will show a Langchain-based function that will use different sources (Bedrock FMs, DynamoDB memories and Amazon OpenSearch embeddings vector database) to build a proper answer based on both models and documents added by the user.
The overall architecture will look as below, but this article will focus on the red dotted section:
Overall architecture
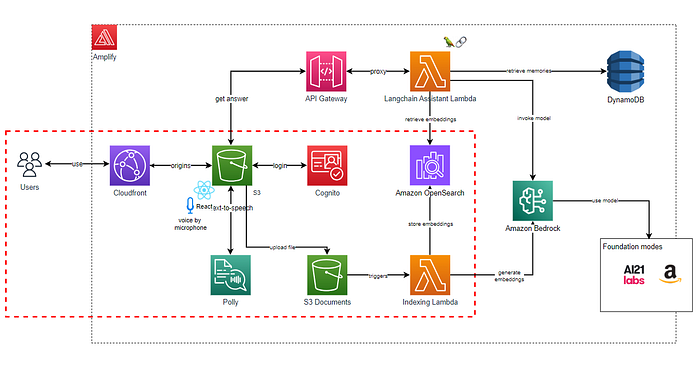
Let’s now look at the Indexing part.
Indexing documents
To index documents, we need the following steps:
- Provision of the S3 bucket hosting the documents.
- Provision of the Vector database (OpenSearch Serverless) required to store the information embeddings.
- Build a Lambda, “glueing” the two storages.
- Prepare the frontend with an upload component.
Provision the S3 documents bucket
We need an S3 bucket to store user documents and an associated Lambda to be triggered to execute the indexing part. You can choose any preferred (CDK, CloudFromation, Terraform). I will keep using Amplify CLI as shown below:
alatech:~/environment $ amplify add storage
? Select from one of the below mentioned services: Content (Images, audio, video, etc.)
✔ Provide a friendly name for your resource that will be used to label this category in the project: · bedrockAssistantDocuments
✔ Provide bucket name: · bedrockassistantdocuments
✔ Who should have access: · Auth users only
✔ What kind of access do you want for Authenticated users? · create/update, read, delete
✔ Do you want to add a Lambda Trigger for your S3 Bucket? (y/N) · yes
✅ Successfully added resource S3Triggerb67f4050 locally
✔ Do you want to edit the local S3Triggerb67f4050 lambda function now? (y/N) · no
✅ Successfully added resource bedrockAssistantDocuments locally
Provision the OpenSearch Serverless
As a preview, OpenSearch Serverless supports vector as a database type.
Vector Storage And Search - Vector Engine For Amazon OpenSearch Serverless - AWS
To provision the cluster, we will use Amplify custom resources via the below command:
alatech:~/environment $ amplify add custom
✔ How do you want to define this custom resource? · AWS CDK
✔ Provide a name for your custom resource · vectorDatabase
This generates a new structure under the amplify folder:
Folder structure for custom resources:
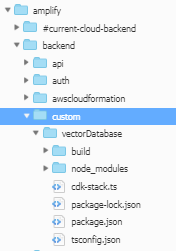
Now modify the CDK-stack.ts file and update with the below code in CDK:
import * as cdk from ‘aws-cdk-lib’;
import * as AmplifyHelpers from ‘@aws-amplify/cli-extensibility-helper’;
import { AmplifyDependentResourcesAttributes } from ‘../../types/amplify-dependent-resources-ref’;
import { Construct } from ‘constructs’;
import * as ops from ‘aws-cdk-lib/aws-opensearchserverless’;
import * as ssm from ‘aws-cdk-lib/aws-ssm’;
export class cdkStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps, amplifyResourceProps?: AmplifyHelpers.AmplifyResourceProps) {
super(scope, id, props);
/* Do not remove - Amplify CLI automatically injects the current deployment environment in this input parameter */
new cdk.CfnParameter(this, ‘env’, {
type: ‘String’,
description: ‘Current Amplify CLI env name’,
});
const amplifyProjectInfo = AmplifyHelpers.getProjectInfo();
// Create the collection storing the embeddings
const collection = new ops.CfnCollection(this, `DocumentCollection-${amplifyProjectInfo.projectName}`, {
name: ‘document-collection’,
type: ‘VECTORSEARCH’,
});
// Encryption policy is needed in order for the collection to be created
const encPolicy = new ops.CfnSecurityPolicy(this, `DocumentSecurityPolicy-${amplifyProjectInfo.projectName}`, {
name: ‘document-collection-policy’,
policy: ‘{"Rules":[{"ResourceType":"collection","Resource":["collection/document-collection"]}],"AWSOwnedKey":true}’,
type: ‘encryption’
});
collection.addDependency(encPolicy);
// Network policy is required so that the dashboard can be viewed!
const netPolicy = new ops.CfnSecurityPolicy(this, `DocumentNetworkPolicy-${amplifyProjectInfo.projectName}`, {
name: ‘document-network-policy’,
policy: ‘[{"Rules":[{"ResourceType":"collection","Resource":["collection/document-collection"]}, {"ResourceType":"dashboard","Resource":["collection/document-collection"]}],"AllowFromPublic":true}]’,
type: ‘network’
});
collection.addDependency(netPolicy);
const accessPolicy = [
{
"Description": "Access rule to allow actions on the OpenSearch cluster",
"Rules":[
{
"ResourceType":"collection",
"Resource":[
"collection/document-collection"
],
"Permission":[
"aoss:*"
]
},
{
"ResourceType":"index",
"Resource":[
"index/document-collection/*"
],
"Permission":[
"aoss:*"
]
}
],
// List of roles/users here
"Principal":[
"arn:aws:iam::<ACCOUNT_ID>:role/bedrockassistantLambdaRolexxxxx-dev",
"arn:aws:iam::<ACCOUNT_ID>:user/alatech"
]
}
]
// Access policy allowing Lambdas and users to access the collection and indexes
const cfnAccessPolicy = new ops.CfnAccessPolicy(this, `DocumentAccessPolicy-${amplifyProjectInfo.projectName}`, {
name: 'document-access-policy',
policy: JSON.stringify(accessPolicy),
type: 'data'
});
collection.addDependency(cfnAccessPolicy);
new cdk.CfnOutput(this, 'CollectionEndpoint', {
value: collection.attrCollectionEndpoint,
});
// Store the OpenSearch endpoint as SSM Parameter store (later will be fetched by Lambda)
const parameter = new ssm.StringParameter(this, `OpenSearchEndpoint-${amplifyProjectInfo.projectName}`, {
parameterName: '/opensearch/endpoint',
stringValue: collection.attrCollectionEndpoint,
});
}
}
The above code provisions an OpenSearch Serverless collection of type vector. This supports the storage of embeddings, which the AI assistant can later query. It will also provision several data access policies as part of the setup. The configuration is permissive for demo purposes, as ideally, the cluster should be placed in a private VPC.
Prepare the Lambda glue
The Indexing Lambda is triggered when a new document is uploaded to an S3 bucket and indexes into the OpenSearch Serverless vector database. This type of database is designed to store and retrieve vector data efficiently. In the context of machine learning and artificial intelligence, vector databases are often used to store embeddings or vector representations of data points.
import json
import boto3
from urllib.parse import unquote
from opensearchpy import OpenSearch, RequestsHttpConnection, exceptions
from requests_aws4auth import AWS4Auth
service = "aoss"
region = "us-east-1"
index = "ix_documents" # Index used to store documents
# Bedrock Runtime Client to invoke the Embedding
bedrock_client = boto3.client("bedrock-runtime", region_name=region)
# S3 Boto client to interact with S3 operations/bucket
s3 = boto3.client('s3')
# SSM Boto client used to fetch the OpenSearch collection generated from CDK
ssm = boto3.client('ssm')
endpoint = ssm.get_parameter(Name='/opensearch/endpoint')["Parameter"]["Value"].replace("https://", "")
# OpenSearch client used to store Bedrock Embeddings in the vector database
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key,
region, service, session_token=credentials.token)
ops_client = OpenSearch(
hosts=[{'host': endpoint, 'port': 443}],
http_auth=awsauth,
use_ssl=True,
verify_certs=True,
connection_class=RequestsHttpConnection,
timeout=300
)
def handler(event, context):
s3_key = unquote(event["Records"][0]["s3"]["object"]["key"]);
bucket_name = event["Records"][0]["s3"]["bucket"]["name"];
try:
# Retrieve S3 document content
response = s3.get_object(Bucket=bucket_name, Key=s3_key)
content = response['Body'].read().decode('utf-8')
# Call Bedrock Titan Embedding model to store embeddings
embedding = get_vector_embedding(content, bedrock_client)
# Create an index in the OpenSearch Serverless collection
create_index_if_not_present(index)
# Index content and its embedding in the vector database
response = indexEmbedding(embedding, content)
except Exception as e:
print(f"An error occurred: {e}")
return None
return {
'statusCode': 200,
'headers': {
'Access-Control-Allow-Headers': '*',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'OPTIONS,POST,GET'
},
'body': json.dumps(response)
}
def get_vector_embedding(text, bedrock_client):
response = bedrock_client.invoke_model(
body=json.dumps({ "inputText": text }),
modelId="amazon.titan-embed-text-v1",
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
return response_body.get("embedding")
def create_index_if_not_present(index) :
print(f'In create index')
if not ops_client.indices.exists(index):
# Define the settings and mappings for creating an OpenSearch index.
# It includes settings related to KNN (k-nearest neighbors)
# and defines two fields: "text" with the type "text" and "vector_field"
# with the type "knn_vector" and a specified dimension.
settings = {
"settings": {
"index": {
"knn": True,
}
},
"mappings": {
"properties": {
"text": {"type": "text"},
"vector_field": {
"type": "knn_vector",
"dimension": 1600,
},
}
},
}
res = ops_client.indices.create(index, body=settings, ignore=[400])
print(res)
def indexEmbedding(embedding, content) :
doc = {
'vector_field' : embedding,
'text': content
}
# Index the document in OpenSearch Serverless vector database
return ops_client.index(index, body=doc)
Comments in Lambda are self-explanatory; just a few notes:
- Right now, only the Bedrock Titan model can generate embeddings
- KNN search details can be found here.
- Be careful, as OpenSearch is very expensive, so you may need to consider different hosting solutions (Kendra or EC2)
AWS Credits saved the day:
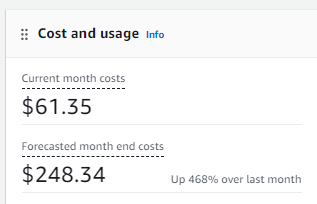
- Function IAM roles need proper access to SSM, OpenSearch (aoss) and Bedrock model.
- If you are curious about what an embedding looks like, see this:
Frontend upload
As the last step, users need to upload documents. Amplify comes with a native upload component via the Storage Manager library, which exposes a neat React component to upload documents to an S3 Bucket. Installation can be found in the link below:
Storage Manager | Amplify UI for React
The component will be used as below:
import { FileUploader } from '@aws-amplify/ui-react';
...
function Upload() {
return (
<div style={styles.container}>
<FileUploader
{/* Only text file types */}
acceptedFileTypes={['text/*']}
{/* Only Cognito authenticated users will be able to upload */}
accessLevel="private"
/>
</div>
);
}
Demo
Users upload some text files containing information.
Demo upload:

Files will be uploaded to S3 under a private/<COGNITO_IDENTITY_ID> folder because Amplify storage uses Cognito authentication to allow only authenticated users to upload to the bucket.
Documents uploaded to S3:
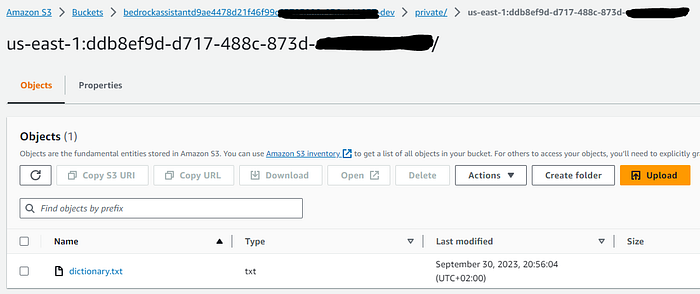
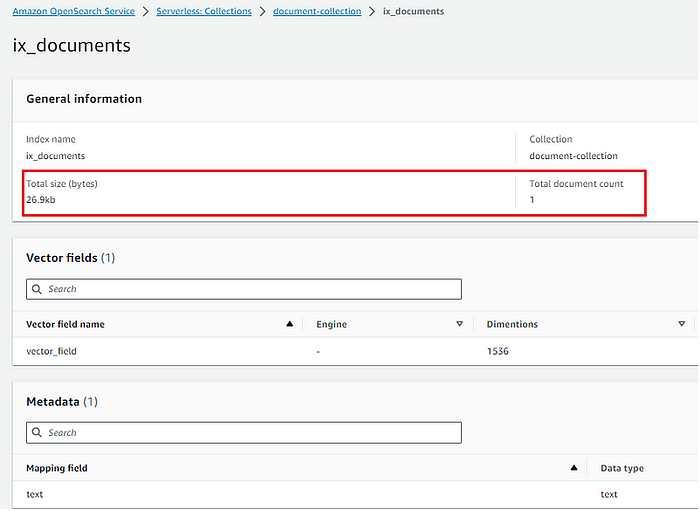
Finally, an index and the document were created within the OpenSearch Serverless cluster:
Data indexed in OpenSearch:
Conclusion
This article, part of a series documenting the evolution of an AI assistant, focused on how to index documents in OpenSearch Serverless using the Bedrock Titan Embedding model.
The next article will show how a Langchain-based function will consume this data and augment the Bedrock FM to provide contextual answers; stay tuned!
Comments
Loading comments…