As AI continues to evolve, chatbots are becoming increasingly sophisticated and human-like in their ability to respond to natural language inputs. One of the most impressive models in this space is OpenAI’s chatGPT, which has set new standards for language understanding and generation. But what if you could have your own chatbot that could answer your questions, provide information, and even make jokes, just like chatGPT? With recent advancements in fine-tuning techniques, it is now possible to create your own high-quality chatbot by fine-tuning a pre-trained model. In this article, we’ll take a look at how to create your own chatbot using a fine-tuning technique called LoRA (Low Rank Adaptation) and the pre-trained model flan-T5 XXL.
What is LoRA?
LoRA is a fine-tuning technique that offers a new way to improve the performance of pre-trained language models on specific tasks. Unlike traditional fine-tuning methods that train the entire model on new data, LoRA freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture. This greatly reduces the number of trainable parameters, which can lead to faster fine-tuning and reduced overfitting.
According to the LoRA paper, compared to fine-tuning GPT-3 175B with Adam, LoRA can reduce the number of trainable parameters by a factor of 10,000 and the GPU memory requirement by a factor of 3. This makes it an efficient and effective way to fine-tune pre-trained large models for specific tasks.
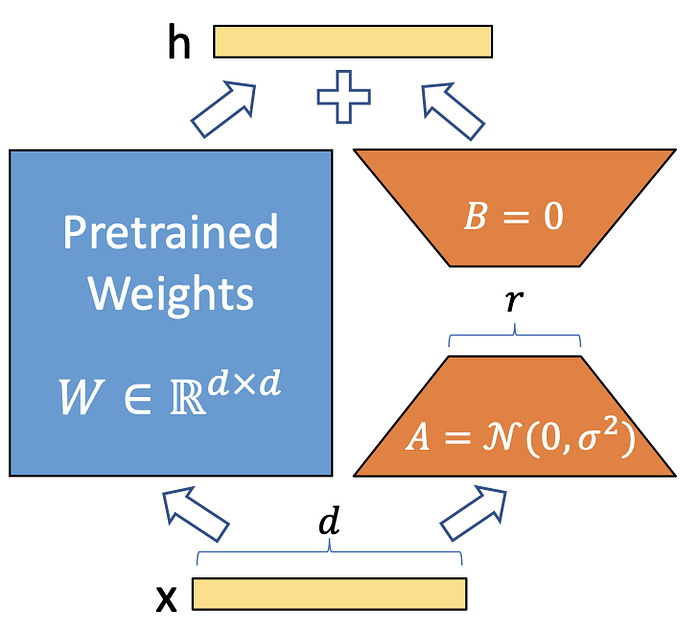
Illustration of how LoRA works
What is Flan-T5 XXL?
Flan-T5 is a state-of-the-art pre-trained language model that has been fine-tuned using the technique of instruction fine-tuning. This technique has been shown to improve model performance and generalization to unseen tasks by fine-tuning the model on a collection of datasets phrased as instructions. XXL stands for the model size, this model is the biggest version of FLAN-T5 with 11B params.
Dataset
For the purpose of this experiment, we will use two datasets:
https://huggingface.co/datasets/Hello-SimpleAI/HC3
and
https://huggingface.co/datasets/MohamedRashad/ChatGPT-prompts
Please note that these datasets contain outputs from chatGPT which violates chatGPT's terms of service, thus I won't release the final trained model and this post will serve as an educational experiment.
Steps to Fine-Tune Flan-T5 XXL with LoRA
- First, you need to install the dependencies, we will be using transformers, datasets, accelerate, DeepSpeed and peft;
- Next, we join the two datasets;
import pandas as pd
import json
# Opening JSON file
f1 = open('data/all.jsonl')
f2 = open('data/train.jsonl')
Lines1 = f1.readlines()
Lines2 = f2.readlines()
questions, answers = [], []
for line in Lines1:
row = json.loads(line)
for answer in row["human_answers"]:
questions.append("Human: "+row["question"])
answers.append("Assistant: "+answer)
for answer in row["chatgpt_answers"]:
questions.append("Human: "+row["question"])
answers.append("Assistant: "+answer)
for line in Lines2:
row = json.loads(line)
history = row["chosen"]
split = history.split("Assistant:")
question = history.replace("Assistant:"+split[-1],"")
answer = "Assistant:"+split[-1]
questions.append(question)
answers.append(answer)
df = pd.DataFrame()
df["question"] = questions
df["answer"] = answers
df.to_csv("data/train.csv", index=False)
-
You should configure your accelerate to work with DeepSpeed, for that you just need to type "accelerate config" on your console, it is interesting to use DeepSpeed stage 3 offload in order to save resources;
-
Next, we call our training script with "accelerate launch train_lora.py".
import os
import torch
from accelerate import Accelerator
from torch.utils.data import DataLoader
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, default_data_collator, get_linear_schedule_with_warmup, DataCollatorForSeq2Seq
from datasets import load_dataset
from peft import LoraConfig, TaskType, get_peft_model, get_peft_model_state_dict
from peft.utils.other import fsdp_auto_wrap_policy
from tqdm import tqdm
def main():
accelerator = Accelerator()
model_name_or_path = "google/flan-t5-xxl"
batch_size = 2
max_length = 512
lr = 1e-4
num_epochs = 1
train_data = "./data/train.csv"
test_data = "./data/val.csv"
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
checkpoint_name = "chaT5_lora.pt"
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
model = get_peft_model(model, peft_config)
accelerator.print(model.print_trainable_parameters())
dataset = load_dataset(
'csv', data_files={
"train": train_data,
"validation": test_data,
},
cache_dir="./cache")
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
def preprocess_function(examples):
inputs = [doc for doc in examples["question"]]
model_inputs = tokenizer(
inputs, max_length=max_length, padding=True, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(
examples["answer"], max_length=max_length, padding=True, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
with accelerator.main_process_first():
processed_datasets = dataset.map(
preprocess_function,
batched=True,
num_proc=16,
remove_columns=dataset["train"].column_names,
load_from_cache_file=False,
desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
data_collator = DataCollatorForSeq2Seq(
tokenizer, model=model)
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(
eval_dataset, collate_fn=data_collator, batch_size=batch_size, pin_memory=True
)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=(len(train_dataloader) * num_epochs),
)
if getattr(accelerator.state, "fsdp_plugin", None) is not None:
accelerator.state.fsdp_plugin.auto_wrap_policy = fsdp_auto_wrap_policy(model)
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler = accelerator.prepare(
model, train_dataloader, eval_dataloader, optimizer, lr_scheduler
)
accelerator.print(model)
accelerator.state.deepspeed_plugin.zero_stage == 3
for epoch in range(num_epochs):
model.train()
total_loss = 0
for step, batch in enumerate(tqdm(train_dataloader)):
outputs = model(**batch)
loss = outputs.loss
total_loss += loss.detach().float()
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
if step%1000 == 0:
print("loss: ",loss.detach().float())
accelerator.wait_for_everyone()
if accelerator.is_main_process:
accelerator.save(
get_peft_model_state_dict(model, state_dict=accelerator.get_state_dict(model)), checkpoint_name
)
model.eval()
eval_loss = 0
eval_preds = []
for step, batch in enumerate(tqdm(eval_dataloader)):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
eval_loss += loss.detach().float()
preds = accelerator.gather_for_metrics(torch.argmax(outputs.logits, -1)).detach().cpu().numpy()
eval_preds.extend(tokenizer.batch_decode(preds, skip_special_tokens=True))
eval_epoch_loss = eval_loss / len(train_dataloader)
eval_ppl = torch.exp(eval_epoch_loss)
train_epoch_loss = total_loss / len(eval_dataloader)
train_ppl = torch.exp(train_epoch_loss)
accelerator.print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
accelerator.wait_for_everyone()
accelerator.save(
get_peft_model_state_dict(model, state_dict=accelerator.get_state_dict(model)), checkpoint_name
)
accelerator.wait_for_everyone()
if __name__ == "__main__":
main()
By utilizing both LoRA and DeepSpeed, we were able to achieve an impressive optimization in training large language models (LLMs) using only 65GB of VRAM. This is especially noteworthy given that the weights of the models alone, stored in fp32 format, take up about 40GB.
Results
After fine-tuning the Flan-T5 XXL model with the LoRA technique, we were able to create our own chatbot. The quality of the text generated by the chatbot was good, but it was not as good as that of OpenAI’s ChatGPT. We noticed that the chatbot made mistakes and was sometimes repetitive. This can be attributed to the difference in parameters between the two models — while ChatGPT has 175 billion parameters, Flan-T5 has only 11 billion. Additionally, the training dataset used for fine-tuning could be improved to further enhance the quality of the generated text. Despite these limitations, the results still showed that fine-tuning the Flan-T5 XXL model with LoRA is a promising technique for creating a chatbot.
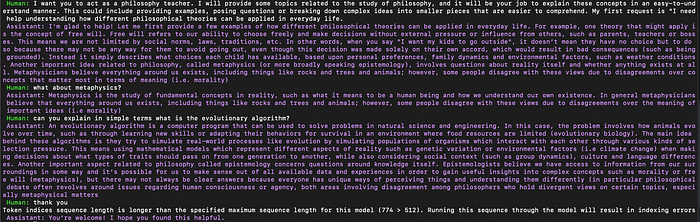
Example of a conversation with the fine-tuned model Example of a conversation with the fine-tuned model
Conclusion
With the use of pre-trained models and fine-tuning techniques such as LoRA, it is now possible to create high-quality chatbots that can answer questions, provide information, and engage in conversation. By following the steps outlined in this article, you can fine-tune the flan-T5 XXL model to create your own chatbot that is capable of understanding and generating natural language.
Next Steps
The key to producing high-quality text generation with ChatGPT is not solely based on the training data. In the future, I plan to delve deeper into the technique of RLHF and investigate how it can be utilized in the training of large language models (LLMs).
Comments
Loading comments…