
The Repository Design Pattern separates the data access logic from the business logic. The basic idea is to create some sort of abstract layer between the application and the data storage. This abstract layer is called the repository. It provides a set of methods for the application to interact with data.
The previous pattern in the series:
Design Patterns in Python: Null Object Pattern
The Repository Design Pattern can be seen as both a type of Facade and a type of Factory pattern. Like a Facade (structural design pattern), it provides a simplified interface for accessing a complex system, while like a Factory (creational design pattern), it creates objects in a flexible and extensible way. Additionally, since the Repository often provides a collection-like interface, it can also be seen as a special use case of the Iterator (behavioral design pattern), which provides a way to iterate over a collection of objects. Even so, Repository Design Pattern is a distinct pattern in its own right.
When the application needs to interact with the data, it calls the appropriate method on the repository. The repository then translates this method call into the appropriate query or command for the data storage mechanism.
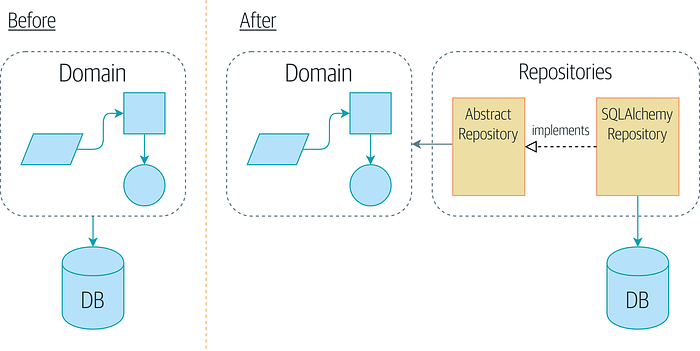
Before and after the Repository pattern (Source):
💡 Speed up your blog creation with DifferAI.
Available for free exclusively on the free and open blogging platform, Differ.
Implementation
First, we define an abstract IRepository interface.
from abc import ABC, abstractmethod
class IRepository(ABC):
@abstractmethod
def get_all(self):
raise NotImplementedError
@abstractmethod
def get_by_id(self, id):
raise NotImplementedError
@abstractmethod
def create(self, item):
raise NotImplementedError
@abstractmethod
def update(self, item):
raise NotImplementedError
@abstractmethod
def delete(self, id):
raise NotImplementedError
The InMemoryRepository class implements the IRepository interface and provides an in-memory data storage mechanism.
class InMemoryRepository(IRepository):
def __init__(self):
self._data_source = []
def get_all(self):
return self._data_source
def get_by_id(self, id):
return next((item for item in self._data_source if item['id'] == id), None)
def create(self, item):
item['id'] = len(self._data_source) + 1
self._data_source.append(item)
return item
def update(self, item):
index = next((i for i, obj in enumerate(self._data_source) if obj['id'] == item['id']), None)
if index is not None:
self._data_source[index] = item
return True
return False
def delete(self, id):
index = next((i for i, obj in enumerate(self._data_source) if obj['id'] == id), None)
if index is not None:
self._data_source.pop(index)
return True
return False
We define another class, SQLRepository that implements the IRepository interface and uses a SQL database as the data storage mechanism. This class can be used interchangeably with the InMemoryRepository class, as they both implement the same IRepository interface.
class SQLRepository(IRepository):
def __init__(self, connection_string):
# initialize database connection
self._connection_string = connection_string
self._connection = db.connect(connection_string)
def get_all(self):
# query all records from database
cursor = self._connection.cursor()
cursor.execute("SELECT * FROM items")
results = cursor.fetchall()
return results
def get_by_id(self, id):
# query record by id from database
cursor = self._connection.cursor()
cursor.execute("SELECT * FROM items WHERE id=?", (id,))
result = cursor.fetchone()
return result if result is not None else None
def create(self, item):
# insert record into database
cursor = self._connection.cursor()
cursor.execute("INSERT INTO items(name, description) VALUES (?, ?)", (item['name'], item['description']))
self._connection.commit()
item['id'] = cursor.lastrowid
return item
def update(self, item):
# update record in database
cursor = self._connection.cursor()
cursor.execute("UPDATE items SET name=?, description=? WHERE id=?", (item['name'], item['description'], item['id']))
self._connection.commit()
return cursor.rowcount > 0
def delete(self, id):
# delete record from database
cursor = self._connection.cursor()
cursor.execute("DELETE FROM items WHERE id=?", (id,))
self._connection.commit()
return cursor.rowcount > 0
It makes it easier to scale an application by allowing multiple data storage mechanisms to be used interchangeably.
Let’s write a random service that utilizes the repositories and a client code:
class ItemService:
def __init__(self, repository):
self._repository = repository
def get_all_items(self):
return self._repository.get_all()
def get_item_by_id(self, id):
return self._repository.get_by_id(id)
def create_item(self, name, description):
item = {'name': name, 'description': description}
return self._repository.create(item)
def update_item(self, id, name, description):
item = self._repository.get_by_id(id)
if item is None:
return False
item['name'] = name
item['description'] = description
return self._repository.update(item)
def delete_item(self, id):
return self._repository.delete(id)
# client code
in_memory_repository = InMemoryRepository()
item_service = ItemService(in_memory_repository)
item_service.create_item('item 1', 'description 1')
item_service.create_item('item 2', 'description 2')
items = item_service.get_all_items()
print(items)
item = item_service.get_item_by_id(1)
print(item)
item_service.update_item(2, 'updated item', 'updated description')
items = item_service.get_all_items()
print(items)
item_service.delete_item(1)
items = item_service.get_all_items()
print(items)
The most notable benefit of this implementation here is the separation of concern. We are separating data access and manipulation concerns from the rest of the structure. The IRepository defines a set of methods to interact with the data, while the implementations handle the specific details for each unique structure.
The client code creates an instance of the InMemoryRepository and passes it to the ItemService constructor. It then uses the ItemService methods to operate on the data store. Since the ItemService depends on the IRepository interface (Dependency Inversion Principle), the client code is decoupled from the implementation details of the Repository and can easily switch to a different implementation of the IRepository interface.
For testing purposes, we can define a set of unit tests for the ItemService class. MockRepository provides a fake implementation of the IRepository interface which allows us to control the behavior of the repository for testing purposes.
import unittest
class TestItemService(unittest.TestCase):
def setUp(self):
self.mock_repository = MockRepository()
self.item_service = ItemService(self.mock_repository)
def test_create_item(self):
item = self.item_service.create_item('item 1', 'description 1')
self.assertIsNotNone(item)
self.assertEqual(item['name'], 'item 1')
self.assertEqual(item['description'], 'description 1')
self.assertTrue(self.mock_repository.create_called)
def test_update_item(self):
self.mock_repository.set_return_value({'id': 1, 'name': 'item 1', 'description': 'description 1'})
result = self.item_service.update_item(1, 'updated item', 'updated description')
self.assertTrue(result)
self.assertTrue(self.mock_repository.update_called)
def test_delete_item(self):
self.mock_repository.set_return_value({'id': 1, 'name': 'item 1', 'description': 'description 1'})
result = self.item_service.delete_item(1)
self.assertTrue(result)
self.assertTrue(self.mock_repository.delete_called)
if __name__ == '__main__':
unittest.main()
By using a mock implementation of the IRepository, we can isolate the ItemService from the details of how the data is operated. This makes unit tests easier to write, understand, and maintain.
The Repository Design Pattern is an important architectural pattern in software development as it provides a standardized way of accessing data and abstracts away the details of data storage and retrieval from the rest of the application. This promotes the separation of concerns, making it easier to maintain and test the codebase. It also enables better scalability by allowing multiple data sources to be used interchangeably without affecting the application logic.
Next:
Design Patterns in Python: Unit of Work Pattern
Comments
Loading comments…