Parquet is an open-sourced columnar storage format created by the Apache software foundation. Parquet is growing in popularity as a format in the big data world as it allows for faster query run time, it is smaller in size and requires fewer data to be scanned compared to formats such as CSV. Many cloud computing services already support Parquet such as AWS Athena, Amazon Redshift Spectrum, Google BigQuery and Google Dataproc. If you want to keep up in the data world, you're going to want to learn how to read with Python.
This walkthrough will cover how to read Parquet data in Python without then need to spin up a cloud computing cluster. It can easily be done on a single desktop computer or laptop if you have Python installed without the need for Spark and Hadoop. To follow along all you need is a base version of Python to be installed. This version of Python that was used for me is Python 3.6.
First, we are going to need to install the 'Pandas' library in Python. Within your virtual environment in Python, in either terminal or command line:
pip install pandas
We are then going to install Apache Arrow with pip. It is a development platform for in-memory analytics. It will be the engine used by Pandas to read the Parquet file.
pip install pyarrow
Now we have all the prerequisites required to read the Parquet format in Python. Now we can write a few lines of Python code to read Parquet. (if you want to follow along I used a sample file from GitHub: https://github.com/Teradata/kylo/tree/master/samples/sample-data/parquet)
import pandas as pd #import the pandas library
parquet_file = 'location\to\file\example_pa.parquet'
pd.read_parquet(parquet_file, engine='pyarrow')
This is what the output would look like if you followed along using a Jupyter notebook:
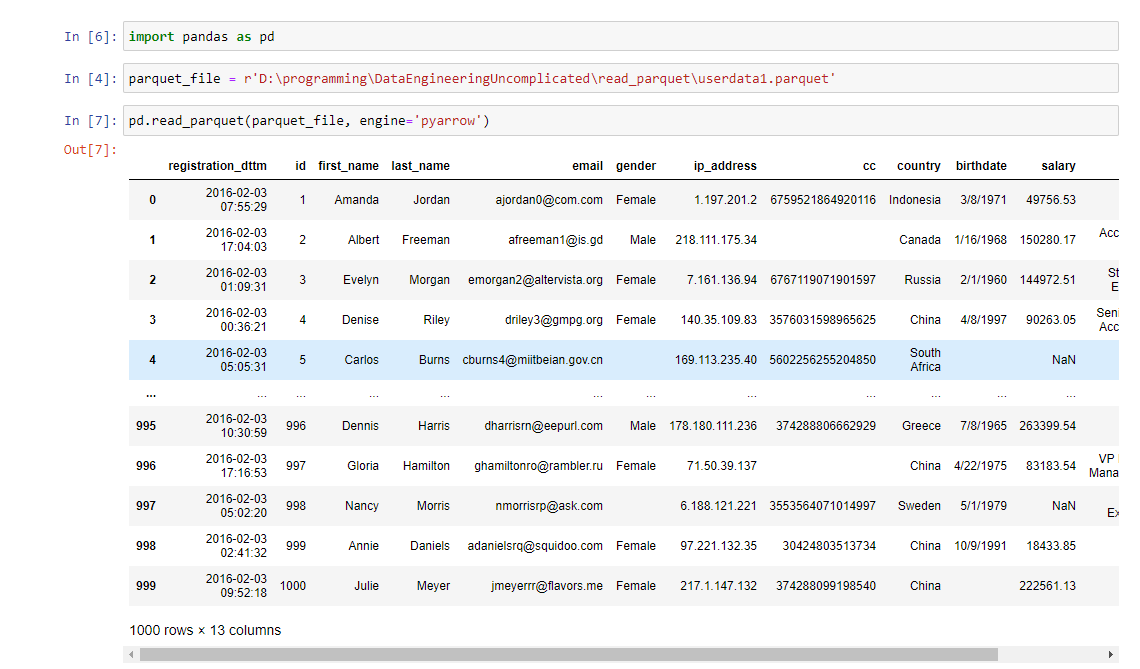
Conclusion
Now you can continue on in Python with whatever analysis you want to perform on your data. Keep an eye on how large the file is that you are trying to read into your local machine. If the file is too large, your machine may struggle since it is not a distributed cluster. To follow along with this tutorial in video format step by step, check out:
I hope you enjoyed reading this.
If this video is helpful, consider subscribing to my YouTube channel.
Comments
Loading comments…