What Are We Going to Build?
The goal is to get you going quickly with a web app that has all the basic components, so we’re beginning with something simple yet powerful: A Chatbot that answers questions about a given website.
A Simple Web Application
- Scrapes the given site with set rules for links to follow and index.
- Cleans the scraped data to reduce noise using BeautifulSoup.
- Indexes the information by using OpenAI’s Embeddings and stores them in a local Chroma vector database.
- Once the vector db is ready, it will answer user questions by searching for semantically similar information chunks, providing those to an LLM, and generating a final response to the user. We will use LangChain to simplify this prompt chain.
In summary, we’re building a “question-answering” web app that uses information from a chosen website, in our case Bootstrap’s 5.3 documentation.
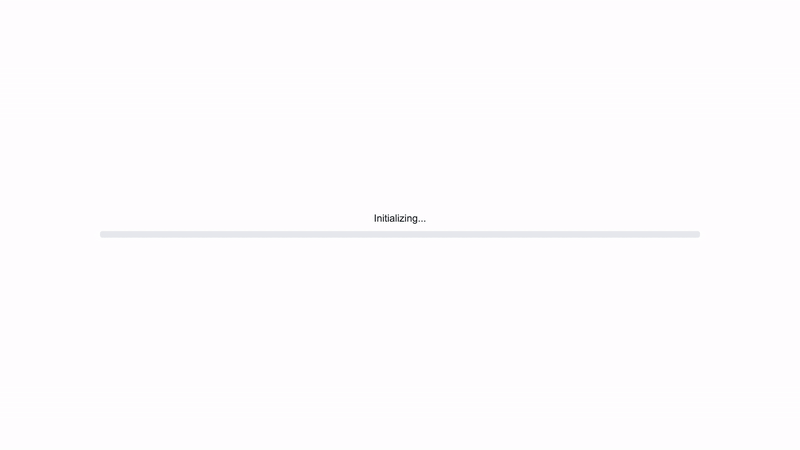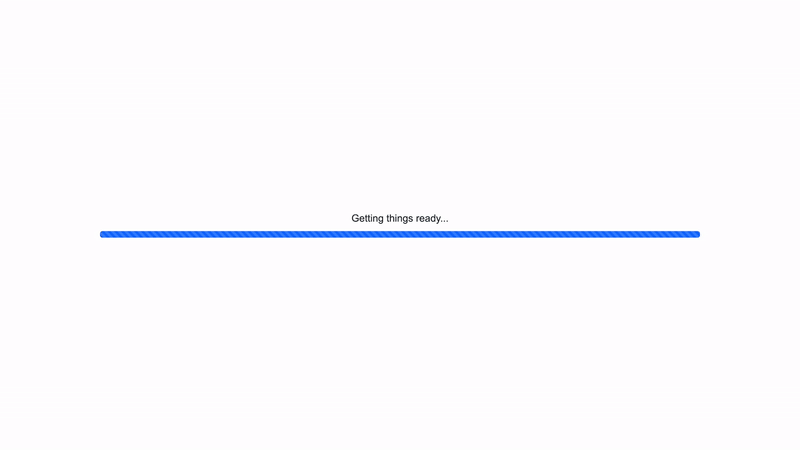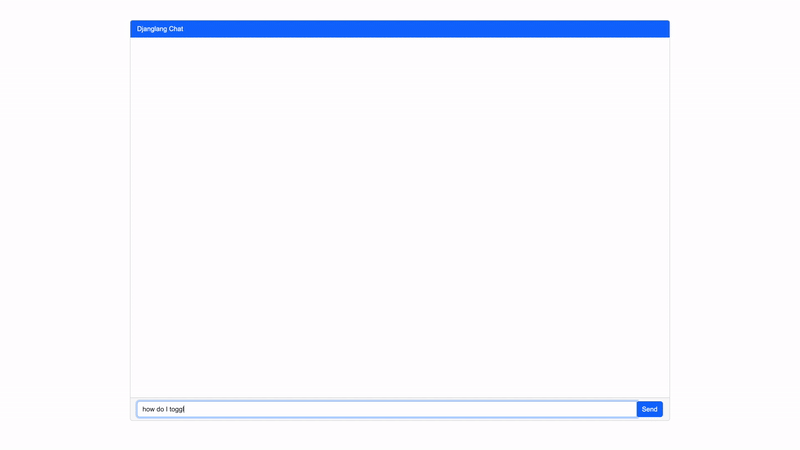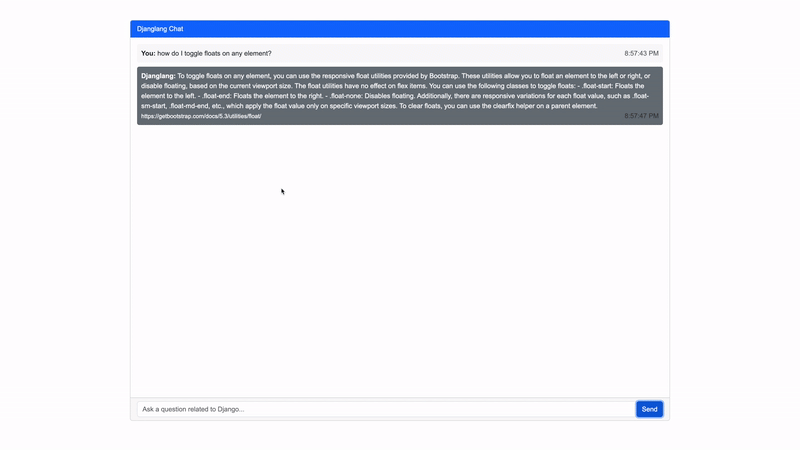
What are we not going to build?
To keep this to a short tutorial, we’re going to take some shortcuts and avoid getting into topics that merit dedicated guides. These 4 are some of the most important areas you will need to re-evaluate for each of your projects:
- Embedding & LL Models selection: We’re using OpenAI for both embeddings and LLM for ease of use. Most developers interested in AI will already have an API key. But you will most likely want to use a different combination of models for other use cases.
- Chunking: We will divide our data into simple chunks based on tokens for this guide, you should test variations of tokens, sentence splitters or build custom splitters that work for your project. There are even recent projects that use train models to find the ideal chunking given a document.
- Vector Storage: This guide uses chroma locally, which is different from what you want to deploy. You will need either a separate instance running Chroma, pgvector, Qdrant, or a managed service like Pinecone.
- Search: For most real use cases, you will want to go beyond the basic retriever. Explore the options in langchain for self-query retrievers, as well as other techniques like query expansion, cross-encoding + re-ranking, or embedding adaptors.
I recommend deeplearning.ai’s free chroma short course if you want to go deeper on advanced retrieval techniques specifically.
Question Answering Over a Webpage?
To leverage the power of a Language Learning Model (LLM) like ChatGPT for data it wasn’t specifically trained for, we use a technique called “retrieval-augmented generation” or “RAG”. When a specific question about Bootstrap documentation is asked, we must find the relevant part and pass it as context to the LLM. This is where vector databases and embeddings come into play.
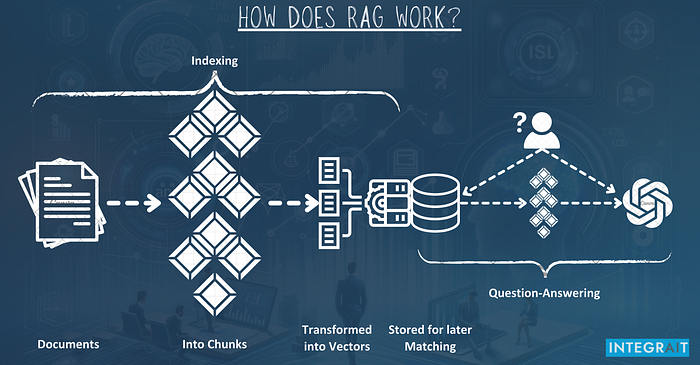
📒 An embedding is a vector (list) of floating-point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness, and large distances suggest low relatedness.
Initial Setup
Start Your Virtual Environment
Navigate to your working directory or create a new one for this project. Create a virtual environment in this folder:
python3.8 -m venv <venv_folder>
Replace <venv_folder> with the directory name where you want your virtual environment to be created. Leave it empty to create it in the same folder.
Activate the virtual environment:
source <venv_folder>/bin/activate
You should see your shell prompt change, indicating you are now in a virtual environment.
Install Dependencies
First, install Django if you haven’t already:
pip install django
Start a new Django project in your current directory:
django-admin startproject djanglang .
Install the rest of the necessary libraries:
pip install openai tiktoken langchain langchain-openai chromadb requests bs4 djangorestframework environs
Run migrations for the basic Django apps:
python manage.py migrate
Start the server:
python manage.py runserver
Open a browser and go to 127.0.0.1:8000 to see the default Django index page.
Set Your OpenAI API Key
Create a .env file and add your OpenAI API key:
OPENAI_API_KEY='your-api-key'
We use environs to read this .env file and LangChain will look for the OPENAI_API_KEY value.
Create a Simple Chat App
Run the following command to create a new app. Replace <your-app-name> with the name you prefer; for reference, we used base.
django-admin startapp <your-app-name>
Update Views and URLs
Update views.py with a simple function to handle user interactions:
from django.http import JsonResponse, HttpResponse
from django.shortcuts import render
def index(request):
if request.method == 'POST':
query = request.POST.get('query')
result = {} # Here, we will later get results from embeddings
return JsonResponse(result)
return render(request, 'base/index.html')
Later in the guide we will create the chat template, and fill the results for the user question.
Update your urls.py files for both the main app and your new app:
djanglang/urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('', include('base.urls')),
path('admin/', admin.site.urls),
]
base/urls.py
from django.urls import path
from . import views
urlpatterns = [
path('', views.index, name="index"),
]
A Simple Interface
Let’s put together a chat interface for users to interact with our chatbot. We can use Bootstrap for a basic grid and late 2010s styling. The UI includes an input field for user queries and a display area for the chatbot’s responses.
<!DOCTYPE html>
<html lang="en">
<head>
<!-- Meta tags and Bootstrap CSS -->
</head>
<body>
<div id="loadingScreen" class="d-flex justify-content-center align-items-center vh-100">
<!-- Initialization message and progress bar -->
</div>
<div class="container mt-5" id="djanglang-chat-container">
<div class="card">
<!-- Chat interface -->
</div>
</div>
<!-- Bootstrap JS and custom scripts -->
</body>
</html>
The UI script handles user interactions, displaying a loading screen while the database is being prepared, and dynamically updating the chat area as the conversation progresses. It is a little long to paste here but is very simple, you can refer to it here.
Adding the Core Logic: LangChain & BeautifulSoup
We’ll use BeautifulSoup4 for web scraping and LangChain’s Indexes to extract and transform the information we need, once we have embeddings, we will store them in Chroma for later retrieval.
First, let’s update views.py to outline what we want to achieve:
from django.http import JsonResponse, HttpResponse
from django.shortcuts import render
def index(request):
if request.method == 'POST':
query = request.POST.get('query')
result = {} # Here, we will get results from embeddings
return JsonResponse(result)
# Here, we will create a database if we don't have one as the user loads onto the page
return render(request, 'base/index.html')
Custom Web Scraping
The first thing you want to do in any project that involves scraping is inspecting the site(s) you are going to extract information from. As our project comprises only one single site, let’s take a look at the HTML structure of the Bootstrap 5.3 site.
In case you don’t know. All browsers allow you to inspect the rendered HTML and the source HTML. The rendered HTML includes the result of any executed JavaScript, whilst the source code is what you get when you make a simple GET request to the URL. If you want to learn more about this check out other sources.
So, inspecting in-page (⌘⌥+I) is useful but it may not be what you get when you scrape without rendering JavaScript. Use inspecting for a first review but check the HTML (⌘⌥+U).
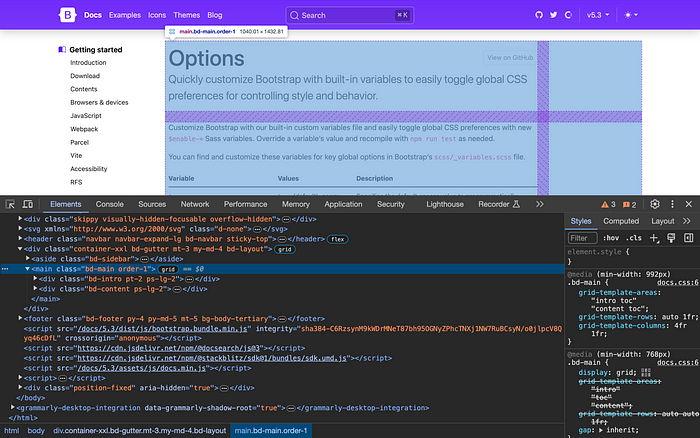
https://getbootstrap.com/docs/5.3/getting-started/contents/
In this image, we can see that all the content we need is inside the <main> element. We could get finer, but this will suffice for now.
Let’s create a new Python file named logic.py in your app directory to hold the classes we’ll use for web scraping, embedding the content, and retrieving results.
Fetching Documentation URLs
The first step is to build a list of the URLs that we will later scrape. We accomplish this by starting with one URL and creating a list of all the relevant links we find inside of that page, following them, and doing the same until we don’t get new links or some other limit is reached. To simplify our project, we’re going to start with an index page that already has all the links we need.
def bootstrap_docs_build_urls():
root_url = "https://getbootstrap.com/docs/5.3/getting-started/contents/"
root_response = requests.get(root_url)
root_html = root_response.content.decode("utf-8")
soup = BeautifulSoup(root_html, 'html.parser')
root_url_parts = urlparse(root_url)
root_links = soup.find_all("a", attrs={"class": "bd-links-link d-inline-block rounded"})
result = set()
for root_link in root_links: # standardize all links we find
path = root_link.get("href")
path = str(Path(path).resolve())
path = urlparse(path).path # remove the hashtag
url = f"{root_url_parts.scheme}://{root_url_parts.netloc}{path}"
if not url.endswith("/"):
url = url + "/"
result.add(url)
return list(result)
This function uses BeautifulSoup to parse the HTML content of the root URL and extract relevant links based on specific HTML attributes that we inspected on the page.
Custom WebBaseLoader
Continuing with the scraping, now that we have the links, we will customize LangChain’s WebBaseLoader to take only the relevant parts of each page. Here’s how you can do it:
class CustomWebBaseLoader(WebBaseLoader):
def _scrape(self, url: str, parser: Union[str, None] = None, bs_kwargs: Optional[dict] = None) -> Any:
html_content = super()._scrape(url, parser)
main_tag = html_content.find('main') # Find the <main> tag
return BeautifulSoup(main_tag.text, "html.parser", **(bs_kwargs or {})) # Here we’re overriding the basic scraper to take only the contents from the main tag, with a couple of lines we’re avoiding already a lot of noise that we would otherwise get in the scrape.
The only relevant change here and the reason we’re doing this is to get only the <main>tag from the content.
Go beyond: If you want to capture rendered HTML, you will need to use other options like a headless instance of Chromium and the asyncio library. [ref]
Building a Searchable Database
The heart of our chatbot lies in its ability to search through the documentation and use relevant pieces of content to write an answer. To achieve this, we’ll build a searchable database with the content of the URLs we have listed.
Loading the Documents
Once we have the URLs, the load() method fetches the HTML content as defined in our CustomWebBaseLoader, and converts it into a list of Document objects.
# Get the list of URLs to scrape
urls = bootstrap_docs_build_urls()
loader = CustomWebBaseLoader(urls)
documents = loader.load()
Text Splitting
There are many ways to split content, you should always consider this a hyperparameter to fine-tune in your project. This is crucial for handling large documents and making the search more efficient later on.
In this case, we will use the RecursiveCHaracterTextSplitterclass to split the content of each document into smaller text chunks.
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000, chunk_overlap=0)
splits = splitter.split_documents(documents)
The chunk_size set to 1000 means the splitter will aim to create chunks of text each containing a maximum of 1000 tokens.
The chunk_overlap parameter is set to 0, as we want no overlap between adjacent chunks.
Embedding the Text
Next, the key to most RAG architectures today: we will create a representation of this chunk collection that we can later search.
We use the OpenAIEmbeddings class to convert these text chunks into numerical vectors, also known as embeddings.
embeddings = OpenAIEmbeddings()
Creating the Database
We want to store these embeddings in a way that we can check for distances from each vector to new ones (user questions) later. There is a wide selection for vector storage, you can read more on that at the start of this article. For this project, we will be using the Open Source Chroma using local memory.
We then use the Chroma.from_documents() method to build the searchable database. We pass in the split documents, their embeddings from OpenAI, and additional parameters like the collection name and directory where the database should be persisted.
db = Chroma.from_documents(
splits,
embeddings,
collection_name="bootstrap_docs",
persist_directory=CHROMA_DB_DIRECTORY,
)
Persisting the Database
Finally, we call the db.persist() method to save the database. This makes it available for future use without having to rebuild it.
db.persist()
By following these steps, you'll have a fully functional, searchable database built on top of the Bootstrap documentation. This enables the chatbot to quickly perform complex queries and provide relevant, accurate answers.
To see the building of the database from links comes together, take a look at the completed class build_database() in the Github repo [logic.py].
Handling User Queries
The last function in our logic.py file handles the questions that will come from the users in the chat.
def answer_query(query):
embeddings = OpenAIEmbeddings() # Get the vector representation for the user question
db = Chroma( # Fetch the vector collection to compare against the question
collection_name="bootstrap_docs",
embedding_function=embeddings,
persist_directory=CHROMA_DB_DIRECTORY
)
chat = ChatOpenAI(temperature=0)
chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=chat, # OpenAI default (gpt-3.5), with low t for more deterministic output
chain_type="stuff", # LangChain provides shortcuts with prefilled prompts
retriever=db.as_retriever(), # Use the chroma DB to check for results
chain_type_kwargs={"verbose": True} # Log everything
)
result = chain({"question": query}, return_only_outputs=True)
return result
Here, we compare the embedding representation for the user question against the database of vectors for the content we have indexed. Then, LangChain will use a pre-filled prompt with few-shot examples, as well as any results it finds to prompt gpt-3.5 and get an answer based on the chunks that matched our chroma collection.
Connecting Interface and Logic
We can finally go back to the views.py file in our Django project and connect the user interface with the backend logic. It includes views to handle user queries, check the database status, and initiate the database-building process.
from django.http import JsonResponse
from django.shortcuts import render
from .logic import answer_query, build_database, database_exists # Import your logic functions here
import threading
def index(request):
if request.method == 'POST':
query = request.POST.get('query')
result = answer_query(query)
return JsonResponse(result)
return render(request, 'base/index.html')
def db_status(request):
status = {
'exists': database_exists(),
'message': 'Database exists' if database_exists() else 'Database is being built'
}
return JsonResponse(status)
def build_db(request):
# Use threading to build the database asynchronously
thread = threading.Thread(target=build_database)
thread.start()
return JsonResponse({'status': 'Building database...'})
To ensure that the chatbot is ready to answer queries, we build the database on page load if it doesn’t already exist. This process is initiated in the background, allowing the user to interact with the chatbot without delay once the database is ready. If it is ready on load, there will be no delay.
Next Steps
Congratulations, you've got Django Langchained! a chatbot capable of answering questions based on Bootstrap documentation! From here, if you’re testing the limits of a hobby project, you could extend it project by adding more features like voice recognition, and other document sources, or integrating it into a larger system. There are also interesting auto scrapers you can put together to have a know-any-site chatbot.
If you want to build a production application, start to think about the elements we pointed out at the start of the article. Start experimenting with your choice of models, customize the document or site processing for the needs of your application, and share (if you can) what you build!
Check out the demo code on GitHub:
- The code used for this article is in the simplest-version branch.
- The hosted version of a similar use case can be seen at integrait.solutions.
Troubleshooting
If you encounter any issues, here are some common errors and their solutions:
- Database not loading: Ensure that the
CHROMA_DB_DIRECTORYis correctly set and has the necessary permissions. - API Key Issues: Double-check your
.envfile to ensure the OpenAI API key is correctly set. - Server Errors: Check the server logs for any exceptions or errors that can guide you to the issue.
Connect with me directly via Email, find me on LinkedIn, or explore a partnership at integrait.solutions to craft AI solutions that deliver competitive advantage.

Comments
Loading comments…