The Backends-for-frontends (BFF) pattern, first described by Sam Newman, and first used at SoundCloud, is an effective solution when you have multiple client platforms -- web browsers, mobile apps, gaming consoles, IoT devices -- each with unique requirements for data, caching, auth, and more.
The BFF is a custom interface (maintained by the frontend team) that is purpose built for the needs of each client platform, serving as the only “backend” as far as the client is concerned. It sits between the client and underlying data sources/microservices, keeping them decoupled, and giving each client team full control over how they consume, consolidate, and massage data from downstream API dependencies -- and handle their errors.
But the BFF pattern, like anything else in engineering, has its tradeoffs and drawbacks. As it turns out, though, GraphQL is great at shoring up these flaws, and a GraphQL driven BFF layer works well. However, GraphQL brings with it its own set of problems!
Starting to sound like a broken record, here. How do we break the cycle? Let’s talk about it, with a look at a free and open-source technology -- WunderGraph -- that can help us.
Backends-for-Frontends ❤ GraphQL
BFFs afford you the luxury of maintaining and securing only a single entry point like you do in simple monoliths, while still working with microservices internally. This gives the best of both worlds, but that kind of agility comes at a price. Let’s take a look at some of these issues, and how GraphQL nullifies them:
1. BFFs work great as an aggregation layer, but you still need multiple requests to get the data you want, and this scales linearly with the number of Microservices/API/Data dependencies you have. Multiple network hops add latency.
GraphQL works great in minimizing multiple round trips because it natively enables clients to request multiple resources and relationships in a single query.
2. Overfetching and underfetching might still be problems because of a combination of how RESTful architectures inherently operate, and the fact that you may be relying on legacy or third-party APIs whose architectures you do not own.
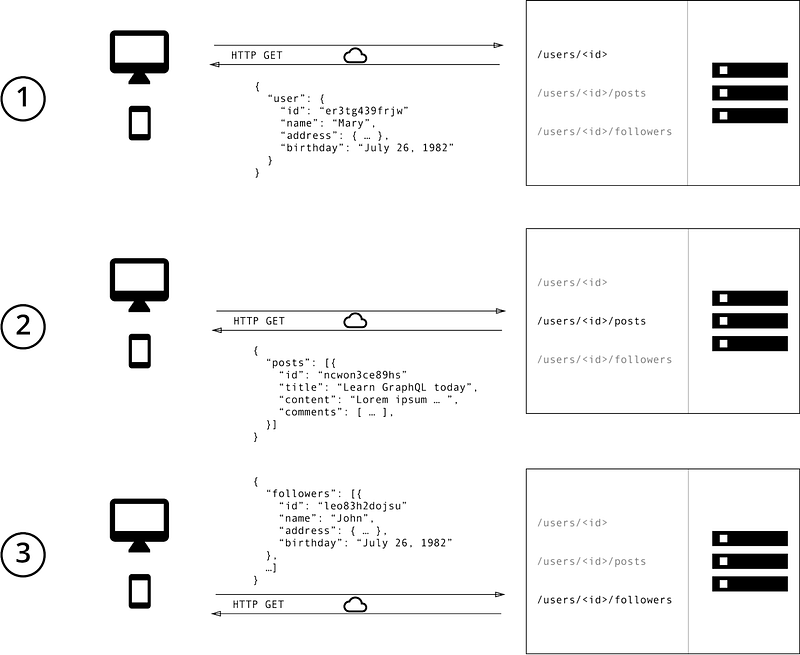
Image Source: https://www.howtographql.com/basics/1-graphql-is-the-better-rest/
In RESTful APIs, it’s the server that determines the structure and granularity of the data returned, and this can lead to more data than the client actually needs.
GraphQL shifts that responsibility to the client, and they can specify exactly the data they need in a single query.
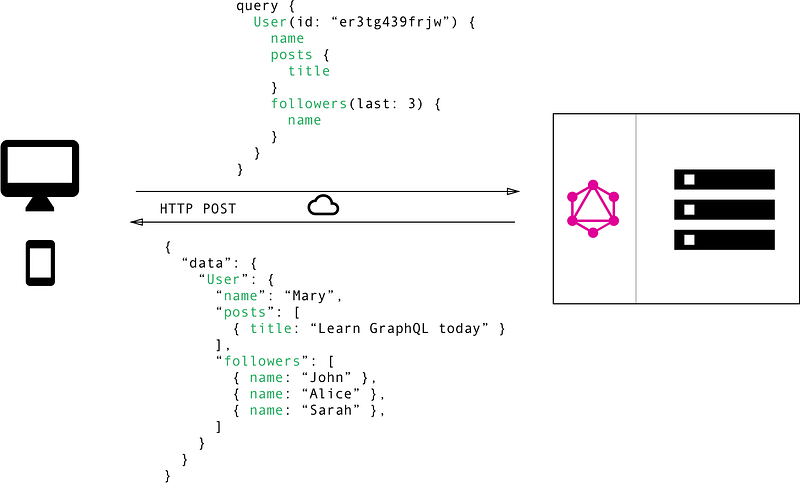
Image Source: https://www.howtographql.com/basics/1-graphql-is-the-better-rest/
Whether or not your downstream microservices/APIs are using GraphQL themselves doesn’t matter for the client/BFF interaction. You won’t need to rewrite anything to reap the benefits.
3. Documentation is going to be an ongoing chore. A BFF is purpose-built for a specific client, and so each BFF will need detailed accompanying API documentation (with payload/response specifications) to be created and kept up-to-date. If using REST, the endpoint names and HTTP verbs will only grow with the app and its complexity, making them difficult to document, and thus difficult to onboard new hires for.
GraphQL is declarative and self-documenting by nature. There’s a single endpoint, and all available data, relationships, and APIs can be explored and consumed by client teams (via the GraphiQL interface or just Introspection) without constantly going back and forth with backend teams.
…but GraphQL isn’t a silver bullet.
Adopting GraphQL shores up some BFF issues, no doubt, but GraphQL adoption isn’t something to be taken lightly. It’s not just another UI library to add to your tech stack, and much like anything in engineering, it has growing pains, trade-offs, and complexities associated with it.
1. GraphQL has a steep learning curve. Understanding its concepts -- schemas, types, queries, mutations, and subscriptions -- requires substantial time investment, and writing good resolver functions requires a good understanding of the underlying data models and how to retrieve and manipulate data from different sources (databases, APIs, or services). Server-side data coalescing is a neat idea, but this makes your GraphQL implementation only as good as your resolvers, and involves a ton of boilerplate that can make the implementation more verbose and error prone.
2. GraphQL has no built-in caching. The simplicity that GraphQL’s single endpoint format brings to the table can also become a bottleneck in certain circumstances -- REST APIs’ multiple endpoints allow them to use HTTP caching to avoid reloading resources, but with GraphQL, you’re only using one universal endpoint for everything, and will have to rely on external libraries (like Apollo) for caching.
3. GraphQL clients can be pretty heavy in terms of bundle size that you have to ship. This might not matter in some use-cases (if you’re only ever building an internal app, for example) but it can and does impact the load time and performance of your application, especially in scenarios where low bandwidth or slow network connections are a concern.
4. Performance can be a concern, if you’re not careful. The nature of GraphQL makes it non-trivial to harden your system against drive-by downloads of your entire database. It’s far more difficult to enforce rate limits in GraphQL than it is in REST, and a single query that is too complex, too nested, fetching too much data, could bring your entire backend to a crawl. Even accidentally! To mitigate this, you’ll need an algorithm to calculate a query’s cost before fetching any data at all -- and that’s additional dev work. (For reference, this is how GitHub’s GraphQL API does it)
5. GraphQL doesn’t have a built-in way to ensure security. REST’s vast popularity and authentication methods make it a better option for security reasons than GraphQL. While REST has built-in HTTP authentication methods, with GraphQL the user must figure out their own security methods in the business layer, whether authentication or authorization. Again, libraries can help, but that’s just adding more complexity to your builds.
Introducing WunderGraph.
WunderGraph is a free and open-source (Apache 2.0 license) framework for building Backends-for-Frontends.
GitHub - wundergraph/wundergraph: WunderGraph is a Backend for Frontend Framework to optimize…
Using WunderGraph, you define a number of heterogeneous data dependencies -- internal microservices, databases, as well as third-party APIs -- as config-as-code, and it will introspect each, aggregating and abstracting them into a namespaced virtual graph.
Here’s what a system you might build with WunderGraph would look like.
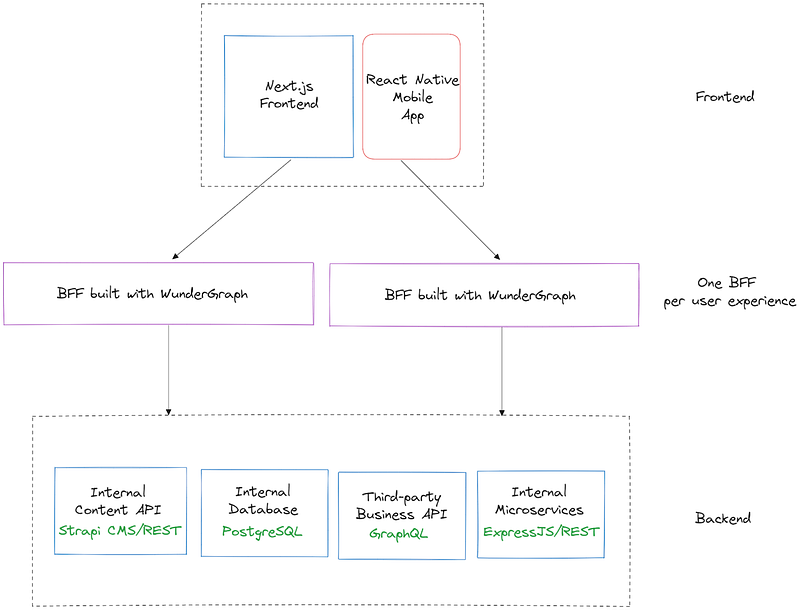
Let’s dive right in. First of all, you’ll have to name your APIs and services as data dependencies, much like you would add project dependencies to a package.json file.
./.wundergraph/wundergraph.config.ts
// Data dependency #1 - Internal database
const db = introspect.postgresql({
apiNamespace: "db",
databaseURL: "postgresql://myusername:mypassword@localhost:5432/postgres",
});
// Data dependency #2 - Third party API
const countries = introspect.graphql({
apiNamespace: "countries",
url: "https://countries.trevorblades.com/",
});
// Add both to dependency array
configureWunderGraphApplication({
apis: [db, countries],
});
You can then write GraphQL operations (queries, mutations, subscriptions) for getting the data you want from that consolidated virtual graph.
./.wundergraph/operations/CountryByID.graphql
query CountryByID($ID: ID!) {
country: countries_country(code: $ID) {
name
capital
}
}
./.wundergraph/operations/Users.graphql
query Users($limit: Int!) {
users: db_findManyusers(take: $limit) {
username
email
}
}
…and WunderGraph will automatically generate endpoints that you can cURL to execute these queries and return the data you want, over JSON-RPC.
> $ curl http://localhost:9991/operations/CountryByID?ID=NZ
> {"data":{"country":{"name":"New Zealand","capital":"Wellington"}}}
> $ curl http://localhost:9991/operations/Users?limit=5
>{"data":{"users":[{"username":"user1","email":"user1@example.com"},{"username":"user2","email":"user2@example.com"},{"username":"user3","email":"user3@example.com"},{"username":"user4","email":"user4@example.com"},{"username":"user5","email":"user5@example.com"}]}}
If you’re using data fetching libraries like SWR or Tanstack Query, or a React-based framework (NextJS, Remix, etc.) you get even more out of WunderGraph, as it auto generates a lean, performant, custom TypeScript client for you every time you define an operation, complete with fully type-safe hooks for querying and mutating data that you can use on the frontend, wherever you need it.
./pages/index.tsx
// Import data fetching hook from WunderGraph-generated client
import { useQuery } from "../components/generated/nextjs";
const Home: NextPage = () => {
// Data dependency #1 - Internal Database
const { data: usersData } = useQuery({
operationName: "Users",
input: {
limit: 5,
},
});
// Data dependency #2 - Third-party API
const { data: countryData } = useQuery({
operationName: "CountryByID",
input: {
ID: "NZ",
},
});
//...
};
Now, you can use usersData and countryData however you want. Render it out into cards, lists, pass it on to props, go wild.
But how does WunderGraph address GraphQL’s issues?
Easily - WunderGraph takes GraphQL completely out of the runtime.
Yes, you do write GraphQL operations to collect and aggregate the data you want from multiple data sources… but that’s it. You won’t have to write resolvers, or worry about making them efficient at data fetching. Your involvement with GraphQL goes only as far as writing queries, and only during development. No public GraphQL endpoint is ever exposed, nor is any heavy GraphQL client shipped on the client.
Don’t worry if this doesn’t click for you immediately. I promise it’ll make sense soon. Let’s look at this process in detail.
GraphQL only during local development?
Whenever you write a GraphQL query, mutation, or subscription and hit save, the Query is NOT saved as is. Instead, it is hashed and then saved on the server, only able to be accessed by the client by calling for the hashed name (together with input variables, if needed, of course).
This is what is called a Persisted Query. Your WunderGraph BFF server has a list of known hashes -- as many Persisted Queries as you define -- and will only respond to client requests for valid hashes, serving them as JSON over RPC, with a unique endpoint for each and every operation. (And WunderGraph generates typesafe hooks for React frameworks and data fetching libraries that do the same thing)
What does this mean? Two things.
- You address the security concerns associated with having your GraphQL API reverse engineered from browser network requests -- because there is no GraphQL API.
- If each operation has a unique endpoint, you can finally implement traditional REST-style caching! But that’s not all. The WunderGraph BFF server generates an Entity Tag (ETag) for each response -- this is an unique identifier for the content of said response -- and if the client makes a subsequent request to the same endpoint, and its ETag matches the current ETag on the server, it means the content hasn’t changed. Then the server can just respond with a HTTP 304 “Not Modified”, meaning the client’s cached version is still valid. This makes clientside stale-while-revalidate strategies blazingly fast.
You can write all the arbitrary queries you want using GraphQL during development time, but they’re hashed and persisted at compile time, and only show up at runtime as JSON RPC. In one fell swoop, you have solved the most common issues with GraphQL, creating a best-of-both-worlds scenario. All the wins of GraphQL, with none of the drawbacks.
But what about the performance concerns of too-complex queries?
WunderGraph uses the Prisma ORM internally, crafting optimized queries under the hood for each Operation you write, no matter your data source. You won’t have to worry about hand-rolling your own SQL or GraphQL queries and sanitizing them to make sure a single naïve query doesn’t kill your downstream services, or lead to DOS attacks.
Where To Go From Here?
You’ve seen how WunderGraph makes building BFFs so much easier, with fantastic devex to boot. Using Prisma under the hood, it creates persisted queries and serves them over JSON-RPC, reining GraphQL back to only being used in local development.
But you can do far, far more than that with WunderGraph -- it’s a true BFF framework:
- It supports fully typesafe development from front to back. Every Operation you write will generate a typesafe client/hook to access it from the frontend…and you can even generate typesafe Mocks this way! With WunderGraph, you have shared types between the backend and the frontend -- giving you full IDE autocomplete and inference both while writing GraphQL queries, and when developing the client.
- It can turn any query you write into a Live Query without even needing WebSockets -- making WunderGraph ideal for building BFFs which get deployed together with the frontend to serverless platforms, which can’t use WebSockets.
- It can also integrate S3-compatible storage for file uploads, OIDC/non-OIDC compatible auth providers, and more.
- If you don’t want to write GraphQL at all, you can write custom TypeScript functions -- async resolvers, essentially -- to define Operations during development. You can perform JSON Schema validation within them using Zod, and aggregate, process, and massage the data any way you want, and then return it to the client. TypeScript Operations are are accessed exactly like GraphQL Operations are (JSON RPC endpoints, or clientside hooks), and run entirely on the server and are never exposed clientside. Plus, you can even import and use existing GraphQL operations within them.
- You can bake cross-cutting concerns that are ideally present on the BFF layer -- most importantly, auth -- into WunderGraph’s BFF layer via Clerk/Auth.js/your own auth solution, and every Operation can be authentication aware.
With powerful introspection that turns API, database, and microservices into dependencies, much like a package manager like NPM would, WunderGraph makes BFF development accessible and joyful, without ever compromising on end-to-end typesafety. To know more, check out their docs here, and their Discord community here.
Comments
Loading comments…