For your next project, you might choose the same database you are used to working with, and this might be totally fine. Before you do go that route, you might consider a few things:
- Do you consider this project to scale?
- Is performance something important in this project?
- Is this project only a proof of concept?
The two types of database
You need to know that there are two types of databases: SQL databases (relational) and NoSQL databases.
Relational databases (SQL)
A relational database is a database where the information is organized in tables (two-dimensional arrays). Each table relates to each other and each of their rows represents a record identified by a primary key.
Relational databases support ACID transactions (atomicity, consistency, isolation, and durability).
- Atomicity: the database's operations either all occur, or nothing occurs.
- Consistency: the data written to the database must be valid according to all defined rules.
- Isolation: determines how transaction integrity is visible to other users and systems.
- Durability: guarantees that transactions that have been committed will survive permanently.
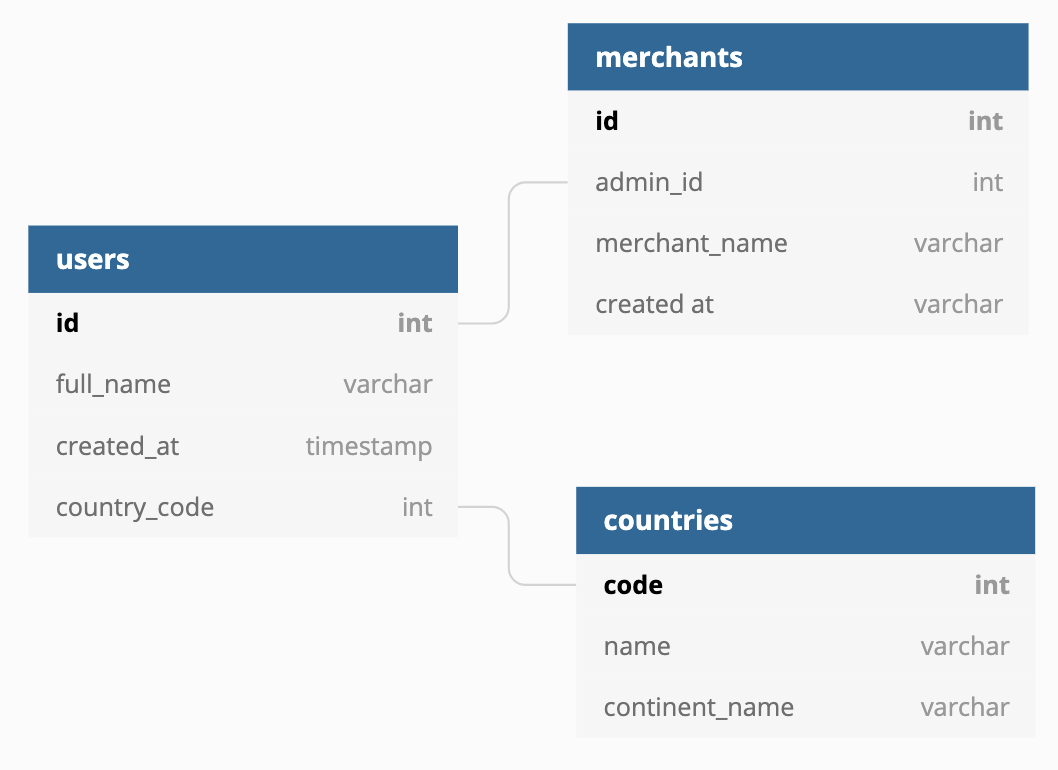
Example of a relational database
In the diagram above, the database merchants and countries relate to the users' database. You will find the country_code of users as code inside the countries database. As well, the users' id inside the merchants' database as id.
The relational databases are following a fixed schema for each record, and they need to stick to it.
One more important point about relational databases is that they do support SQL-like language. The primary keys allow you to perform joins between multiple tables to access all required data.
Popular relational databases: MySQL, PostgreSQL.
NoSQL databases
In contrary to SQL databases, NoSQL databases don't expect a structured fixed schema for their records.
Different types of NoSQL database
1. Document-oriented databases
That kind of database is storing documents that are JSON objects. Each document can have a different schema and contains different fields. This is really handy since it offers very good flexibility for the developers.

Example of a document database
Good use-cases for the document-oriented database are data analysis, mobile games, content management, and IoT
The most popular document-oriented databases: MongoDB, CouchDB.
2. Columnar databases
Columnar databases also called wide-columnar databases, store records in columns rather than by rows, unlike SQL databases. This makes it very efficient for column-based queries.
A good use for a columnar database is data science where each column represents a feature. Moreover, you can use a columnar database for your logs since you will most probably use a few columns for your queries.
The most popular columnar databases: Cassandra, HBase.
3. Key-value databases
A key-value database is probably the easiest database to explain. You do have a key that is associated with a value.
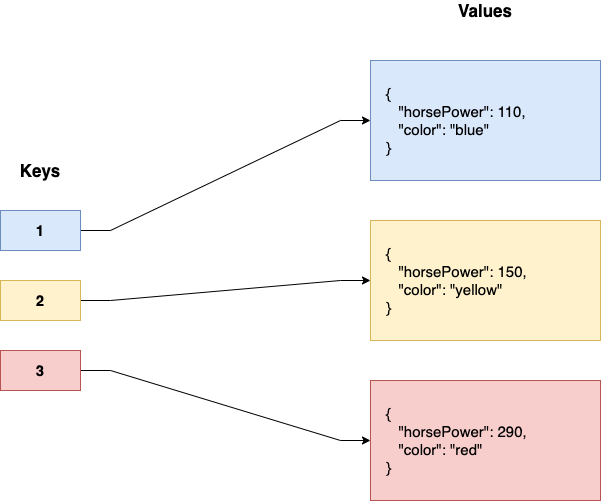
Example of a key-value database
Because they are storing the data in the RAM instead of the disk, it allows key-value databases having fast access. Moreover, the use of unique keys makes it even quicker from its conception itself.
As we can see key-value databases are very fast however, you need to be sure that their keys are unique. Since they run on memory instead of disk, they are also more expensive to run. Unfortunately, it makes them limited in space since the memory space is smaller than the disk space.
If you need fast access to data, and no complex querying, key-value databases are a good option. Good examples of use could be: caching or pub/sub.
The most popular key-value databases: Redis, Memcached.
4. Graph databases
Graph databases are about relationships between entities. You can make queries by relationships which is difficult with the other kind of databases.

Graph database representation
That kind of database can be used when your data looks like a graph like in social networks. Use-cases could be a recommendation engine or a knowledge graph.
The most popular key-value databases: Neo4j, Giraph, RedisGraph.
5. Search engine databases
Search engine databases work similarly to document databases, the main difference is that the database will search all the text in the documents and create an index of the searchable terms.
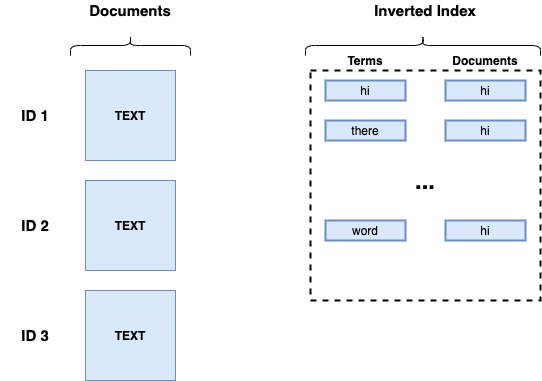
Example of a search engine database
When a user performs a search, we only have to scan the index to find the proper documents. This implementation makes the search engine database very fast even on large datasets.
They also provide different algorithms to correct typos, filter results, and so on.
It makes search engine databases very useful for search engines and autocompletes (typeahead).
The most popular search engine databases: Elasticsearch, Solr, Algolia.
Should I use a relational or a document database?
We could definitely compare the relational databases with all the kind of NoSQL databases. However, in most cases, you are actually wondering if you should use a relational or a document database.
To answer this question, we need to understand the advantages and disadvantages of each of these databases:
Relational database advantages
- It supports atomic transactions (all occurs, or nothing occurs).
- It supports SQL language.
- There are relations between records which makes it quick for updating the data.
Relational database disadvantages
- Querying can be slow. The query execution time depends on the size of your database, which means that the bigger is your database longer will be the query time.
- To scale a relational database, you process with vertical scaling, which means that you have to scale up your machine.
- It doesn't support OOP (Object-oriented programming), which means that you cannot use arrays contrary to document databases.
Document database advantages
- Your documents can have different structures because the data is unstructured or semi-structured.
- Querying is very fast, and contrary to relational databases, it doesn't depend on the size of the database.
- It supports OOP (Object-oriented programming) you can use arrays and objects using the JSON format.
- Some document databases allow you to do schema validation on your collections, even though NoSQL is unschematized by nature. As a fact, MongoDB is supporting that feature if you were wondering.
- Document databases scale horizontally, which means that you need to add more machines instead of upgrading your unique machine.
Document database disadvantages
- Atomic transactions are not supported.
- Updating data is slow because the data can be divided between different machines.
- They don't support joins which means that your data needs to be denormalized (your data will need to be embedded into a single document).
Which database should I use?
A lot of people think that choosing a database is basically choosing between SQL and no SQL, this is incorrect. The most important factors are to consider the structure of your data, the size of your database, the speed you need to access your data, as well as the scaling of your database.
You definitely need to start by the need of your application before choosing blindly to a kind of database your project is going to use.
To summarize here are the most famous use cases:
- For graph data, use a graph database.
- For caching, use a key-value database.
- If you need to query per feature (or column) like you could need in data science, use a columnar database.
- If you need data consistency (ACID), use a relational database.
- If you need JOIN operations (inner, outer, left, right, and cross), use a relational database.
- For storing unstructured data go for a document database.
- For a big amount of data go to the document database over relational databases.
Depending on your project, maybe you will need more than one type of database for your application. In that case, you might need to choose one type of database for each specific set of data for your project.
Comments
Loading comments…