
You've probably heard the term "headless scraping" before. Using headless browsers like Puppeteer, Playwright, Selenium is an efficient strategy for scraping dynamic websites - ones that don't have the data you need on page load, but only loads it based on user action and behavior.
In fact, given how it's headless (meaning there is no GUI overhead, so you load pages faster, and use fewer system resources), you can have multiple instances, automated and running in parallel, scraping the data you want much faster!
The catch? Well, it's a big one. These headless browsers are also much easier to detect and block by sites protecting their data and their infrastructure. So a GUI browser (the 'headful' option) is the way to go, right? Well, then you give up any performance benefits. Also, a headful browser doesn't really do anything by itself to bypass blocking that isn't just based on User-Agent strings.
What's to be done, then? Is there a best-of-both-worlds option out there? You bet! Today I'm going to show you how easy it is to scrape a dynamic website, such as YouTube, using Bright Data's Scraping Browser - a headful, fully GUI browser that is fully compatible with Puppeteer/Playwright APIs, and comes with block bypassing technology out of the box.
So let's get going!
"Installing" Bright Data's Scraping Browser
The reason for the quotes is that you won't actually have to "install" anything.
In fact, to get started with this particular browser, you'll have to sign up on Bright Data's website (it's free - no credit card required). To sign up, go here and click on the 'Start Free Trial' button and enter your details (you can use your regular mail account too).
Once you're done with the signup process, go to your Dashboard and select the 'Proxies & Scraping Infrastructure' option:

There, select 'Scraping Browser' and activate it.
Since you're a new user, you'll be presented with the choice of loading $5 for free, which is what I'll be picking today:
Even though it's a free option, you'll be requested for billing information (here you'll have to add the CC or a PayPal account). But don't worry, you won't be charged at this point in time.
With that done, you are presented with a very minimalistic UI where you can see values like host, username, and passwords. You'll be using them to navigate with our browser.
Using the browser
All right, by now you're probably wondering: "Where is the browser?".
The answer is that the browser lives in Bright Data's servers, not on your computer. This means that to communicate with it, we'll have to find a way to send messages back and forth. Lucky for you, Puppeteer can do that!
Let's see how we can configure Puppeteer to talk to Bright Data's browser. But first, you'll have to install Puppeteer. You can do that with the following line:
npm install puppeteer-core
That's it, now you can write code like this:
const puppeteer = require("puppeteer-core");
const auth = "<your username>:<your password>";
async function run() {
let browser;
try {
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`,
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto("http://youtube.com");
await page.waitForSelector("#content");
let videos = await page.evaluate(() => {
let elements = document.querySelectorAll(".yt-simple-endpoint");
let data = [];
elements.forEach((elem) => {
data.push({
title: elem.innerText.trim(),
videoURL: elem.getAttribute("href"),
});
});
return data;
});
console.log(videos);
} catch (e) {
console.error("run failed", e);
} finally {
await browser?.close();
}
}
if (require.main == module) (async () => await run())();
A few things of note here:
- The
puppeteer.connect()method here indicates that our Puppeteer code is connecting to a remote browser through a proxy server - this is Bright Data's Scraping Browser, running on their servers. - The
browserWSEndpointproperty specifies the WebSocket URL where the remote browser is running. For the actual WebSocket URL, we'll be using the value of the "host" parameter, obtained from Bright Data's web UI after signing up. - To actually connect to that endpoint, we'll also need the proper credentials - and the
authvariable is created for it by concatenating the values of "username" and "password" you got from Bright Data.
The rest is your standard Puppeteer code:
- We open a new page
- Go to
youtube.com - Wait for it to load.
- Then using the
evaluatemethod, we serialize the code from the callback, send it over to the actual browser, and after the browser executes the code, we get the result back. Note that this code won't work if you don't use theevaluatemethod, because I'm using thedocumentglobal object that's not present on the backend.
The output looks like this:
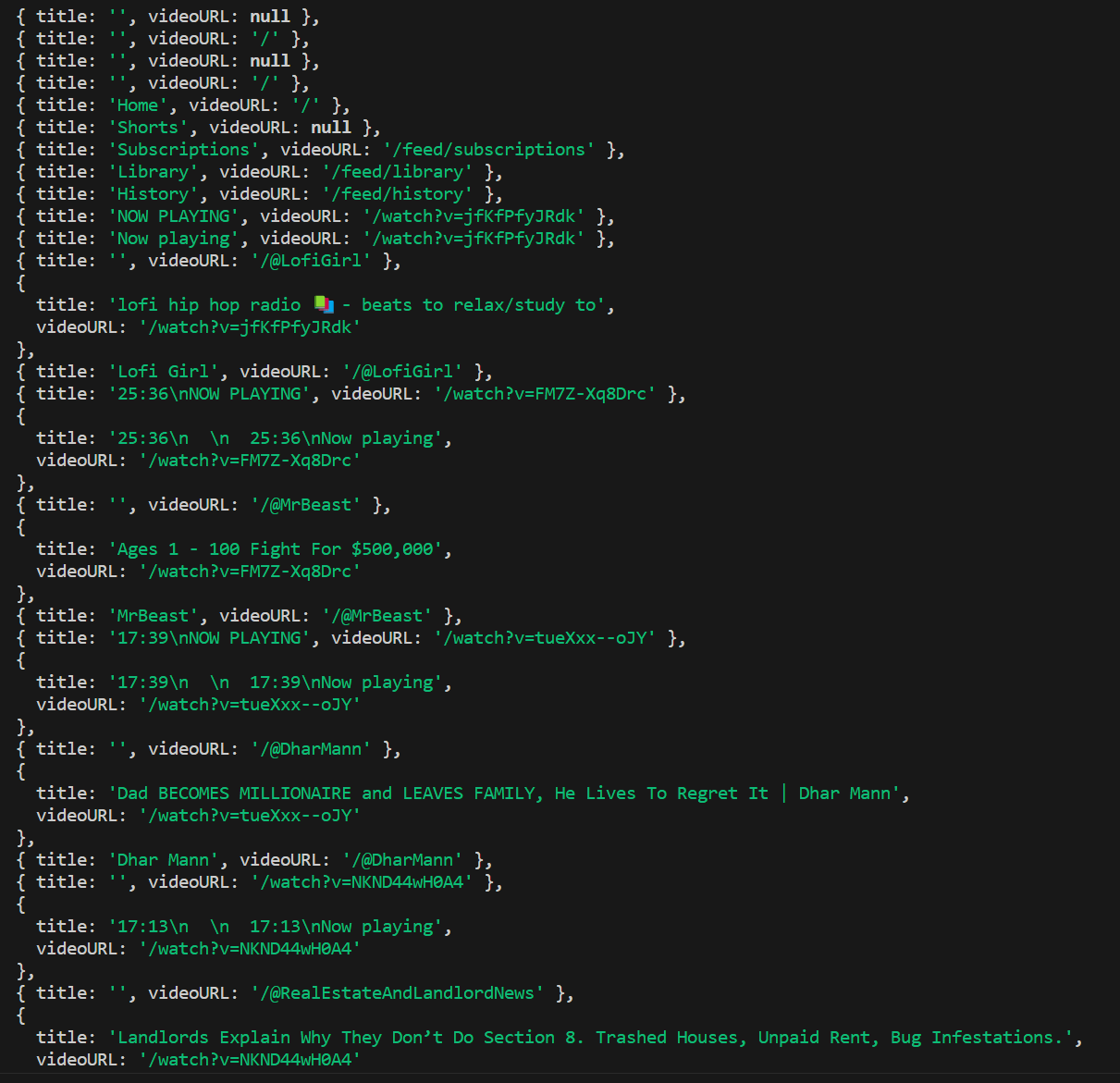
This is actually a portion of the output, but you get the point.
Understanding what just happened
If you've done web scraping in the past using headless browsers, you probably had to install some sort of extra extension, or perhaps you were able to give your browser a UI for testing purposes. You could see the browser opening a new page, navigating, and performing all the actions you had programmed.
Here, the situation is slightly different, because Bright Data has essentially created a 'Scraping Browser as a Service'. Using Puppeteer's API that lets you connect to a remote browser instance (The Puppeteer.connect method), you connect to Bright Data's Scraping Browser - a real browser with a full GUI - running on their servers, via a proxy.
You get all the benefits of a headful, GUI-enabled browser (harder to detect, more reliable, multi-instancing), with none of its drawbacks (slower performance, increased system resource usage, inability to scale), and even some additional benefits - auto-solving CAPTCHAs, rotating proxies, bypassing common website blocks. Best of all? You won't have to take on any of the burden of managing infrastructure, or using additional third-party solutions for these incidentals.
Bright Data's Scraping Browser is fully compatible with Puppeteer/Playwright's standard API, and it's able to receive messages and send data back while being executed somewhere else.
Learn more about it here: Scraping Browser - Automated Browser for Scraping
How we bypassed YouTube's blocks
This is an interesting section to write, because if I didn't, you'd assume that scraping YouTube is trivially simple. Just install Puppeteer, copy and paste the above code and you're done.
However, that's not the case.
YouTube is a huge platform, and because of that, it's ready to handle all types of users, including users trying to scrape. If you're not careful, they'll easily fingerprint your browser, and block your requests by rate-limiting you.
In fact, they have several different types of "checks" to make sure you're not an actual machine browsing their site.
Some of those techniques are:
- CAPTCHAs: CAPTCHAs are security measures implemented by websites to differentiate between human users and automated bots. They often involve presenting users with distorted images or puzzles and require them to solve the challenge to proceed. CAPTCHAs help prevent automated scraping by making it difficult for bots to bypass the verification process.
- Rate Limiting: Rate limiting is a technique employed by websites to restrict the number of requests a user or IP address can make within a certain timeframe. It helps prevent excessive traffic or abuse, ensuring fair usage and optimal performance for all users. Web scraping applications should be mindful of rate limits to avoid overwhelming servers and potentially being blocked or flagged as suspicious activity.
- Browser Fingerprinting: Browser fingerprinting is a method used to identify and track users based on the unique characteristics of their web browser and device. It involves collecting information such as browser version, installed plugins, screen resolution, and system fonts. Websites can use browser fingerprinting to detect scraping activities, as each scraper may have distinct fingerprinting attributes.
- Dynamic Page Rendering: Dynamic page rendering refers to the practice of generating web page content dynamically using JavaScript or other scripting languages. Instead of delivering complete HTML content directly, the initial response from the server may contain minimal data, which is then expanded and populated with additional content using client-side scripts. Dynamic rendering poses a challenge for web scraping as it requires tools capable of executing JavaScript and handling asynchronous requests to retrieve the complete data from the rendered page.
And if you go back to the example snippet I shared above, you won't find any code written to bypass them. That's because, thanks to Bright Data's browser, you don't have to worry about it.
Actions such as solving CAPTCHAs, bypassing fingerprinting, avoiding getting rate-limited by automatically cycling through proxies, changing the user-agent string and more are already taken care of by Bright Data. Your code can remain clean and focused only on the information you want to scrape.
Why would you go with this particular approach?
Scraping YouTube like this is relatively easy, and you can potentially do it with all solutions available.
However, once you start scratching your automation itch, you'll start wanting to do more. For example, going into Amazon, searching for a particular item, and evaluating its price over time.
But doing this may require many interactions with the target website over long periods of time. Not only that, but those sites might also have things like CAPTCHAs to make sure only "humans" use their products.
In the end, you might get blocked or flagged as "non-human" by your target websites.
Bypassing those scenarios manually can be a hassle, which is where Bright Data's Scraping Browser comes into play. It offers several benefits over a regular headless browser for web scraping. To sum up, here are some of the main advantages:
- Bypassing website blocks: Bright Data's Scraping Browser uses AI-driven technology to bypass the hardest website blocks, making it easier to access the data you need.
- Avoiding bot detection: The Scraping Browser makes use of Bright Data's advanced unlocker infrastructure to get around IP/device-based fingerprinting. This makes it less likely for you to get detected by advanced bot detection software, which can prevent you from accessing certain websites.
- Seamless integration: The Scraping Browser can be easily integrated with Puppeteer (like we've already seen) or Playwright, making it easier to automate web scraping tasks.
Overall, Bright Data's Scraping Browser is a powerful tool for web scraping that can help you extract valuable data from websites with very little effort.
Conclusion
And there you have it, we've successfully scraped YouTube without actually having to install a new browser on our computers.
This is truly a very interesting solution because you can set up several automations and only have to worry about the code, whereas before you'd also have to worry about getting the "right" browser, faking the user-agent properly, avoiding getting fingerprinted and solving CAPTCHAs through code.
All those problems are long gone now, as long as you're willing to pay a very small fee ($0.10/hour), you have the ideal scraping browser at your disposal.
👉Sign up today and start experiencing the benefits of Bright Data's Scraping Browser
Have you tried it yourself? Leave a comment sharing what your experience has been like!
Comments
Loading comments…