
Introduction
Web scraping has become an essential tool for businesses and developers in a variety of industries. It allows them to extract valuable data from websites and gain insights into consumer behavior, market trends, and other relevant information. However, web scraping can be a complex and time-consuming process, requiring knowledge of programming languages and tools to navigate websites and collect data.
Cheerio and jQuery are popular options for web scraping, providing DOM parsing and HTML/XML traversal to select desired data. However, they are limited in their ability to extract dynamic data or handle websites that are not server-side rendered.
That's usually where you bring out Puppeteer or Playwright - full, real browsers that can parse all JavaScript and XHR requests on a page, giving you the dynamic data you need. Sounds good, right? Let's just use Puppeteer for everything!
Well, not quite. These have some drawbacks that will hold you back:
- Much slower, and much more system-resource intensive. So much so, in fact, that if you're using Serverless tech like AWS Lambdas for running your scrapers (a common option for web scraping/data extraction because these usually guarantee a new IP every time), their provided runtimes won't even support a full Puppeteer instance because it's just too heavy.
- Many websites will prevent automated scrapers/crawlers from ever getting the data you want by using IP detection, device/browser fingerprinting to detect scrapers, CAPTCHA prompts, etc.
- So you'll not only have to design a resilient scraper using Puppeteer, but ALSO take care of proxy management and rotation, automated retries if your scraping attempts fail, header/canvas management, CAPTCHA solving, and much more.
- Developing and maintaining such complex browser-based scrapers is a difficult, resource-intensive task because of so many overlapping concerns to take care of.
And that's where Bright Data's Automated Scraping Browser shines. Much like Puppeteer and Playwright, the Scraping Browser is a real browser that can be operated programmatically, but it works slightly differently and with added perks. In this article, we'll explore the Scraping Browser, go over its features, and find out why you should consider using it for your web scraping needs.
What is Bright Data's Scraping Browser?
Bright Data's Scraping Browser is an all-in-one real browser that seamlessly integrates the convenience of a real, automated browser with powerful unlocker infrastructure and proxy/fingerprint management services.
How simple is this? Let's take a look.
- Before you write any scraping code, you use Puppeteer/Playwright to connect to Bright Data's Scraping Browser using your credentials, via Websockets.
- From that point on, all you have to be concerned with is building your scraper with the standard Puppeteer/Playwright libraries, and absolutely nothing more.
It's that simple. You won't have to manage a dozen third-party libraries for proxy and fingerprint management, IP rotation, automated retries, logging, or CAPTCHA solving in-house. The Scraping Browser will automatically handle all of this and more server-side, on Bright Data's end.
What's more, the browser's API is fully compatible with your existing Puppeteer/Playwright scripts, making integration a cinch, and migration a cakewalk.
Find out more:
Scraping Browser - Automated Browser for Scraping
Getting Started with Bright Data's Scraping Browser
Let's quickly go over the steps to get the Scraping Browser up and running.
Step 1: Prerequisites
Head on over to Bright Data's website, sign up for free, then sign in, and go to your Control Panel.
You'll need a Bright Data proxy to get started. If you have one already, just click Add Proxy and add the one you want from the list.
Otherwise, head on over to My Proxy, and click on Get Started in the Scraping Browser section.
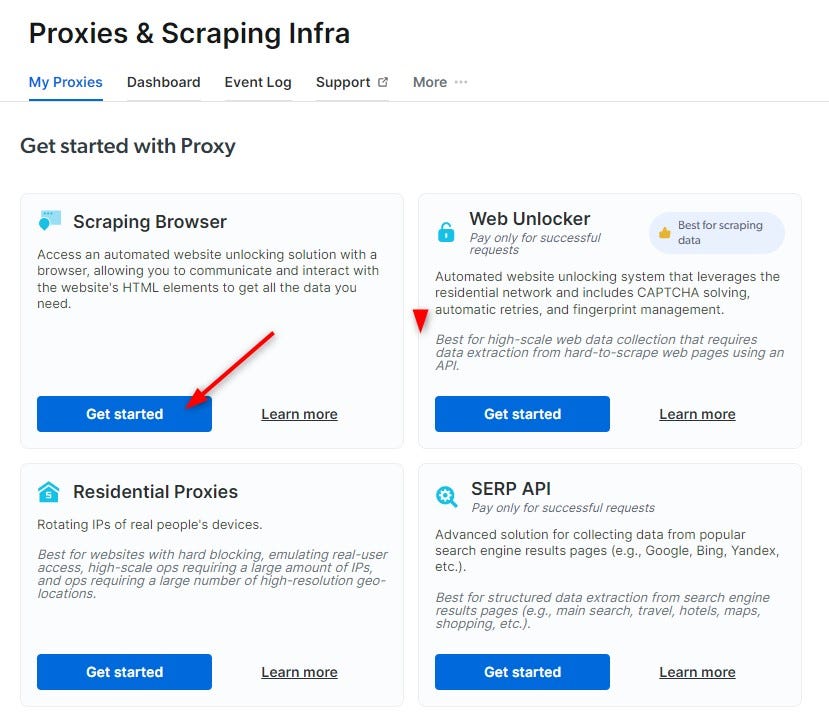
Create a new proxy, giving it a name. This zone is what you'll use for your Scraping Browser. Finally, click Add Proxy to create and save it. You'll be prompted for account verification by adding a payment method. Don't worry, though, you won't actually be charged anything.
Copy out the Username and Password. You'll need to use both in your code!
Step 2: Coding The Scraper
Let's see just how easy it is to integrate an existing Puppeteer scraper with this, to enjoy its proxy infrastructure and unlocker benefits. We'll use a simple script that scrapes Medium's programming tag for article titles, links, and summaries.
const puppeteer = require("puppeteer-core");
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth = "<YOUR_USERNAME>:<YOUR_PASSWORD>";
async function scrape() {
let browser;
try {
// Here's what makes this all possible
browser = await puppeteer.connect({
browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`,
});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto("https://medium.com/tag/programming");
// wait for 3 seconds (give time for page to trigger data load)
await page.waitForTimeout(3000);
// scroll down 1000px
await autoScroll(page);
// extract
const articlesData = await page.evaluate(() => {
const articles = document.querySelectorAll("article");
const articlesDataArray = [];
articles.forEach((article) => {
const hrefValue = article.querySelector("article a").href;
const h2InnerText = article.querySelector("article a div h2").innerText;
const pInnerText = article.querySelector("article a div p").innerText;
// here's the article data
const articleData = {
title: h2InnerText,
link: hrefValue,
summary: pInnerText,
};
articlesDataArray.push(articleData);
});
return articlesDataArray;
});
// print it out
console.log(JSON.stringify(articlesData, null, 2));
} catch (e) {
console.error("run failed", e);
} finally {
await browser?.close();
}
}
if (require.main == module) scrape();
// auto scroll by 200 px, 5 times.
async function autoScroll(page) {
let currentScroll = 0;
while (currentScroll < 1000) {
await page.evaluate(`window.scrollBy(0, 200);`);
currentScroll += 200;
await page.waitForTimeout(1000);
}
}
What makes this possible is Puppeteer's ability to connect to an existing, remote browser instance - in this case, Bright Data's Scraping Browser - via WebSockets with puppeteer.connect(). Once we've done that, the existing browser instance on Bright Data's end will handle all additional pain points associated with scalable, consistent web scraping operations.
The rest of the scraping script is standard Puppeteer fare.
- Visit a URL (https://medium.com/tag/programming)
- Wait for a while (3 seconds, in our case) to let the initial data load trigger
- Since this is an infinitely scrolling page, programmatically scroll down by whatever amount you want so that that data gets loaded in. Here we're scrolling a total of 1000 pixels.
- Use a combination of
document.querySelectorAllanddocument.querySelectorto get the elements needed, and their required properties (href, innerText, innerHTML, etc.) - Put it in whatever format you want (JSON array for us), and do with it what you need to do (We're just logging our JSON to the console, but in a real-world script you'd be persisting it somehow)
Conclusion
To sum it up, Bright Data's Scraping Browser is a robust tool that can revolutionize the way you approach web scraping. Its advanced features and capabilities provided out of the box, without any additional infrastructure or code on your part, make it a standout option compared to traditional methods of web scraping. By automating the additional concerns all scraping scripts need while also complying with data protection laws, Bright Data's Scraping Browser streamlines data extraction, allowing you to focus solely on your scraping logic.
Here are the benefits you get:
- Proxy management and rotation: Bright Data's scraping browser automates managing and rotating proxies. Just focus on your core scraping logic, and leave handling proxies to Bright Data.
- Captcha solving: The scraping browser incorporates Bright Data's powerful unlocker infrastructure, which reliably solves CAPTCHAs without the need for third-party libraries to be integrated and maintained on your part.
- Data protection compliance: Bright Data's scraping browser and its proxy infrastructure used are fully compliant with data protection laws, including the new EU data protection regulatory framework, GDPR, and the California Consumer Privacy Act of 2018 (CCPA).
- Simplified development: Developing and maintaining complex browser-based scrapers - not to mention any third-party libraries you're using to manage and rotate proxies, perform canvas/device fingerprint obfuscation, etc. - can be a difficult, resource-intensive task because of so many overlapping concerns to take care of. Bright Data's scraping browser takes care of it all for you, making it easier to just focus on what you do best - the actual Puppeteer/Playwright scraping code.
- Improved performance: Using Bright Data's Scraping Browser can help improve the performance of your scraping process and even bypass some Puppeteer/Playwright bugs entirely. By automating proxy management and captcha solving in a best practices way, and not leaving anything to chance, you can ensure the most correct, consistent, and fastest possible behavior of your scraping stack.
Whether you're a business or a developer looking for a reliable, efficient, and compliant web scraping solution, the Scraping Browser is the tool you need for data extraction with zero-to-low infra. With its compatibility with Puppeteer/Playwright and other developer-friendly features, migrating from your local scraping script to the Scraping Browser is an easy decision.
👉 Sign up today and start experiencing the power of Bright Data's Scraping Browser.
Comments
Loading comments…