
Did you ever get a task that asked you to move a document file into another format, but the target doesn't support you to copy the image? Are you feeling tired because you have to "Save as Picture…" all of the images from the DOCX to move it into another format? That was my problem; after digging the internet, I found an effortless way to skip this tedious task. This program will be written using Python because this is an easy programming language. Okay, let's go to the flow.
The Flow
The Project Flow:
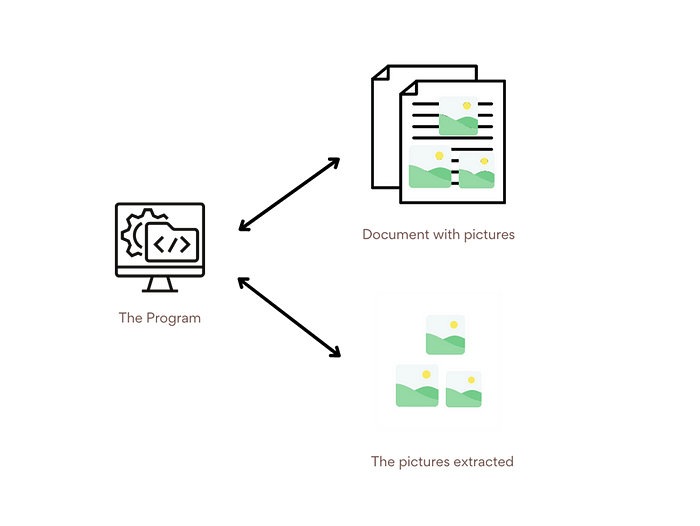
This section will exist from this article because I think the reader will understand the program better by knowing the whole system first. Okay, from the picture above, you can see that our program will read the document by the path and ask the location of the saved images, then it will read the document file and find all pictures inside it. Tadaaa, really simple, isn't it?
The Preparation
Okay, before going to the code, let's see what we need. The library that we are going to use is docx2txt. The project doesn't have any description; you can access it here. But it says this library is A pure Python-based utility to extract text and images from Docx files. You could install it using this command.
pip install docx2txt
The second preparation is you must have a file containing images. For example, I collect this post from @librarymindset on Twitter. The post gives 100 books that will change your life. The file will look like this.
The Document Preview:
The Code
This program will only take six lines of code; actually, you could make it one, but if you choose one, the program will not be genuine enough. Also, the actual code is only four lines, and the two lines are to add the readability. That makes everyone without a coding background couldn't use it easily.
import docx2txt
input_loc = input("Your docx location: ")
output_loc = input("Output location: ")
text = docx2txt.process(input_loc.split('"')[1], output_loc.split('"')[1])
Very simple right? You might notice why I need to use a split in the " value. I promise you will get the answer in the execution section.
The Execution
Finally, here is my record on how to execute it.
Nah, we split the because I copy the path from a file, the result from copying it will result in the " copied too, it will make the program error to make it work, remove it. For this program, I split it and took the path value. Yeah, you can create a function to remove it or else, but for this example, let's make it simple. The development is for you!
Conclusion
Well, in this program, I have already created a straightforward and short program that could extract images from a picture. I hope you got used to it. Thanks for reading.
Have a nice code!
Comments
Loading comments…