Photo by Edge2Edge Media on Unsplash
Chains and agents are fundamental building blocks of large language model development using LangChain. In the previous article, we discussed key components of LangChain with a focus on models, prompts, and output parsers. In this article, we will discuss chains and agents for large language model development using LangChain.
LangChain: Chains
Typically, a chain integrates an LLM with a prompt, forming modules that can execute a sequence of operations on our text or other datasets. These chains are designed to process multiple inputs simultaneously. The most common LLM providers are OpenAI, Cohere, Bloom, Huggingface, etc.
We will be discussing the following types of chains:
- LLM Chains
- Sequential Chains — SimpleSequesntialChain and SequentialChain
- Router Chains
LLM Chains
An LLMChain is a basic but the most commonly used type of chain. It consists of a PromptTemplate, an Open AI model (an LLM or a ChatModel), and an optional output parser. LLM chain takes multiple input variables and uses the PromptTemplate to format them into a prompt. It passes the prompt to the model. Finally, it uses the OutputParser (if provided) to parse the output of the LLM into a final format. One example of LLM chains can be seen below:
# import OpenAI Model, Prompt Template and LLm Chain
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# Initialize the language model
llm = ChatOpenAI(temperature=0.9)
# Initialize a prompt. This prompt takes in a variable called product asks the
# LLM to generate the best name to describe a company that makes that product.
prompt = ChatPromptTemplate.from_template(
"What is the best name to describe \
a company that makes {product}?"
)
Now we combine LLM and prompt into a chain called an LLM chain. So LLM chain is the combination of an LLM and a prompt.
# Combine LLM and prompt into LLm Chain
chain = LLMChain(llm=llm, prompt=prompt)
This chain runs through the prompt and the LLM in a sequential manner. Now, we can run through a product named “queen-size-sheet-set” using chain.run.
# chain.run formats the prompt under the hood and passes the whole prompt to LLM.
product = "Queen Size Sheet Set"
chain.run(product)
Based on this we get the name of a hypothetical company called “Royal Rest Linens”.
SequentialChain
A sequential chain combines multiple chains where the output of one chain is the input of the next chain. It runs a sequence of chains one after another. There are 2 types of sequential chains:
- SimpleSequentialChain — single input/output
- SequentialChain — multiple inputs/outputs
SimpleSequentialChain
This is the simplest form of a sequential chain, where each step has a singular input/output, and the output of one step is the input to the next. This works well when we have subchains that expect only one input and return only one output.
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# This is an LLMChain to write a synopsis given a title of a play.
llm = OpenAI(temperature=.7)
template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.
Title: {title}
Playwright: This is a synopsis for the above play:"""
prompt_template = PromptTemplate(input_variables=["title"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)
# This is an LLMChain to write a review of a play given a synopsis.
llm = OpenAI(temperature=.7)
template = """You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.
Play Synopsis:
{synopsis}
Review from a New York Times play critic of the above play:"""
prompt_template = PromptTemplate(input_variables=["synopsis"], template=template)
review_chain = LLMChain(llm=llm, prompt=prompt_template)
# This is the overall chain where we run these two chains in sequence.
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[synopsis_chain, review_chain], verbose=True)
review = overall_chain.run("Tragedy at sunset on the beach");
The chain runs through the following steps and the output can be seen as follows:
> Entering new SimpleSequentialChain chain...
Set in a small beach town, the play follows the journey of two best friends, Sam and Jack. After a summer of fun and laughs, Sam and Jack''s friendship is tested when they find themselves in a dark situation. At sunset, they stumble upon a group of thugs who are intent on robbing them. Despite their pleas for mercy, the thugs do not relent. In the ensuing struggle, Sam is murdered and Jack is left with the grief of losing his closest friend. As the tragedy unfolds, the story dives into the complexities of friendship, justice, and revenge. The play ultimately serves as a reminder that tragedy can strike even in the most tranquil of settings.
"Set in a small beach town, the play ''Sam and Jack'' offers an intimate, yet powerful look into the complexities of friendship, justice, and revenge. Through its gripping narrative, the story follows the journey of two best friends, Sam and Jack, whose summer of fun and laughter is abruptly interrupted when they find themselves in a dark situation. After stumbling upon a group of thugs intent on robbing them, Sam is tragically murdered and Jack is left with the grief of losing his closest friend.
The play is an emotional rollercoaster that touches upon the raw emotions of guilt, regret, sadness, and anger. The cast and crew do an exceptional job of taking the audience through this emotional journey, and the play serves as a reminder that tragedy can strike even in the most tranquil of settings. ''Sam and Jack'' is a must-see for anyone looking for a poignant and thought-provoking story that will stay with you long after the curtains close."
> Finished chain.
SequentialChain
All sequential chains do not involve passing a single string as an input and getting a single string as an output. More complex chains involve multiple inputs and multiple final outputs. We will be discussing this in our next example.
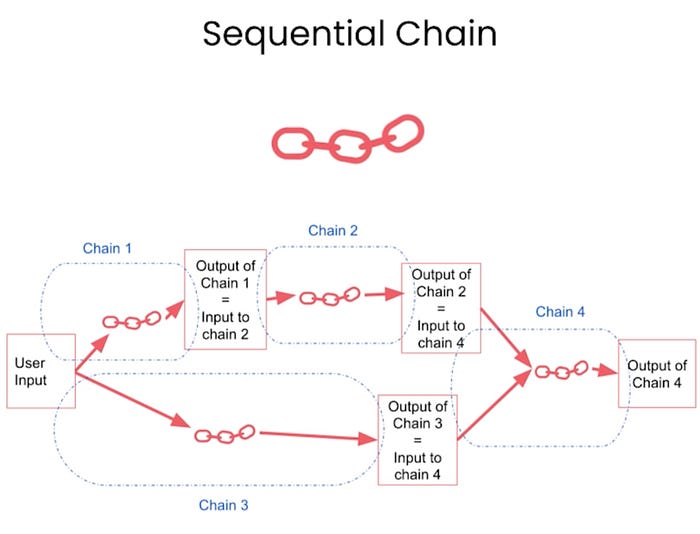
Here, the naming of input/output variables is very important in this chain. The code for Sequential Chain can be seen in the repo.
RouterChain
RouterChain is used for complicated tasks. For example, a pretty common but basic operation is to route an input to a chain depending on what exactly that input is. If we have multiple subchains, each of which is specialized for a particular type of input, we could have a router chain that decides which subchain to pass the input to. For example, we can route between multiple subchains depending on each specialized for a particular type of input.
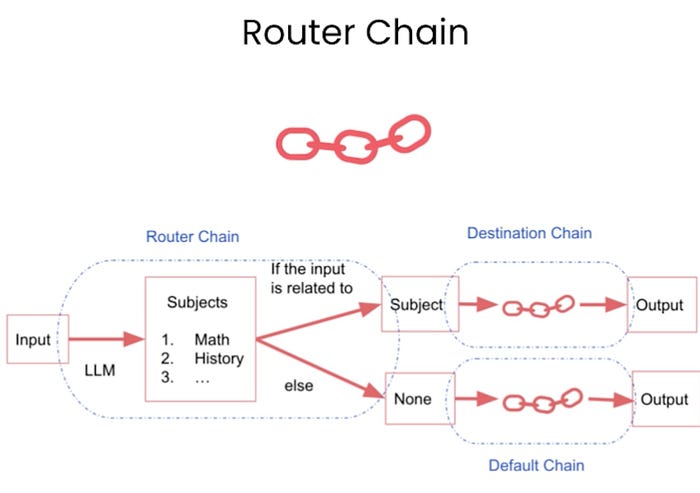
For example, we can route between different types of chains based on subjects like Maths, Physics, etc. So, we can have different prompts based on the type of subject. So, we can have one prompt to answer physics questions, a second prompt to answer math questions, a third prompt to answer history questions, and a fourth prompt to answer computer science questions.
We can define prompt templates for these subjects. We can provide more information about these prompt templates as well, for example, we can give each template a name and a description. Now, we can pass this information to the router chain and the router chain can decide when to use which subchain.
physics_template = """You are a very smart physics professor. \
You are great at answering questions about physics in a concise\
and easy to understand manner. \
When you don''t know the answer to a question you admit\
that you don''t know.
Here is a question:
{input}"""
math_template = """You are a very good mathematician. \
You are great at answering math questions. \
You are so good because you are able to break down \
hard problems into their component parts,
answer the component parts, and then put them together\
to answer the broader question.
Here is a question:
{input}"""
history_template = """You are a very good historian. \
You have an excellent knowledge of and understanding of people,\
events and contexts from a range of historical periods. \
You have the ability to think, reflect, debate, discuss and \
evaluate the past. You have a respect for historical evidence\
and the ability to make use of it to support your explanations \
and judgements.
Here is a question:
{input}"""
computerscience_template = """ You are a successful computer scientist.\
You have a passion for creativity, collaboration,\
forward-thinking, confidence, strong problem-solving capabilities,\
understanding of theories and algorithms, and excellent communication \
skills. You are great at answering coding questions. \
You are so good because you know how to solve a problem by \
describing the solution in imperative steps \
that a machine can easily interpret and you know how to \
choose a solution that has a good balance between \
time complexity and space complexity.
Here is a question:
{input}"""
prompt_infos = [
{
name: "physics",
description: "Good for answering questions about physics",
prompt_template: physics_template,
},
{
name: "math",
description: "Good for answering math questions",
prompt_template: math_template,
},
{
name: "History",
description: "Good for answering history questions",
prompt_template: history_template,
},
{
name: "computer science",
description: "Good for answering computer science questions",
prompt_template: computerscience_template,
},
];
Now, we need a multi-prompt chain, which is a specific type of chain that is used when routing between multiple different prompt templates. We also need LLMRouterChain, which uses a language model to route between different subchains. We will use the description and the name as provided by us in prompt_infos. We also import a router output parser, which parses the LLM output into a dictionary that can be used downstream to determine which chain to use and what the input to that chain should be.
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain,RouterOutputParser
from langchain.prompts import PromptTemplate
# Define the language model that we will use.
llm = ChatOpenAI(temperature=0)
Now we need to create destination chains. Destination chains are chains that get called by RouterChain. Each destination chain itself is a language model chain, an LLM chain. We also define a default chain, which gets called when the router can’t decide which of the subchains to use.
# Create destination chains
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = ChatPromptTemplate.from_template(template=prompt_template)
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
destinations = [f"{p[''name'']}: {p[''description'']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
Now we define a template that is used by the LLM to route between different chains. This has instructions on the task to be done, as well as the specific formatting that the output should be in.
default_prompt = ChatPromptTemplate.from_template("{input}");
default_chain = LLMChain((llm = llm), (prompt = default_prompt));
MULTI_PROMPT_ROUTER_TEMPLATE = """Given a raw text input to a \
language model select the model prompt best suited for the input. \
You will be given the names of the available prompts and a \
description of what the prompt is best suited for. \
You may also revise the original input if you think that revising\
it will ultimately lead to a better response from the language model.
<< FORMATTING >>
Return a markdown code snippet with a JSON object formatted to look like:
```pythonon
{{{{
"destination": string \ name of the prompt to use or "DEFAULT"
"next_inputs": string \ a potentially modified version of the original input
}}}}
```
REMEMBER: "destination" MUST be one of the candidate prompt \
names specified below OR it can be "DEFAULT" if the input is not\
well suited for any of the candidate prompts.
REMEMBER: "next_inputs" can just be the original input \
if you don''t think any modifications are needed.
<< CANDIDATE PROMPTS >>
{destinations}
<< INPUT >>
{{input}}
<< OUTPUT (remember to include the ```pythonon)>>"""
Now, we create a full router template by formatting it with the destinations that we defined above. This template is flexible to different types of destinations. We can add different types of destinations like English/ Latin apart from Physics, Math, History or Computer Science defined above.
We also create the prompt template from this template and create the router chain by passing in the LLM and overall router prompt. We have used a router output parser as well which helps the router chain decide which subchains to route between. Finally, we create the overall chain, which has a router chain, destination chain and default chain.
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
(destinations = destinations_str)
);
router_prompt = PromptTemplate(
(template = router_template),
(input_variables = ["input"]),
(output_parser = RouterOutputParser())
);
router_chain = LLMRouterChain.from_llm(llm, router_prompt);
chain = MultiPromptChain(
(router_chain = router_chain),
(destination_chains = destination_chains),
(default_chain = default_chain),
(verbose = True)
);
# Ask some questions to RouterChain
chain.run("What is black body radiation?")
LangChain: Agents
The Large Language Model serves not only as a repository of knowledge stores, capturing information from the internet and addressing our queries, but it can also be thought of as a reasoning engine capable of processing chunks of text or other sources of information given by us and use background knowledge learned off the internet and the new information provided to it by us to answer questions or reason through content or decide even what to do next.
Agents are one of the most powerful parts but also are one of the latest parts of langchain. We will discuss how to create and how use agents and how to equip them with different types of tools, like search engines that come built into LangChain. We will also discuss how to create our own tools so that agents can interact with any data stores, any APIs or any functions that you might want them to.
We will be using the “llm-math” and “Wikipedia” to create agents. We will initialize some methods from langchain. For example, we will load a method to initialize the agent. We will load the ChatOpenAI wrapper. We also need “AgentType” which is used to specify the type of agent that want to use.
from langchain.agents.agent_toolkits import create_python_agent
from langchain.agents import load_tools, initialize_agent
from langchain.agents import AgentType
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.chat_models import ChatOpenAI
We will first initialize a language model. We will use this as the reasoning engine that we’re going to use to drive the agent.
# Initialize the language model
llm = ChatOpenAI(temperature=0)
Now, we’ll load 2 built-in langchain tools namely, llm-math tool and wikipedia tool. LLM-math tool uses a language model in conjunction with a calculator to solve math problems. Wikipedia tool allows to connect to Wikipedia allowing to run search queries against Wikipedia.
# Load built-in langchain tools
tools = load_tools(["llm-math","wikipedia"], llm=llm)
Finally, we need to initialize the agent, which we pass tools, language model, and agent type.
# Initialize the agent.
agent= initialize_agent(
tools,
llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose = True)
# CHAT_ZERO_SHOT_REACT_DESCRIPTION - This is optimized to work with chat models.
# and react. React is a prompting strategy that elicits better thoughts from
# a language model.
We have set “handle_parsing_errors=True”. This is important as output parsers are used to take the LLM output, which is a string, and parse it into a specific format to be used downstream. Thus, LLM output, which is a text needs to be parsed into the specific action and the specific action input that the language model should take.
Now we will ask agents a math question.
agent("What is the 25% of 300?")
The agent works like this:
> Entering new AgentExecutor chain...
Thought: I need to calculate 25% of 300, which involves multiplication and
division. I can use the calculator tool to find the answer to this question.
Action:
{
"action": "Calculator",
"action_input": "25% of 300"
}
Observation: Answer: 75.0
Thought: We have answer to the question.
Final Answer: 75.0
> Finished chain.
> {''input'': ''What is the 25% of 300?'', ''output'': ''75.0''}
Here, the agent first enters the agent executor chain. It first thinks about what it needs to do, so it has a “Thought”. Then, it has an “Action”, which is a JSON corresponding to 2 things: an action and an action_input. The action corresponds to the tool to be used. Action_input is the input to the tool. Then, we have “Observation”, which has “Answer=75.0", coming from the calculator tool. Next, we go to the language model and where we get “Final Answer: 75.0”.
We will go through another example, where we will ask a question through Wikipedia API.
question =
"Tom M. Mitchell is an American computer scientist \
and the Founders University Professor at Carnegie Mellon University (CMU)\
what book did he write?";
result = agent(question);
The whole process of answering the question can be seen as below:
> Entering new AgentExecutor chain...
Thought: I can use Wikipedia to find out what book Tom M. Mitchell wrote.
Action:
{
"action": "Wikipedia",
"action_input": "Tom M. Mitchell"
}
Observation: Page: Tom M. Mitchell
Summary: Tom Michael Mitchell (born August 9, 1951) is an American computer scientist and the Founders University Professor at Carnegie Mellon University (CMU). He is a founder and former Chair of the Machine Learning Department at CMU. Mitchell is known for his contributions to the advancement of machine learning, artificial intelligence, and cognitive neuroscience and is the author of the textbook Machine Learning. He is a member of the United States National Academy of Engineering since 2010. He is also a Fellow of the American Academy of Arts and Sciences, the American Association for the Advancement of Science and a Fellow and past President of the Association for the Advancement of Artificial Intelligence. In October 2018, Mitchell was appointed as the Interim Dean of the School of Computer Science at Carnegie Mellon.
Page: Tom Mitchell (Australian footballer)
Summary: Thomas Mitchell (born 31 May 1993) is a professional Australian rules footballer playing for the Collingwood Football Club in the Australian Football League (AFL). He previously played for the Adelaide Crows,Sydney Swans from 2012 to 2016, and the Hawthorn Football Club between 2017 and 2022. Mitchell won the Brownlow Medal as the league''s best and fairest player in 2018 and set the record for the most disposals in a VFL/AFL match, accruing 54 in a game against Collingwood during that season.
Thought: The book that Tom M. Mitchell wrote is "Machine Learning".
Thought: I have found the answer.
Final Answer: The book that Tom M. Mitchell wrote is "Machine Learning".
> Finished chain.
Here, we asked the agents about the book Tom M. Mitchell, an American computer scientist wrote. The agent recognizes that it should use the Wikipedia tool to look up the answer so it “Action” with the JSON mentioned above. Thus, it searches for “Tom M. Mitchell” in Wikipedia. Here, the agent goes through 2 observation-summary processes and finally decides upon the final answer and finally, it’s able to answer with “Tom M. Mitchell wrote the textbook, ‘Machine Learning’”.
Python Agent
The next example is similar to GitHub copilot or chatGPT code integrator enabled, where we use a language model to write code and execute it. So, we will create a Python agent with the same LLM as used in the above examples and we will be using PythonREPLTool. REPL can be thought of as similar to Jupiter Notebook.
agent = create_python_agent(llm, (tool = PythonREPLTool()), (verbose = True));
We will try to sort the following list of names by last name and first name and print the output using the above agent.
customer_list = [
["Harrison", "Chase"],
["Lang", "Chain"],
["Dolly", "Too"],
["Elle", "Elem"],
["Geoff", "Fusion"],
["Trance", "Former"],
["Jen", "Ayai"],
]
Now we will call the agent and get the answer to the above by printing the answer.
# langchain.debug = True
agent.run(f"""Sort these customers by last name and then first name \
and print the output: {customer_list}""")
The agent executor chain goes through the following process to get the answer for the above problem.
> Entering new AgentExecutor chain...
I can use the `sorted()` function to sort the list of customers.
I will need to provide a key function that specifies the sorting order
based on last name and then first name.
Action: Python_REPL
Action Input: sorted([[''Harrison'', ''Chase''], [''Lang'', ''Chain''], [''Dolly'', ''Too''], [''Elle'', ''Elem''], [''Geoff'', ''Fusion''], [''Trance'', ''Former''], [''Jen'', ''Ayai'']], key=lambda x: (x[1], x[0]))
Observation: [[''Jen'', ''Ayai''], [''Harrison'', ''Chase''], [''Lang'', ''Chain''], [''Elle'', ''Elem''], [''Geoff'', ''Fusion''], [''Trance'', ''Former''], [''Dolly'', ''Too'']]
Thought: The customers have been sorted by last name and then first name.
Final Answer: [[''Jen'', ''Ayai''], [''Harrison'', ''Chase''], [''Lang'', ''Chain''], [''Elle'', ''Elem''], [''Geoff'', ''Fusion''], [''Trance'', ''Former''], [''Dolly'', ''Too'']]
> Finished chain.
Here, it is using Python REPL as Action, and for action_input, it is writing the program to sort the customer_input. In Observation, we get the sorted list and the agent realizes that the sorting has been done and so it mentions this in “Thought”. If we want to see what is happening under the hood, we can set langchain.debug=True and this will print out all the different chains that go to get the result. We can check the different chains that this agent runs to get the answer in the repo. More specifically, the agent goes through the following:
- chain:AgentExecutor — Agent enters with the input
- chain:LLMChain — LLM chain gets started with input, empty agent_scratchpad and stop sequences.
- llm:ChatOpenAI — LLM(language model) starts and the agent makes a call to the language model with a formatted prompt with instructions about the tools(REPL tool in this case) that it has to use. When the LLM process ends, we can see the text key(thought), the action(Python REPL) and the action input.
- chain:AgentExecutor — Here llm chain is wrapped up.
- tool:Python REPL — Here exact input to Python REPL tool is provided and sorted sequence is the output of the tool.
Till now, we discussed about LangChain’s inbuilt tools but we can also connect langchain with our own sources of information, our own APIs or our own data. So here we’re going to go over how you can create a custom tool so that you can connect it to whatever you want. Now, we will make a tool that tells us the current date.
We will first import the tool decorator for this. Tool decorator can be applied to any function and the function gets converted into a tool that LangChain can use.
from langchain.agents import tool
from datetime import date
We also write a function called “time”, which takes in any text string. It returns today’s date by calling DateTime. We also write a detailed doc string in this function as the agent uses this docstring. This docstring is used by the agent to know when it should call this tool and how it should call this tool. In this case, we need the “The input should always be an empty string.”
@tool
def time(text: str) -> str:
"""Returns todays date, use this for any \
questions related to knowing todays date. \
The input should always be an empty string, \
and this function will always return todays \
date - any date mathematics should occur \
outside this function."""
return str(date.today())
In case, we have more stringent requirements on the input, for example, if we want the function to always take in a search query or a SQL statement, we need to mention it in the docstring.
We will now create another agent by adding a time tool to the list of existing tools.
# Initialize the agent
agent= initialize_agent(
tools + [time],
llm,
agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION,
handle_parsing_errors=True,
verbose = True)
Finally, we call the agent and ask it today’s date.
# Call the agent
try:
result = agent("whats the date today?")
except:
print("exception on external access")
We get the following sequence done by the agent to get the answer.
> Entering new AgentExecutor chain...
Question: What''s the date today?
Thought: I can use the `time` tool to get the current date.
Action:
{
"action": "time",
"action_input": ""
}
Observation: 2023-08-02
Thought:I now know the final answer.
Final Answer: The date today is 2023-08-02.
> Finished chain.
The agent recognizes that it needs to use the time tool and the agent takes the action input as an empty string, as told to it in the docstring. It returns with an observation. And then finally, the language model takes that observation and responds to the user, “Today’s date is 2023–05–21”.
In this article, we discussed chains and agents in LangChain for large language application development. Thanks for reading till the end.
Comments
Loading comments…