Classification is a supervised machine learning technique that focuses on predicting the correct label or class for a given input. There are multiple different classification models that accomplish this task, but each one works in its own way. Today, we’ll go through three of the most popular models: KNN (K Nearest Neighbor), Decision Trees, and SVMs (Support Vector Machines). Then, we’ll take a look at when each model should be applied and what kinds of data each one works best for, specifically in the medical field.
What is KNN?
KNN or K Nearest Neighbor works on the foundational idea that similar inputs will have similar outputs. When every data point is graphed, KNN looks at the K nearest data points to new data points. Say K = 3. The first closest data point to a new point P may belong to group red, the second to group blue, and the third to group red again. Taking the majority vote, KNN determines that the point P must belong to the red group. Below is a visualization of how the KNN algorithm works.
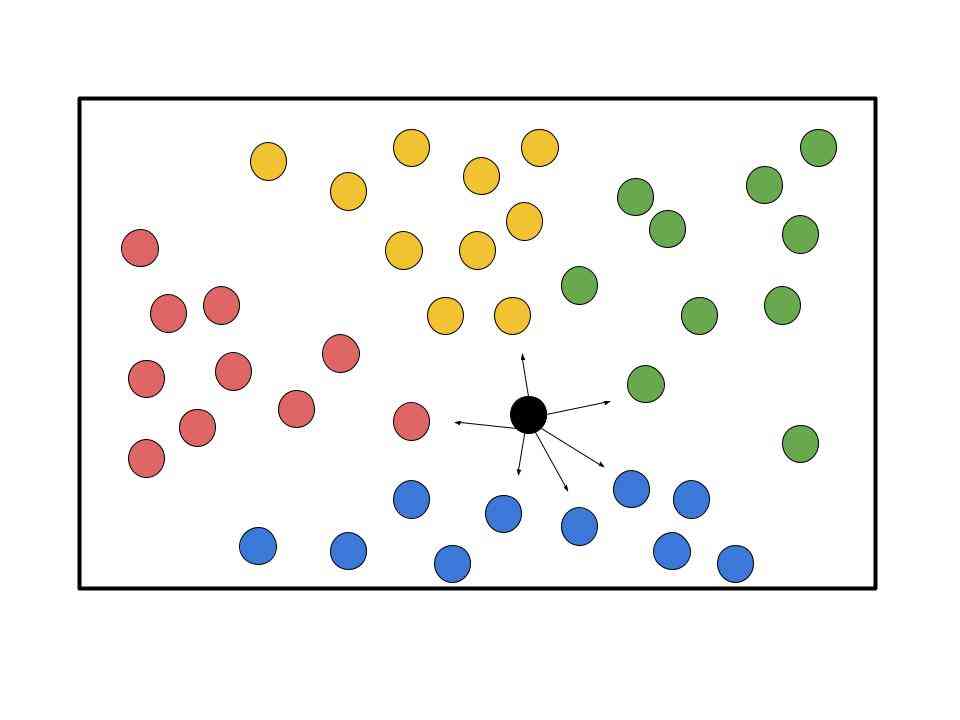 In the photo above there are four different classes (red, yellow, green, and blue). The black point represents a new data point that the classification model wants to label as one of the four groups. In this case, let's say K = 6. This means that the model will find the 6 nearest neighbors to the black point. In this case, 3 of those neighbors belong to the blue class and 1 belongs to the yellow, red, and green each. KNN uses a majority rules idea and will then classify the new data point as belonging to the blue class.
In the photo above there are four different classes (red, yellow, green, and blue). The black point represents a new data point that the classification model wants to label as one of the four groups. In this case, let's say K = 6. This means that the model will find the 6 nearest neighbors to the black point. In this case, 3 of those neighbors belong to the blue class and 1 belongs to the yellow, red, and green each. KNN uses a majority rules idea and will then classify the new data point as belonging to the blue class.
What are Decision Trees?
Decision trees are sort of similar to a yes or no guessing game. Imagine that you are trying to predict the price of a house based on the features (number of bedrooms/bathrooms, square footage, build year, etc.) of the house. The decision tree may start by asking “Does this house have more than 3 bedrooms?”. Depending on the yes or no answer, the model will adjust the prediction. The initial question that the decision tree asks is called the root node. The final prediction layer is called a leaf node and the remaining nodes are called internal nodes. A visual representation is shown below.

It’s important to note that with more questions with specificity, the predictions will only get better, but the main idea is that the prediction is determined by the yes or no response to the questions asked by the model.
What is an SVM?
An SVM or Support Vector Machine, is a binary classification model. This means that, say you have 40 different classes, the model will look at 2 options at a time, classifying whether or not a data point is more likely to option a or b, and sifting through the 40 options to determine the closest match. Let’s look at the process for determining whether a data point is more likely to belong to class a or class b…

Imagine that the red dots represent the data points belonging to class a and the green points belonging to class b. First, a line is fit between the data points. The kernel the SVM is using will determine the type of decision boundary. (Linear (line), Poly (polynomial function), RBF (similar to a circle) and sigmoid. Now imagine that your boundary is given a width, like a thick line, called the margin. The margin represents the length of the broadest street that can fit between the 2 classes. In the photo, this is represented by the two dashed lines. This margin and “street” determine which side of the boundary a new data point will be placed on and thus determines which class the model predicts a data point belongs to. If the data is more than 2 dimensions, the same concept still applies, but hyperplanes are fitted to the data to accommodate the dimensionality.
When Should I Use Each Model?
Now that we have talked about these models, you might be wondering when each one should be used. Let’s look into this, specifically when considering medical data. Given KNN’s nearest neighbor approach, it is particularly useful in cases where you want to classify a patient based on their similarity to other patients with a certain condition. KNN can also help in grouping patients with similar characteristics and their responses to certain treatments/procedures. SVMs are very helpful when working with high-dimensional data, such as in tumor classification and medical imaging. Given the SVM’s hyperplane approach, it is a great choice for these kinds of problems. There are many pros and cons to each classification model discussed, so it’s important to look closely into the data you are working with before determining which model to use. For example, if the interpretability of the results is very important, then SVMs may not be the best choice since it is difficult to visualize high-dimensional data and the hyperplanes associated with it. Generally, you should look into many models before making a choice and try out these models to determine the best fit for your data.
Comments
Loading comments…