Introduction
In the rapidly evolving realm of Natural Language Processing (NLP), the ability to accurately and efficiently represent sentences has become paramount. As we venture deeper into the age of information, the sheer volume of textual data demands sophisticated techniques to understand, categorize, and retrieve meaningful insights. Enter the world of sentence embeddings, where models like BERT have revolutionized the way we perceive language understanding.
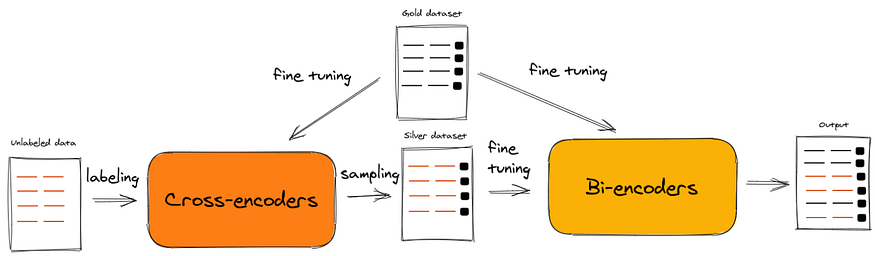
However, as with any technological advancement, the journey of sentence embeddings is filled with innovations, iterations, and choices. Among the myriad of models and techniques available, two have particularly stood out in recent times: Cross-Encoders and Bi-Encoders. Both offer unique advantages and present their own set of challenges, making the choice between them far from straightforward.
This article aims to demystify these two prominent approaches, delving deep into their mechanisms, comparing their strengths and weaknesses, and guiding you through their practical implications. Whether you’re an NLP enthusiast, a seasoned researcher, or someone simply curious about the latest in language models, this comprehensive guide promises to shed light on the intricate world of Cross-Encoders and Bi-Encoders.
1. Deep Dive into Cross-Encoders
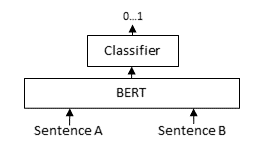
Imagine you’re trying to understand the relationship between two pieces of a puzzle. You’d look at both pieces together, right? That’s essentially how Cross-Encoders work in the world of language processing.
Definition and Working Mechanism:
Cross-Encoders take two pieces of text and examine them together, side by side. By doing this, they can understand how these texts relate to each other, capturing the finer details of their relationship.
Advantages:
- Higher Accuracies: The full self-attention mechanism allows Cross-Encoders to often outperform their counterparts in terms of accuracy, especially in tasks that require a deep understanding of context.
- Detailed Representations: By recalculating encodings for each pair, Cross-Encoders can generate detailed and context-rich sentence representations.
Challenges:
- Computational Intensity: They need to recompute the encoding for every input-label pair makes Cross-Encoders computationally demanding, especially with large datasets.
- Slower Test Times: Due to their intricate encoding process, Cross-Encoders can be prohibitively slow during testing phases, making them less suitable for real-time applications.
The Math Behind It:
When a Cross-Encoder processes two pieces of text, it essentially combines them into a single input. Mathematically, if we have two vectors AA(representing the first text) and B (representing the second text), the Cross-Encoder might concatenate them:
C=[A;B]
Here, C is the combined input. The model then processes C through its layers to produce an output that represents the relationship between A and B.
Understanding Bi-Encoders
While Cross-Encoders excel in accuracy, the world of NLP often requires a balance between precision and efficiency. This is where Bi-Encoders come into play.
Now, imagine you’re trying to understand two separate stories. Instead of reading them together, you read them one after the other. That’s the essence of Bi-Encoders.
Definition and Functioning:
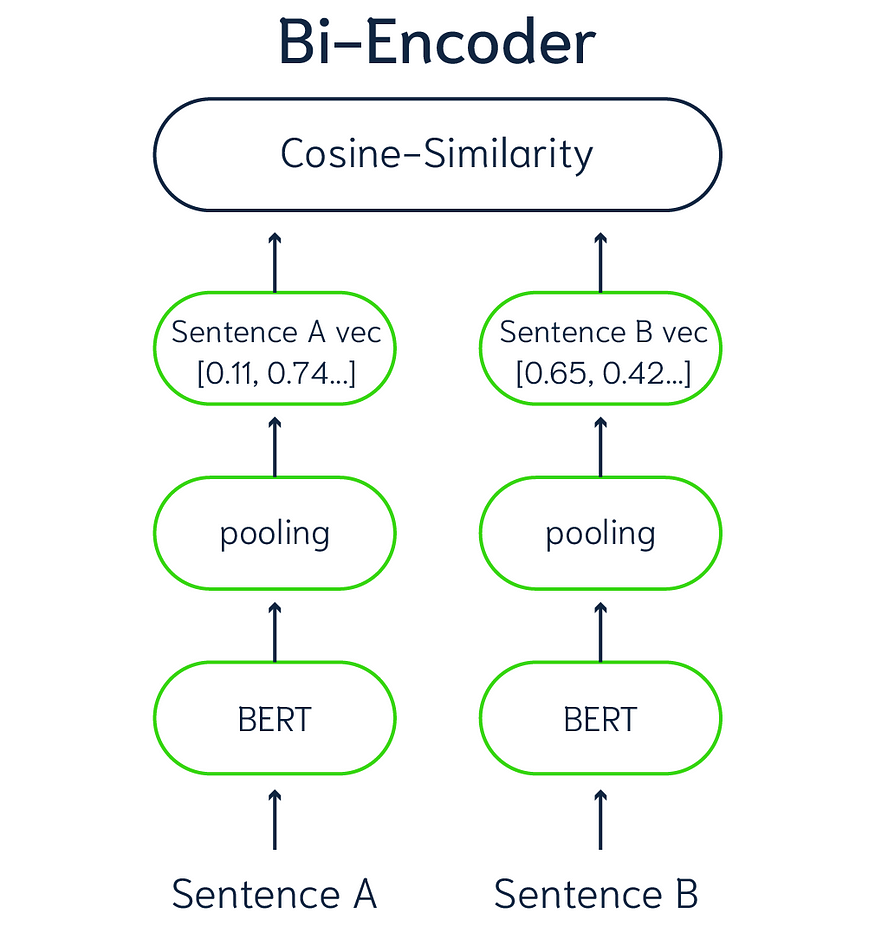
Bi-Encoders, in contrast to their cross counterparts, perform self-attention over the input and candidate label separately. Each entity is mapped to a dense vector space independently, and these representations are combined at the end for a final output.
Bi-Encoders read one piece of text, understand it, then move on to the next. After understanding both, they then decide how these texts might relate. It’s a step-by-step approach.
Advantages:
- Speed: One of the most significant benefits of Bi-Encoders is their efficiency. By encoding inputs and labels separately, they can drastically reduce prediction times, making them ideal for real-time applications and large-scale tasks.
- Scalability: Bi-Encoders can handle vast amounts of data with ease, thanks to their ability to index encoded candidates and compare these representations swiftly.
Challenges:
- Potential Accuracy Trade-off: While they are faster, Bi-Encoders might sometimes lag behind Cross-Encoders in terms of sheer accuracy, especially in tasks that demand intricate contextual understanding.
- Representation Limitations: Since inputs and labels are encoded separately, there might be instances where certain contextual nuances are missed.
The Math Behind It: For Bi-Encoders, the two pieces of text are processed separately. Let’s go back to our vectors A and B. Instead of combining them like in Cross-Encoders, a Bi-Encoder processes them independently:
A′=f(A)
B′=f(B)
Here, f is the function (or transformation) the Bi-Encoder applies to each text. Once A′ and B′ are obtained, they are compared to determine their relationship. This could be done using a dot product:
score=A′⋅B
The resulting score gives an idea of how closely related the two texts are.
Comparative Analysis: Cross-Encoders vs. Bi-Encoders
In the world of sentence embeddings, choosing between Cross-Encoders and Bi-Encoders can feel like picking between two flavors of ice cream. Both have their unique tastes and textures, but which one is right for you? Let’s break it down:
Cross-Encoders:
- Detailed Textual Analysis:
- Scenario: Imagine you’re building a system to analyze legal documents, where missing a subtle nuance could have significant implications.
- Why Cross-Encoders: Their ability to process texts together ensures they capture intricate relationships, making them ideal for tasks demanding high precision.
2. Sentiment Analysis:
- Scenario: You’re developing a tool to gauge customer sentiment based on their reviews.
- Why Cross-Encoders: They can understand the context better by examining the entire review, leading to more accurate sentiment predictions.
3. Question-Answering Systems:
- Scenario: Building a platform where users can ask detailed questions and expect precise answers, like a medical query platform.
- Why Cross-Encoders: They can compare the user’s question and potential answers together, ensuring the most contextually relevant response is chosen.
Bi-Encoders:
- Real-time Chatbots:
-
Scenario: You’re designing a chatbot for a website that needs to provide instant replies.
-
Why Bi-Encoders: Their speed in processing texts separately ensures swift responses, enhancing user experience.
2. Large-scale Information Retrieval:
-
Scenario: Developing a search engine for a vast database, like an online library.
-
Why Bi-Encoders: They can quickly scan through vast amounts of data, providing search results in a flash.
3. Duplicate Content Detection:
-
Scenario: You’re building a tool for a content platform to detect and flag duplicate submissions.
-
Why Bi-Encoders: Their efficiency allows them to compare new content with a large existing database swiftly, identifying duplicates with ease.
Reference
Comments
Loading comments…