
Introduction
The growth of e-commerce is increasing at a vast rate. According to Shopify, the global e-commerce market is expected to total $6.3 trillion, and by 2024, a total of 21.2% of retail sales will happen online.
In this era of growing e-commerce stores, gathering and analyzing competitor pricing data and customer sentiment data properly is crucial to staying ahead of your competitors.
However, gathering this data takes a lot of work. This is where web scraping comes in. Web scraping enables you to collect publicly available data from e-commerce websites. You can then use this data to perform analysis to gain valuable insights that could give you an edge over your competitors.
One of the market leaders in the e-commerce space is eBay. It’s a treasure trove of data that can help you analyze market trends, customer preferences, user sentiments, and more.
However, scraping data from a site as sophisticated as eBay presents its own set of challenges. These challenges range from dealing with complex site structures and dynamic content to navigating through anti-scraping measures like CAPTCHA verification, geo-location blocks, and IP rate-limiting. Bypassing all these using traditional web scraping methods might not be ideal in this era.

In this guide, you'll dive into these challenges and will be introduced to a robust solution: Bright Data’s Web Scraper IDE. This tool is designed to streamline the web scraping process, making it more efficient and accessible, even for those with limited technical expertise. It offers features like IP rotation, CAPTCHA solving, and more, so you don’t have to spend more time bypassing them.
But before jumping into how the tool can be utilized properly, let’s take a look at the challenges of scraping eBay in more detail first.
Challenges of Scraping eBay Data
Scraping data from eBay, one of the world’s largest e-commerce platforms is a task that’s easier said than done. The challenges are complex and can be confusing even for experienced data scientists. Let’s discuss some of the significant obstacles one might encounter while attempting to scrape eBay using conventional methods:
- Complex and Changing Web Pages: eBay's website is complex and constantly changing, with a vast number of product listings that are continuously updated. This means a scraping tool needs to be fast and flexible to keep up with new listings, price changes, and updates in product descriptions. Using only traditional tools like Puppeteer, Selenium, or Playwright might not suit these needs.
- Sophisticated Anti-Scraping Measures: eBay employs a range of anti-scraping technologies to protect its data. These include CAPTCHAs, IP blocking, and sophisticated algorithms that detect and protect from scraping attempts. Bypassing these measures without violating the site’s terms of service is a significant challenge.
- Data Quality and Accuracy: Ensuring the accuracy and quality of scraped data is critical. Given the volume and variability of data on eBay, it's easy for a scraper to retrieve outdated, incomplete, or irrelevant data, leading to flawed analyses and decisions.
- Legal and Ethical Considerations: Navigating the legal and ethical aspects of web scraping is crucial. To avoid legal repercussions and maintain ethical data collection practices it’s important to abide by eBay’s terms of service and comply with international data protection laws.
- Resource Intensiveness: Web scraping, particularly at a large scale, can be resource-intensive. It requires substantial computational power and bandwidth, especially when dealing with a site as large as eBay.
Given these challenges, the need for an advanced scraping tool becomes crucial. This is where Bright Data’s Web Scraper IDE shines. It's not just a scraping tool but a comprehensive solution designed to address the mentioned challenges.
Bright Data provides solutions ranging from no-code datasets to scraping solutions (besides the Web Scraper IDE) and proxy networks to cover all your needs. For this article, you’ll be utilizing the power of the Web Scraper IDE provided by Bright Data for scraping eBay data.
Tools and Setup
To follow this article, the primary tool you need is an active Bright Data account. The Bright Data Web Scraper IDE allows you to scrape directly from the integrated IDE without leaving the browser.
Moreover, you can call the scraper however you want, whether using an API or invoking it manually. The tool is designed to significantly reduce development time and provide limitless scalability for your web scraping projects.
Built upon a robust unblocking proxy infrastructure, it offers a comprehensive solution for bypassing common web scraping challenges like CAPTCHAs and IP blocks. The IDE simplifies the scraping process by providing pre-built JavaScript functions and code templates from major websites, including eBay, enabling you to build efficient web scrapers rapidly and on a large scale.
Some of the key features of the Web Scraper IDE include:
- Pre-made Web Scraper Templates: These templates allow you to quickly start projects and tailor existing code to your specific requirements.
- Interactive Preview: This feature lets you observe your code in action and swiftly debug any errors.
- Built-in Debug Tools: Using the built-in debuggers, you can debug and fix issues from previous crawls.
- Browser Scripting in JavaScript: Using pure JavaScript, you can easily manage browser control and parsing codes.
- Auto-scaling Infrastructure: With its auto-scaling infrastructure, the IDE eliminates the need for heavy investment in hardware or software for managing large-scale web scraping projects.
- Built-in Proxy & Unblocking: It can emulate geo-locations with automated retries and CAPTCHA-solving features.
- Integration Capabilities: The IDE can trigger crawls on a schedule or via API and connect seamlessly with major storage platforms
For more information, check out the official documentation.
Now that you know the tool required for this tutorial, let’s sign up for a free trial to get started.
Creating an account for Bright Data is pretty straightforward.
- Visit this URL and click on the Sign Up button.
- Now, fill in the form with the required details, accept the license agreement and privacy policy, and click the Create Account button. You can also choose Google Sign Up to get started quickly.
- Once created, you’ll be redirected to the Bright Data dashboard. You can access the products they offer from here.
Now that you’ve successfully created an account, you’re now finally ready to scrape eBay data.
How to Scrape eBay Data
As already mentioned, you’ll be using the Web Scraper IDE for this tutorial. To get started with the Web Scraper IDE, choose the Dashboard and Web Scraper IDE option from the sidebar and click on the Get Started button under the Web Scraper IDE option.

Clicking on this will redirect you to the IDE page, and a pop-up will open asking if you want to start from scratch or if you want to use a pre-made template.
If you choose to start from scratch, you’ll need to write the parser and the interaction code by yourself, which can be a little more time-consuming than selecting a template. However, this gives you more flexibility and control over what and how you want to scrape specific web pages.
But to get started quickly, and because Bright Data already provides you with a pre-made template for scraping eBay data, you’ll be using the template.
Hover over the eBay Products option, and click the Use Template button.

Once selected, you’ll be able to view the IDE with pre-written codes.
First, let’s familiarize ourselves with what’s happening on the screen. Without the code, the IDE should look like this:
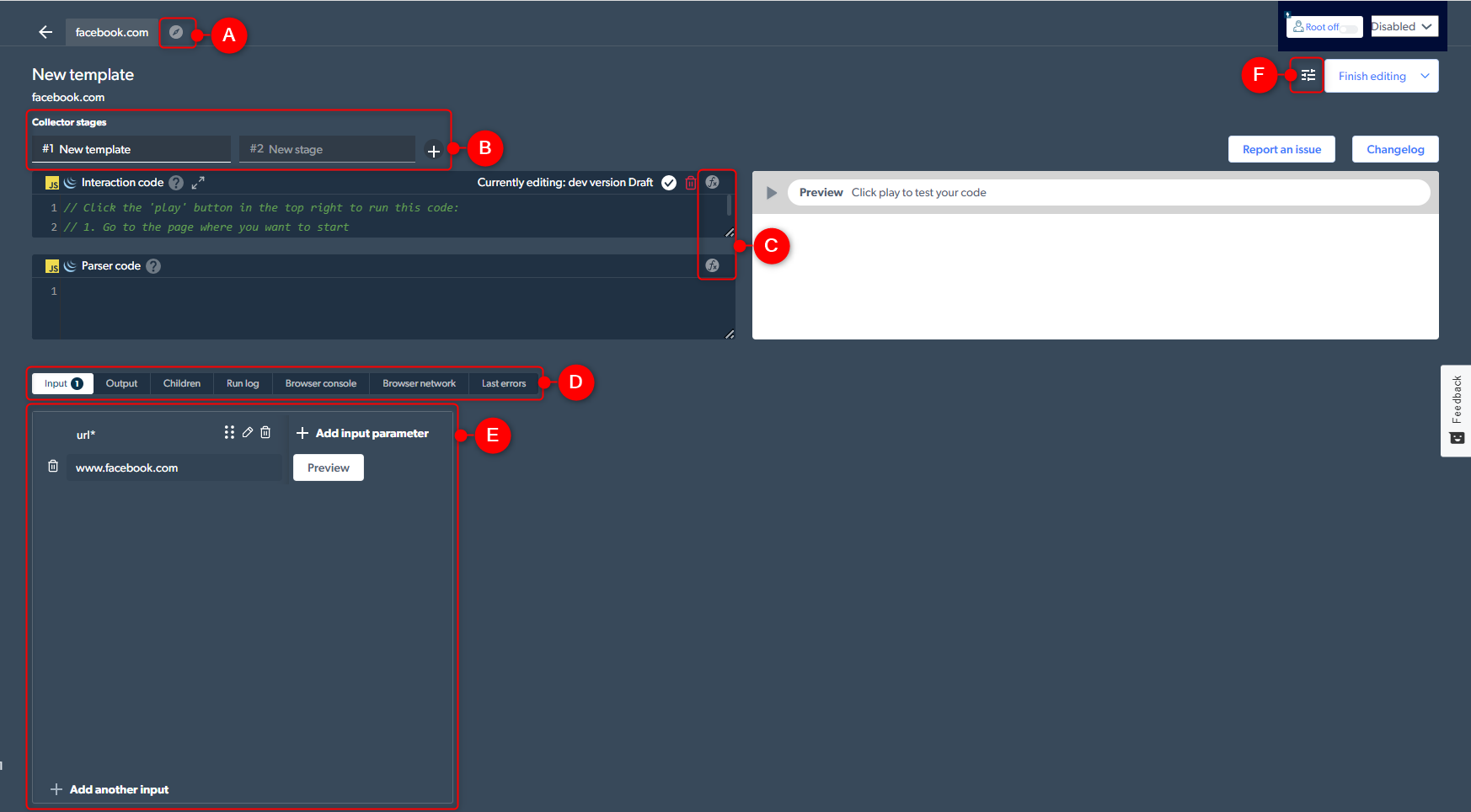 Source: BrightData
Source: BrightData
The sections marked in the image above are as follows:
A. See More Examples: Access built-in template code examples.
B. Add Another Step (Stage): Useful for multi-page data collection with commands like next_stage and run_stage for stage interaction.
C. Help: Offers a list of commands, explanations, and usage examples, including how to find data selectors.
D. Debugging Tabs: Includes tabs for input parameters, output data, next-stage inputs (Children), code execution logs (Run Log), browser console and network logs, and recent error information.
E. Input: Define input parameters, add test values and preview test runs.
F. Code Settings: Adjust error mode behavior and take screenshots during tests.
Because you have selected to use a template, the input tab of the IDE will be prefilled with a few options, and the parser and interaction code will also be pre-filled.

In the input tab, you'll find fields for keyword, count, location, and condition. The Bright Data Web Scraper uses these to extract details. The keyword and count are the only mandatory fields in this case, while others are optional.
To tailor the scraper, you can modify these fields. For instance, to scrape eBay for LED lamps, delete existing inputs, add 'led lamp' as the keyword, and set the count to 10.
Once you've entered the required details, hit the 'Preview' button to see a preview of how the results will look after scraping.

The preview window will display the source code of the page. You can also toggle between the source code mode and the preview mode from this window.
Once the scraping is done, it’ll display the scraped data in the output tab. You can also download a sample of the scraped details directly from the IDE.

By default, the eBay scraper will visit the UK eBay website and show the prices in GBP. If you want to scrape from eBay.com, you can update the interaction code to scrape from eBay.com:

Now, clicking on the Finish Editing button will save the collector. In the next screen, if you want, you can update the keyword, count, set a deadline, and click on the Start button. This page is for initiating the scraper manually. You can also start the scraper using API. The cURL code can be found in the Initiate by API tab.
Visiting the Statistics page will display the status of your collector. The page will also display the total records, job time, success rates, and other relevant information.

From here, you can also download the file in multiple formats like JSON, CSV, XLSX, or NDJSON. Downloading the file will display all the relevant records scraped by the Web Scraper IDE. And you have successfully scraped data from eBay. Here’s the output in XLSX format:

You can easily change the keyword, run the collector using the API, or manually initiate it. You can also set up a CRON job to scrape data from the Subscribe tab based on your time and interval.
Conclusion
In this comprehensive guide, you've explored the intricacies of scraping eBay data, a task crucial for staying competitive in the ever-evolving e-commerce landscape, from understanding the unique challenges of eBay's sophisticated platform to leveraging Bright Data’s Web Scraper IDE. With its user-friendly interface, advanced features, and robust infrastructure, this tool has simplified the scraping process and enriched it with efficiency and precision.
Whether you're analyzing market trends, consumer behaviour, or competitive data, the insights from eBay can be helpful in many ways. By utilizing Bright Data’s Web Scraper IDE, you're not just collecting data but unlocking many opportunities. The platform's ability to bypass common scraping obstacles like CAPTCHAs and IP blocks and its scalable infrastructure ensures you can focus on what matters most - analyzing and utilizing the data to drive your business forward.
So, if you wish to try the Web Scraper IDE for yourself, sign up for the free trial.
Comments
Loading comments…