
Importance and Applications of Web Scraping
Data Harvesting for Business Intelligence:
- Market Research: Web scraping allows businesses to collect real-time data on market trends, consumer behavior and competitor strategies, facilitating decision-making clear intention.
- Lead Generation: Extracting data from various sources allows businesses to generate leads, identify potential clients, and understand their needs.
Content Aggregation and Monitoring:
- News and Media Monitoring: Media outlets use web scraping to aggregate news from diverse sources, curating content for their platforms.
- Price Tracking: E-commerce businesses use web scraping to monitor competitors’ prices, adjusting their own pricing strategies accordingly.
💡 Also Read: How to Scrape E-Commerce Sites with Octoparse's No Code Scraping Tool
Job Market Analysis:
- Talent Acquisition: HR professionals use web scraping to analyze job market trends, identify in-demand skills and benchmark salaries.
- Resume Parsing: Automated extraction of resumes from job portals streamlines the hiring process.
Financial Analysis:
- Stock Market Data Extraction: Traders and financial analysts utilize web scraping to gather real-time stock prices, financial reports, and market sentiments for informed investment decisions.
This is just a tip of the iceberg when it comes to web scraping, there’s more to it and its limitless possibilities. Here’s an example of datasets of companies on LinkedIn using Bright Data.
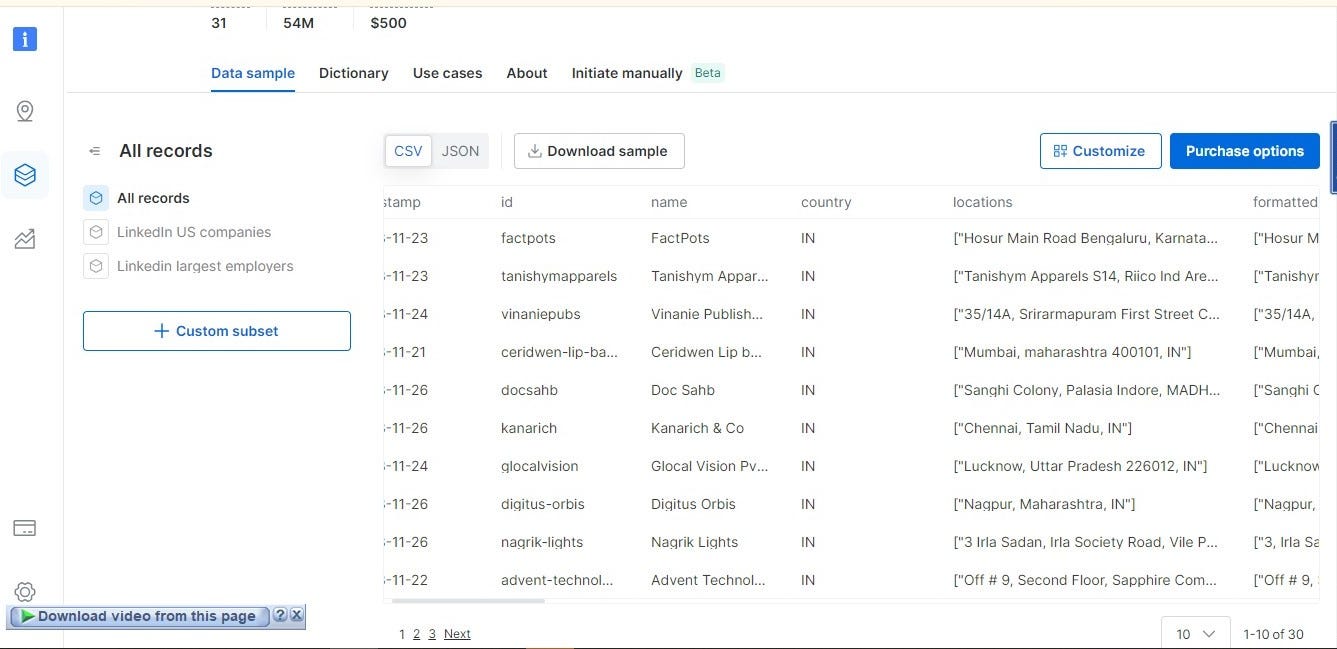
How Web Scraping Works
Basics of HTTP Requests:- GET and POST Methods
HTTP (Hypertext Transfer Protocol) is the groundwork of data communication on the web. It involves the exchange of data between the user’s web browser and the server. The two basic methods used in HTTP requests are GET and POST.
GET Method:
- Purpose: Retrieving data from the server.
- Data in URL: Parameters are appended to the URL.
- Visibility: Parameters are visible in the URL.
- Caching: Can be cached and bookmarked.
- Example URL:
https://example.com/api/data?param1=value1¶m2=value2 - Practical Example in Web Scraping:
// Using fetch API for a GET request in web scraping
fetch("https://example.com/api/data")
.then((response) => response.json())
.then((data) => console.log(data));
POST Method:
- Purpose: Submitting data to be processed to a specified resource.
- Data in URL: Parameters are sent in the request body.
- Visibility: Parameters are not visible in the URL.
- Caching: Generally not cached.
- Example URL:
https://example.com/api/data - Practical Example in Web Scraping:
// Using fetch API for a POST request in web scraping
fetch("https://example.com/api/data", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
param1: "value1",
param2: "value2",
}),
})
.then((response) => response.json())
.then((data) => console.log(data));
During web scraping, these HTTP methods play an important role when interacting with websites. looking into the matter, when you need data from a website, you might use a GET request. If you need to submit a form to a website and retrieve the results, you can use a POST request.
Always be aware of the terms of service of a website when scraping data, as some may prohibit or restrict automated access to their content. Additionally, consider the ethical use of web scraping, ensuring that your actions align with legal and ethical standards.
Understanding HTML/CSS: Document Object Model (DOM)
HTML (Hypertext Markup Language) and CSS (Cascading Style Sheets) are the building blocks of web content. The document object model (DOM) represents the structure of a document as a tree of objects, where each object corresponds to a part of the document. This hierarchical structure allows dynamic access and modification of document content.
Document Object Model (DOM):
- Definition: The DOM is a programming interface. It represents the structure of a document as a tree of objects.
- Tree Structure: Each HTML element becomes a node in the tree, and the relationships between nodes reflect the structure of the document.
- Access and Manipulation: With DOM you can interact with HTML and XML documents using programming languages like JavaScript.
Practical Example in Web Scraping:
Consider a simple HTML page:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Sample Page</title>
</head>
<body>
<div id="content">
<h1>Hello, World!</h1>
<p>This is a sample paragraph.</p>
</div>
</body>
</html>
You can use either Python or JavaScript to access and manipulate elements when it comes to web scraping.
// Accessing elements using DOM
const pageTitle = document.title;
const paragraphText = document.querySelector("p").textContent;
console.log("Page Title:", pageTitle);
console.log("Paragraph Text:", paragraphText);
What’s happening:
document.titleaccesses the title of the HTML document.document.querySelector('p')selects the first<p>(paragraph) element..textContentretrieves the text content inside the selected element.
Understanding the DOM is important in web scraping because it allows you to programmatically interact with web pages and extract information from them. You can navigate the DOM tree, select elements, and extract data, making web scraping a powerful tool for extracting data from web pages.
Role of Selectors in Web Scraping: CSS Selectors and XPath
Selectors are important in web scraping because they allow you to precisely target and extract data from HTML documents. Two commonly used types of selectors are CSS and XPath selectors.
- CSS Selectors:
- Definition: CSS selectors are templates used to select and style HTML elements. During web scraping, they are used to target specific elements for extraction.
- Examples:
element: Selects all instances of the specified element.#id: Selects the element with the specified id..class: Selects all elements with the specified class.
Practical Example using CSS Selectors:
<ul>
<li class="fruit">Apple</li>
<li class="fruit">Banana</li>
<li class="vegetable">Carrot</li>
</ul>
Web scraping in JavaScript:
// Using CSS Selector
const fruitList = document.querySelectorAll(".fruit");
fruitList.forEach((fruit) => {
console.log("Fruit:", fruit.textContent);
});
.fruit is a CSS selector that selects all elements with the class "fruit."
- XPath:
- Definition: XPath is the language used to navigate XML and HTML documents. It provides a way to navigate the document tree and locate elements.
- Examples:
/: Selects from the root node.//: Selects nodes in the document from the current node that matches the selection, regardless of their location.[@attribute='value']: Selects nodes with a specific attribute value.
Practical Example using XPath:
<div>
<p title="info">Important Details</p>
</div>
XPath in web scraping:
// Using XPath
const xpathResult = document.evaluate(
'/div/p[@title="info"]',
document,
null,
XPathResult.ANY_TYPE,
null
);
const paragraph = xpathResult.iterateNext();
console.log("Paragraph Text:", paragraph.textContent);
the XPath expression /div/p[@title="info"] selects the <p> element with the attribute title set to "info."
In web scraping, choosing between CSS selectors and XPath depends on the specific structure of the HTML document and the complexity of the selection needed, however, that’s only if one wants to go through the hassle of doing it from scratch because, with Bright Data Web Unlocker, you can just focus on data collection while the rest is taken care of.
Whether it’s Python or JavaScript used for Web Scraping, you can rest assured that Bright Data has your back while you explore the unknown.
Tools and Libraries
Popular Programming Languages for Web Scraping:
So the practical examples used above have been centered on JavaScript however you’re wrong if you think it’s only centered on that language. The two most popular ones are Python and JavaScript (Node.js) and neither is more important than the other.
Notable Libraries
Python:
- Requests Library: Python’s requests library is commonly used to send HTTP requests to web pages, allowing them to retrieve HTML content.
import requests
response = requests.get('https://example.com')
html_content = response.text
- Beautiful Soup: Beautiful soup (bs4), a Python library that extracts data from HTML & XML files. Provides Python idioms for iterating, searching, and modifying parse trees.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
- Scrapy: Scrapy is an open source collaborative web crawling framework for Python. It provides a set of predefined methods for common tasks and allows you to define your own spiders.
import scrapy
class MySpider(scrapy.Spider):
name = 'example'
start_urls = ['https://example.com']
def parse(self, response):
# Parse the HTML content here
pass
- Selenium: Selenium is a browser automation tool often used for scraping dynamic websites that rely on JavaScript for rendering content.
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://example.com')
- Robots.txt Compliance: When scraping a website, it’s important to follow the rules defined in the website’s robots.txt file. Libraries such as Python’s robotparser can help you check whether a particular URL is allowed to be scanned.
from urllib import robotparser
rp = robotparser.RobotFileParser()
rp.set_url("https://example.com/robots.txt")
rp.read()
allowed = rp.can_fetch("*", "https://example.com/page")
Python’s rich ecosystem of libraries and frameworks makes it a preferred choice for web scraping tasks. However, it’s essential to be aware of ethical considerations, legal implications, and the terms of service of the websites you are scraping. Always check if a website allows web scraping in its robots.txt file and terms of service.
JavaScript (Node.js):
- Cheerio: Cheerio is a fast and flexible implementation of jQuery for the server. It is often used with Node.js for parsing and manipulating HTML content.
const cheerio = require("cheerio");
const $ = cheerio.load(html);
const title = $("h1").text();
- Puppeteer: Puppeteer is a node library that provides a high-level API on top of the Chrome DevTools protocol. This is used for browser automation, such as web scraping of websites that use JavaScript to load content.
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://example.com");
// Perform scraping within the browser context
await browser.close();
})();
Using Node.js and JavaScript for web scraping provides a single language for both client-side and server-side scripting, making it a versatile choice. However, just like with Python, it is important to consider legal and ethical aspects when scraping websites. Always check the terms of service and robots.txt files of the sites you crawl to ensure compliance.
Here’s a sample using Bright Data:
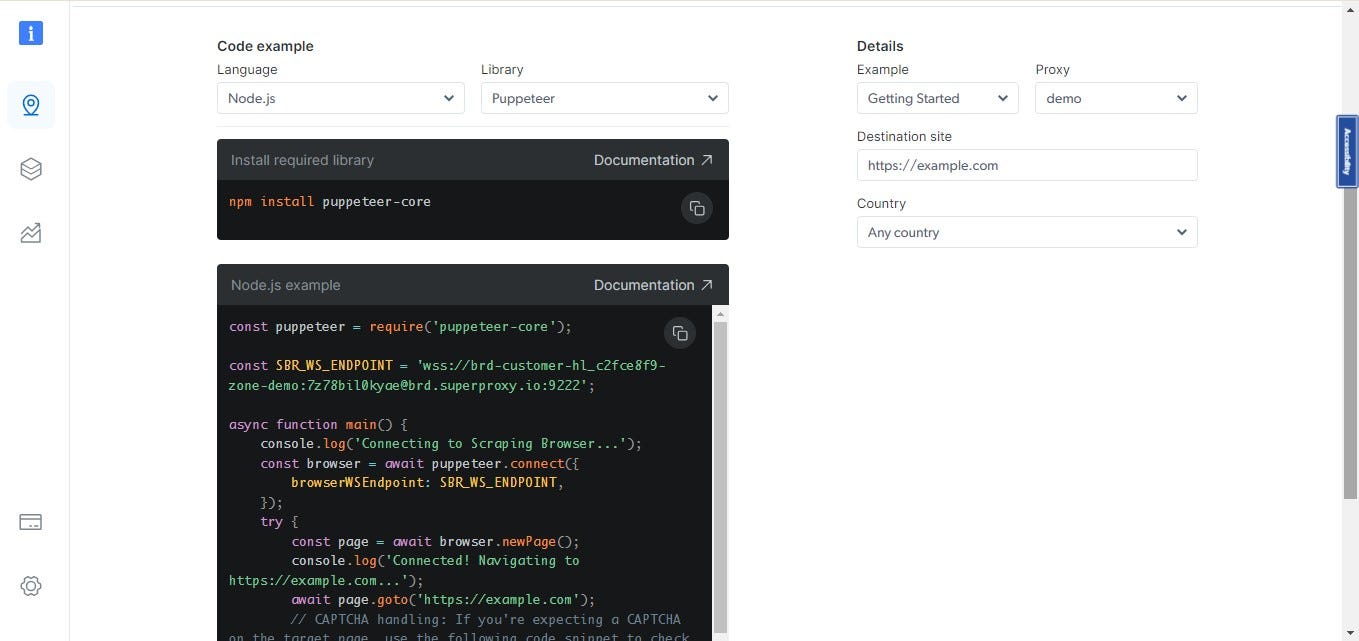
Common Challenges and Solutions
Web scraping can pose a variety of challenges, especially when dealing with dynamic and interactive websites. Here you will find common challenges and solutions:
A. Handling Dynamic Content
Challenge: Websites often use JavaScript to load content dynamically after the initial page load.
Solution:
- Use Headless Browsers: Tools like Puppeteer or Selenium allow you to automate browsers and scrape dynamically loaded content.
- Inspect Network Requests: Identify the API endpoints that the website uses to fetch data dynamically. Directly call these endpoints in your script.
- Wait for Elements: Implement mechanisms to wait for elements to appear using techniques like waiting for a certain class or attribute.
B. Dealing with AJAX
Challenge: Asynchronous JavaScript (AJAX) requests can be challenging to handle in traditional scraping.
Solution:
- Browser Automation: Use headless browsers to interact with pages as a user would, handling AJAX requests seamlessly.
- Reverse Engineering APIs: Analyze network traffic using browser developer tools to identify and mimic the API calls made by the site.
- Proxy Servers: Use proxy servers to route requests, and handle AJAX requests more effectively.
C. Rate Limiting and IP Blocking
Challenge: Websites may implement rate limiting to prevent abuse or block IP addresses engaging in aggressive scraping.
Solution:
- Set Delays: Introduce delays between requests to mimic human-like behavior and avoid triggering rate limits.
- Use Proxies: Rotate IP addresses using proxy servers to distribute requests and prevent IP blocking.
- Randomize User Agents: Rotate user agents to avoid detection. Some websites may block requests from known scraper user agents.
Ethical and Legal Considerations
When engaging in web scraping, it is important to consider ethical and legal aspects to ensure responsible and lawful behavior. The main considerations are:
A. Respect for Website Policies:
- Terms of Service (ToS): Every website has a Terms of Service agreement that users are expected to adhere to. These terms often explicitly state whether web scraping is allowed or prohibited. Always review and respect a website’s terms before scraping.
- Acceptable Use Policies: Websites may have specific rules and guidelines regarding how their data can be accessed and used. Adhering to these policies is crucial for ethical scraping.
- User Agreements: If a website requires users to agree to certain terms before accessing content, scraping without permission may violate those terms.
B. Robots.txt:
- Understanding robots.txt: The
robots.txtfile is a standard used by websites to communicate with web crawlers and scrapers. It specifies which parts of the site should not be crawled or scraped. Always check and respect the directives in a site'srobots.txtfile. - Crawling Etiquette: Even if a site’s
robots.txtfile doesn't explicitly prohibit scraping, it's ethical to crawl responsibly. It’s very important to avoid making too many requests in a short period to prevent placing an undue load on the server.
C. Legal Implications:
- Intellectual Property: Scraping content that is protected by intellectual property laws (e.g., copyrighted text or images) without permission may lead to legal consequences.
- Data Protection Laws: In some jurisdictions, data protection laws regulate how personal information can be collected and used. Ensure compliance with laws like GDPR (General Data Protection Regulation) when handling user data.
- Trespass to Chattels: Unauthorized scraping that causes harm or disruption to a website’s normal operations may be legally actionable under the principle of trespass to chattels.
- Contract Law: If a website’s terms explicitly prohibit scraping, violating those terms could lead to legal consequences based on contract law.
Best Practices:
- Obtain Permission: Whenever possible, seek permission from the website owner before scraping. Some sites provide APIs for accessing data in a structured manner.
- Attribute Content: If you use scraped content, provide appropriate attribution to the source.
- Monitor Changes: Websites may update their policies or
robots.txtfiles. Regularly check for changes and adjust scraping practices accordingly. - Legal Advice: When in doubt, consult with legal professionals to ensure compliance with applicable laws.
Adhering to ethical and legal standards not only helps avoid legal troubles but also fosters a positive relationship between web scrapers and website owners. Responsible scraping contributes to a healthier and more sustainable online ecosystem.
Conclusion
In summary, mastering the art of web scraping requires a combination of technical skills, adaptability, and ethical considerations. The techniques described here, such as handling dynamic content, handling AJAX, and handling rate limiting, highlight the need for ingenuity when tackling the complexities of web scraping. Tools such as headless browsers, reverse engineering APIs, and proxy servers allow developers to efficiently extract data from various sources.
Also, Web scraping comes with several challenges. Specifically, anti-bot and anti-scraping techniques are becoming increasingly popular. This is where proxies come into play.
If asked where can I find a reliable source, well, Bright Data proxy is the first recommendation, It has proven its efficiency over the years and you’re sure to have your requirements met via their proxy. You can access the web scraping tool provided by Bright Data.
View of a verified user:

View of accessed proxies:
More information on how to avoid being blocked can be accessed here on Bright Data.
Comments
Loading comments…