Image generated with Stable Diffusion
One of the challenges with using LLM in production is finding the right way to host the models in the cloud. GPUs are expensive so hosting a classic web server with a model will result in high costs. Due to that developers rely on the following options:
- Use LLMaaS services like Amazon Bedrock or OpenAI API which effectively give access to the LLM on a per request-token basis
- Host models on CPU web server which results in lower costs
- Host on a serverless compute like AWS Lambda
- Utilize event-driven architecture to minimize idle time
I covered the CPU web server use case in the blog posts for LLAMA.CPP and TGI by HuggingFace + AWS Copilot. In this blog post I want to cover how to use serverless compute for LLM, what are the use cases and limitations (spoiler alert: many) and what are the things to look forward to. Finally, I will share the step-by-step guide on how to deploy Mistral 7B model to AWS Lambda using LLAMA.CPP with OpenBLAS support. Also check out the awesome article on how GPT4ALL was used for running LLM in AWS Lambda.
Serverless compute for LLM
Serverless compute became extremely popular for various types of workloads, ML included. Users like the ease of starting with it, and the fact that it scales with your load — meaning it can both scale to zero, which is useful when you just started, as well as scale to 1k concurrent requests to handle peak loads.
There are several challenges associated with using serverless for ML workloads, which are more apparent for LLM use cases:
Benchmarks for Mistral 7B on AWS Lambda
- Cold start — takes ~5 minutes, making it impossible to use for real-time applications without provisioned concurrency.
- Prediction time — ~300ms per token (~3–4 tokens per second) — both input and output. How does it compare to GPUs? Based on this blog post — 20–30 tokens per second. In short — the CPU is pretty slow for real-time, but let’s dig into the cost:
- Cost — ~$50 for 1M tokens. Is it much? Based on this blogpost, OpenAI Pricing and Amazon Bedrock Pricing :
Pricing comparison for LLMaaS providers
So it is expensive if you want to use the default model, but in case you want to use something self-hosted, that becomes a good alternative to hosting on GPU machines which may cost >$10k per month.
Cold start
This is the init time before AWS Lambda starts processing the request itself. In ML cases that means two things:
- Time to load libraries — e.g. ONNX or TGI
- Time to load and initialize the model — this one is slow by itself and even slower when we come into the LLM world (where models could be easily more than 2GB in size)
Yes, but:
- AWS Lambda provides SnapStart feature which significantly reduces cold starts and can be effectively used for ML workloads. Things to keep in mind:
- [Java runtime] SnapStart is currently only supported for Java runtime. That adds limitations, but ONNX does work on Java and it’s possible to run ONNX with SnapStart.
- [Package] SnapStart only works with ZIP package deployment meaning it is subject to 250 MB limit. That means you may be limited in terms of libraries you could use (ONNX fits though).
Sidenote:
- [ONNX] Microsoft released ONNX version for Llama 2 model which could be used for Java runtime, but — it currently needs torch library for the tokenizer.
Hardware limitations
AWS Lambda currently only supports CPU and is limited in terms of max CPU/RAM — 6vCPU and 10 GB RAM.
Yes, but:
- [GPU] Some platforms offer GPU serverless workers like Cloudflare or RunPod. Keep in mind though that they may come at a higher price and more limited scaling compared to AWS Lambda.
- [Graviton] AWS Lambda has Graviton support which works better for compute-intensive workloads.
What would change the numbers
- SnapStart support for more languages/runtimes => unblocks SnapStart for LLM
- ONNX only support for LLMs => unblocks Java SnapStart for LLM
- GPU workers => unblocks faster predictions
- Higher CPU/RAM limits => unblocks larger models
Summary
- Current Serverless compute limitations don’t allow using it for real-time LLM applications or models larger than 10GB (~13B parameters and more)
- In terms of cost it is more expensive than LLMaaS services, but cheaper than GPUs in case you don’t have large load
Step-by-step guide for Mistral 7B on AWS Lambda
Important parts of the stack:
- AWS Lambda as serverless compute
- Docker packaging to handle large models
- LLAMA.CPP inference framework compiled with OpenBLAS
- Compatible Mistral-7b model from https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF
Things of note:
- Compiling LLAMA.CPP with OpenBLAS support helps to speed up the inference but requires installing additional dependencies
- Keep in mind that the newer LLAMA.CPP only supports GGUF models so GGML models would need to be converted (with script like this one)
- Pre-built docker image is available publicly here https://gallery.ecr.aws/v3o8p9b9/llama_cpp-lambda-mistral . Feel free to reuse for your project or troubleshoot your case.
Dockerfile
ARG FUNCTION_DIR="/function"
FROM --platform=linux/amd64 python:3.11 as build-image
ARG FUNCTION_DIR
RUN mkdir -p ${FUNCTION_DIR}
WORKDIR ${FUNCTION_DIR}
COPY model/ model/
COPY requirements.txt .
RUN apt-get update
RUN apt-get -y install libopenblas-dev
RUN CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install --target ${FUNCTION_DIR} --no-cache-dir llama-cpp-python
RUN pip install --target ${FUNCTION_DIR} --no-cache-dir -r requirements.txt
COPY lambda_function.py .
ENTRYPOINT [ "/usr/local/bin/python", "-m", "awslambdaric" ]
CMD [ "lambda_function.handler" ]
FROM --platform=linux/amd64 python:3.11-slim as custom-docker-runtime
ARG FUNCTION_DIR
WORKDIR ${FUNCTION_DIR}
RUN apt-get update
RUN apt-get -y install libopenblas-dev
COPY --from=build-image ${FUNCTION_DIR} ${FUNCTION_DIR}
ENTRYPOINT [ "/usr/local/bin/python", "-m", "awslambdaric" ]
CMD [ "lambda_function.handler" ]
Lambda handler
from llama_cpp import Llama
MODEL_SESSION = None
def handler(event, context):
global MODEL_SESSION
if MODEL_SESSION is None:
MODEL_SESSION = Llama(model_path="model/mistral-7b-v0.1.Q5_K_S.gguf")
instruction = event.get("instruction", "What is the capital of Spain?")
response = MODEL_SESSION(instruction, max_tokens=32, stop=["Q:", "\n"], echo=True)
return {"result": response}
Steps
- Download model from https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF
- Git clone code example from https://github.com/ryfeus/lambda-packs/tree/master/LLAMA_CPP
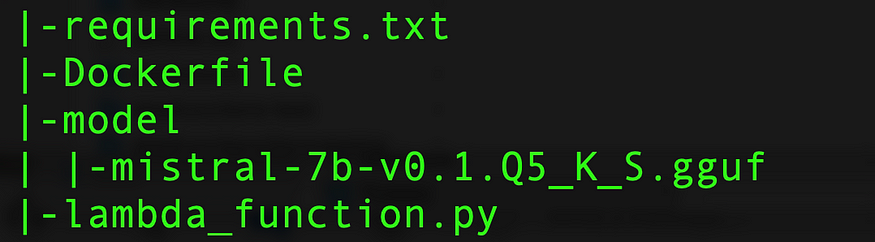
- Make sure the code structure is the following
- Build the docker image locally and tag it
docker build -t llama.cpp-lambda .
docker tag llama.cpp-lambda:latest <account_id>.dkr.ecr.<region>.amazonaws.com/llama.cpp-lambda:<tag>
- Create ECR repo with the name `llama.cpp-lambda` in your repo (or different name and just change the command below)
- Log into ECR to push docker images and push your docker image
aws ecr get-login-password --region <region>| docker login --username AWS --password-stdin <account_id>.dkr.ecr.<region>.amazonaws.com
docker push <account_id>.dkr.ecr.<region>.amazonaws.com/llama.cpp-lambda:<tag>
- Create AWS Lambda with docker image packaging and choose the pushed image. Make sure you provision enough RAM (10GB) and big enough timeout (>5 minutes)
- Done — you can now run Mistral-7B with LLAMA.CPP on AWS Lambda
Conclusion
Currently serverless compute is not in the state where it would be able to support real-time predictions and the cost is the important factor, but in the following cases that may be a good option:
- A self-hosted custom model which has to be deployed in the cloud — e.g. you need full control over the model or no external dependencies
- Custom models that are not currently hosted by one of the LLMaaS providers
- Event-driven architecture where speed is not important — e.g. report generation
Ultimately, serverless compute for LLMs is an area ripe for growth. Organizations and developers should keep a close watch on this space, as the confluence of reduced costs, increased flexibility, and technological advancements may soon make it the go-to option for deploying LLMs in the cloud.
Comments
Loading comments…