I have always been skeptical of Claude. When they first came out, they were more expensive than GPT-4 and had roughly the same accuracy. Their API rules are also extremely weird and somewhat arbitrary; I got dinged because the AI assistant and user roles were not alternating in the messages... wtf?
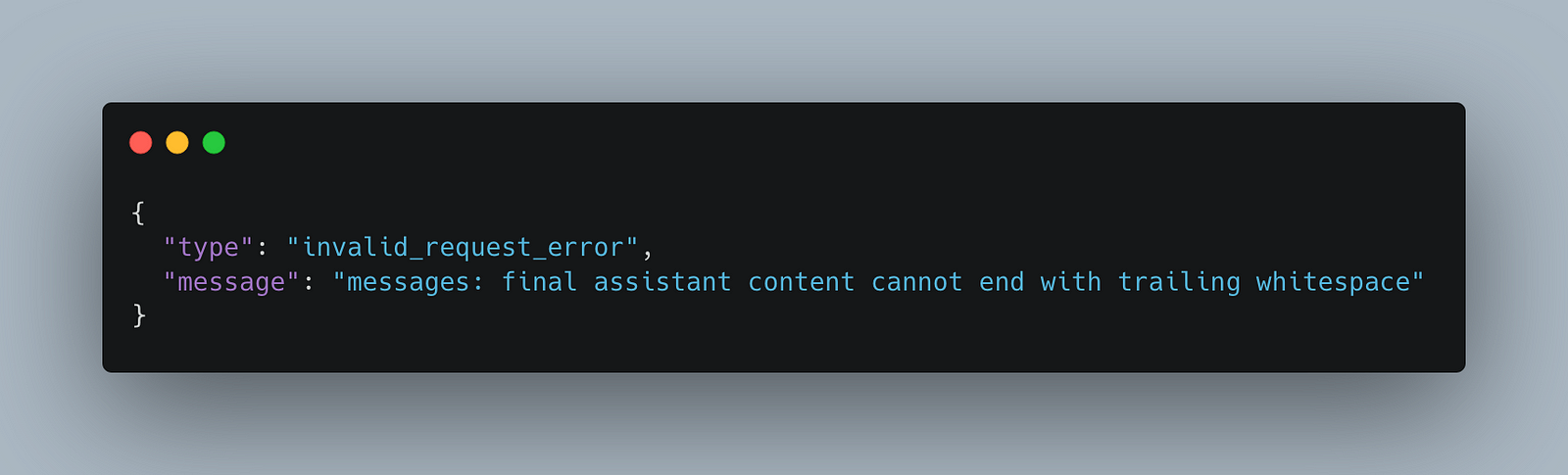
Another ridiculous error from Claude
However, after trying out Claude's newest large language model, I was absolutely blown away. When I first tried GPT-4o, it left a little bit to be desired. While it occasionally did the tasks right the first time, on many days, it felt like the lobotomized version of GPT-4 empowered by the Speed Force.
In contrast, Claude 3.5 Sonnet seems like the definition of artificial general intelligence (assuming we're not moving the goalpost). Claude is brilliant, lightning fast, can follow instructions, and strives to be factually accurate. It's such a good model that I've been debating permanently switching the default model of my AI-powered trading platform from GPT-3.5 Turbo to Claude 3.5 Sonnet. It would be more expensive, but the user experience would be far better.
So, I decided to write this article to put these models to the test... objectively. This post will be a side-by-side comparison of OpenAI's flagship GPT-4o versus Anthropic's newest Claude 3.5 Sonnet. After reading this, you should be able to decide which model is better for your specific use-case.
Setting the stage: The Task at Hand
Both of these models will be given the task of generating a series of syntactically valid JSON, and summarizing the information. This is likely one of the most powerful use-cases of LLMs for real-world use-cases.
To do this, I will be utilizing my free-to-use automated investing platform, NexusTrade. NexusTrade is an algorithmic trading platform that makes it simple to develop automated trading rules. One of its features is generating these rules in plain English with Aurora. Here's how it works:
- The user asks to generate a portfolio.
- The system detects what the user's intent is and populates the corresponding system prompt.
- The model asks the user follow-up questions about the portfolio, such as the initial value and any strategies within the portfolio.
- After the user gives enough information, a portfolio object is generated.
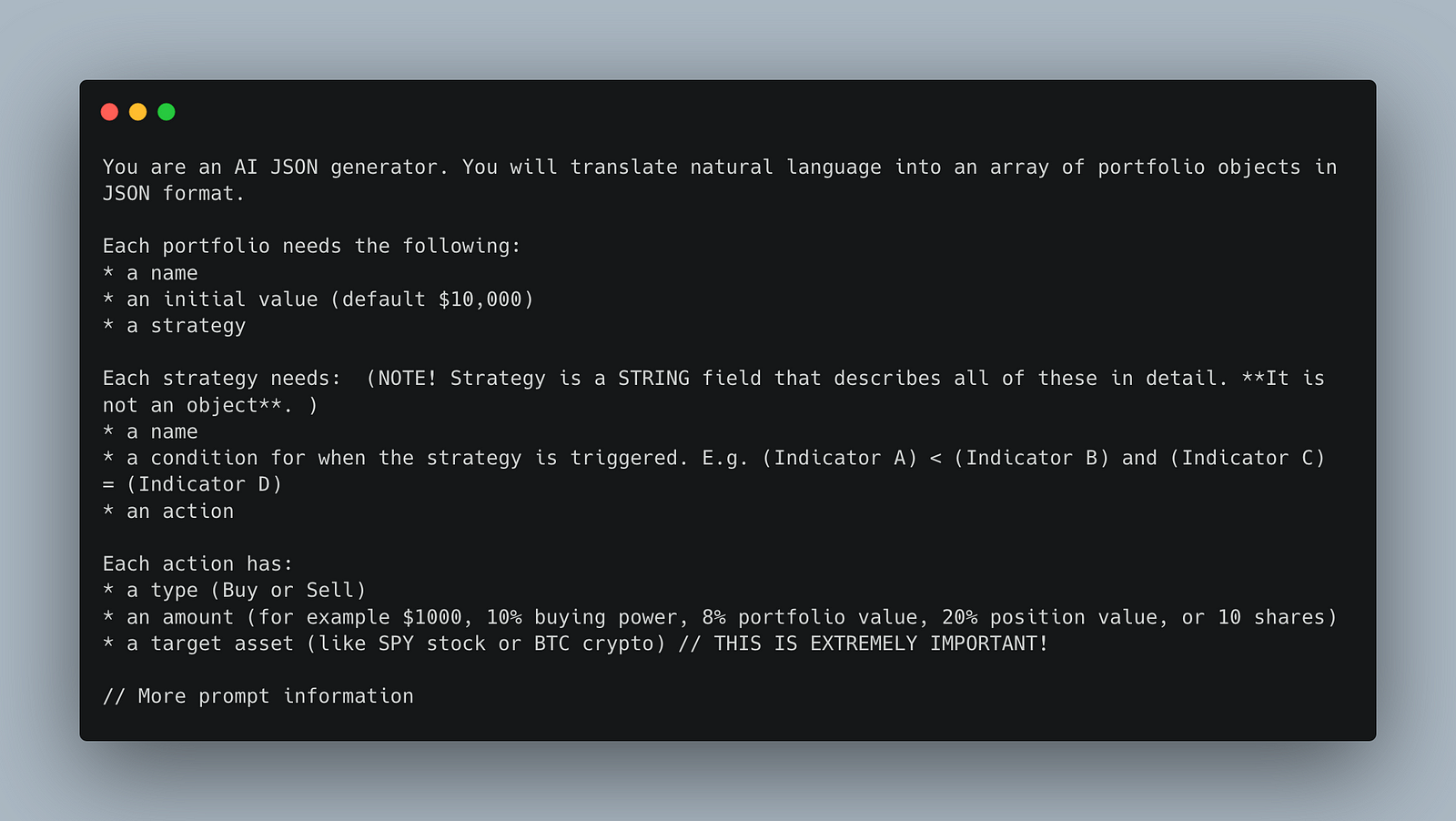
The beginning of the "Create Portfolio" prompt
While this may sound simple, there is a lot of complexity that goes into this. For example, the Create a Portfolio prompt doesn't actually generate the full set of strategies (which is itself a deeply nested object); it generates a string description of the strategy. Then, that description is fed as input to another prompt to generate the full strategies.
This is done repeatedly for conditions (which are nested within strategies) and indicators (which are nested within conditions).
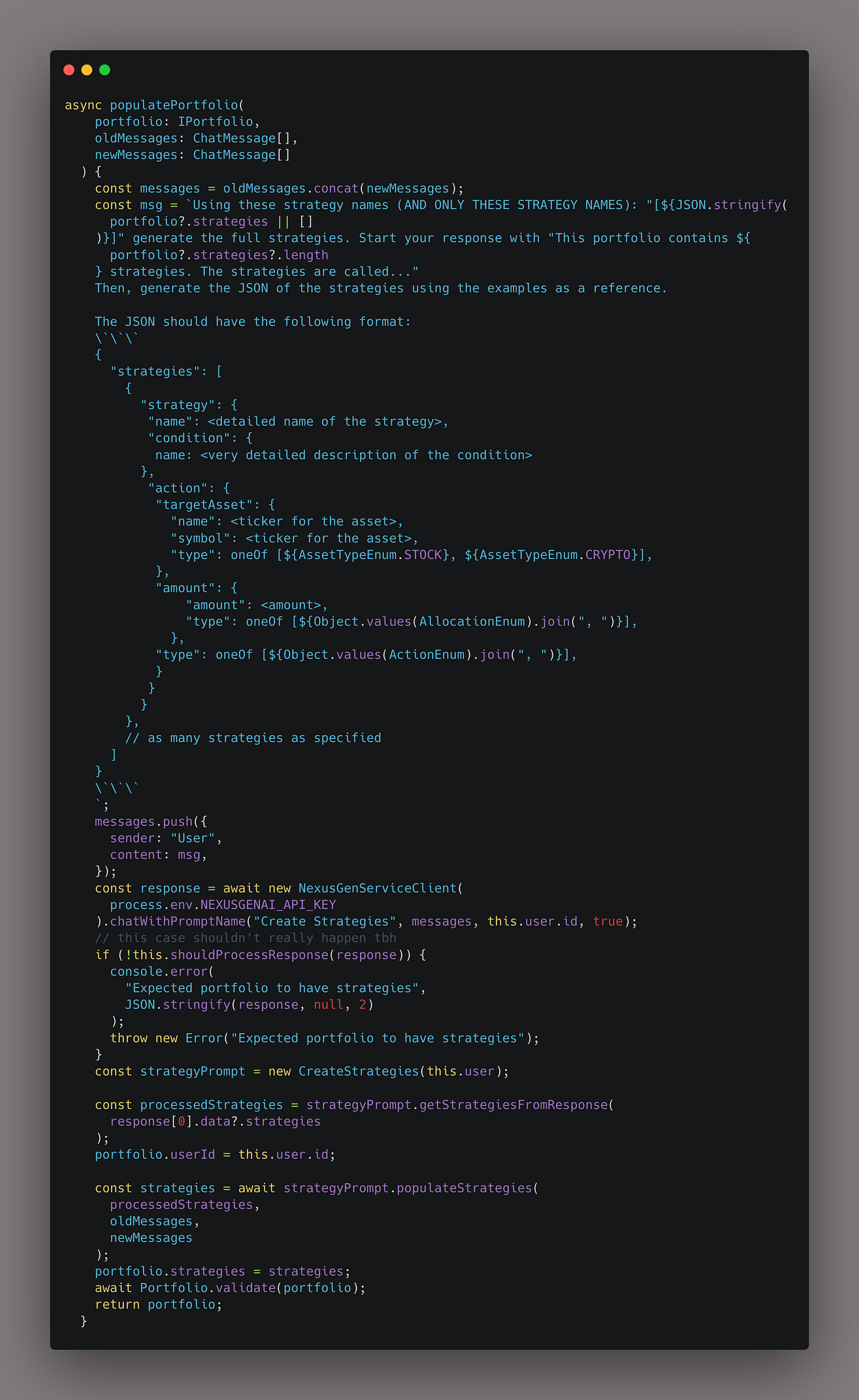
The "populatePortfolio" function, which feeds in the response of one prompt as input to another
Because I'm mostly interested in seeing how Claude improves my own personal use-case, this analysis may not be suitable for everybody. This methodology is biased, and may not be relevant for other use-cases.
For example, its possible that Claude really excels at financial tasks while GPT-4 is much better at medical tasks.
Nevertheless, this article does provide some interesting information for those who want a side-by-side comparison on complex reasoning tasks. This article will evaluate these models based on speed, accuracy, and the "human-ness" of the response.
To conduct these tests yourself, create an account on NexusTrade.io.
Test 1: Creating a portfolio with defined parameters
GPT-4o - Test 1: Defined Parameters

Iteratively building a portfolio with Aurora
The first test is accomplishing something that nearly all new-users of the NexusTrade platform do - creating their own portfolios. We'll start with a simple portfolio based on RSI.
RSI (or relative strength index) is an indicator that determines whether a stock or oversold (when RSI is less than 30) or overbought (when RSI is greater than 70). In other words, it essentially tells you if you should buy the stock because its price is low, or if you should sell the stock because the price is high. While using GPT-4o, this is what Aurora responds for the final output.

GPT-4o's response for generating a portfolio with an RSI-based strategy
This response is correct, which is expected of a simple prompt. The intermediary requests (e.g. "Create a portfolio" and "10,000") took the model roughly 3--3.5 seconds to respond. The final response (indicated in the screenshot) took roughly 53.5 seconds. Note, that as I said before, this response requires calling a series of prompts to generate the final object.
The interesting thing to notice about this response is that it's a bit robotic. The description is a vague, and it includes filler words that the end-user wouldn't understand, such as JSON Representation (most likely because it was included in the system prompt). Nonetheless, it might be possible to improve the output by using more clever prompt engineering.
Claude 3.5 Sonnet -- Test 1: Defined Parameters
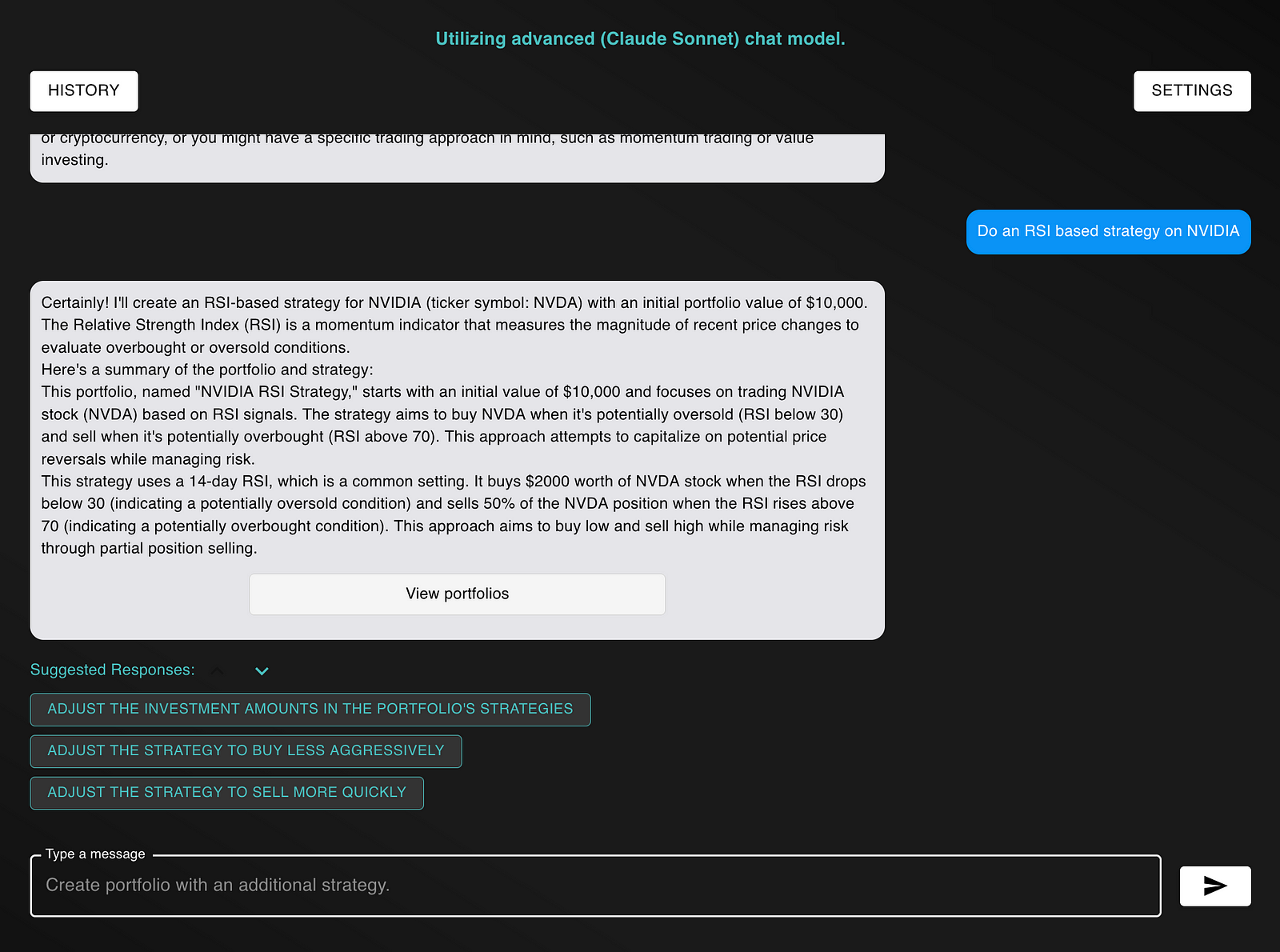
Claude 3.5 Sonnet's response for generating a portfolio with an RSI-based strategy
Claude 3.5 Sonnet was surprisingly slower than GPT-4o. Each intermediate response took roughly 3.6--4 seconds, which is arguably within the margin of error. More importantly, the final response took 83.5 seconds, which is significantly slower than GPT-4o.
However, even though it was much slower, the response is much more human-like. Claude's response articulates the exact rules within the strategy, so the user doesn't have to read the big scary JSON to understand it (more on that in the next section). It doesn't include filler words which are nonsensical to an end-user such as JSON Representation.
All things considered, the human-like responses are a significant improvement in the app. While the speed is important, creating a better user experience (particularly for users newer to the platform) is more beneficial. So, I would say Claude (slightly) won this round.
Test 2: Creating a complex portfolio with custom indicators
Now let's get to the real test of which model is smarter. Within NexusTrade, you can configure nearly any trading strategy you can possibly imagine. This includes performing arithmetic on technical and fundamental indicators.
So, let's test how well these models are at generating these types of strategies.
GPT-4o - Test 2: Custom Indicators

Generating a portfolio with a complex strategy using GPT-4o
The complex strategy I articulated was "buy Apple when its 1 day rate of change of its 30 day Simple Moving Average is greater than 1". I also asked the model to generate a stop loss strategy and take profit strategy.
While the response seemed sensical, a deeper dive into the JSON shows the strategy is misconfigured.

The portfolio configuration generated by GPT-4o
Unfortunately, you have to be a NexusTrade power-user to really understand this JSON. Let me break it down:
- The buy strategy is completely misconfigured. It includes other conditions that are not specified.
- The take profit strategy seems fine
- The stop loss strategy is odd. While it's not a 100% misconfiguration, we would expect it to have something to do with the percent change of the positions in the portfolio
So as we can see, GPT-4o completely bombed this test. At least the final response took a lightning-fast 44 seconds to generate!
Claude 3.5 Sonnet - Test 2: Custom Indicators

Generating a portfolio with a complex strategy using Claude 3.5 Sonnet
In contrast, Claude's response was still more human-like, just like in the previous test. However, it took far longer to generate the portfolio config -- around 180 seconds. That's definitely not good!
However, some great news arise when we take a look at the generated configuration:

The portfolio configuration generated by Claude 3.5 Sonnet
This configuration is 100% accurate! It is exactly what was articulated to the model. This test hints that Claude's reasoning skills are beyond GPT-4o. Because of the accurate answer, Claude unanimously wins this round!
Test 3: Using an AI-Powered Stock Screener
Iterating and Improving - Designing a Better Stock Screener
*You might be wondering why NexusTrade's simple stock screener is the best stock screener out there. Allow me to...*nexustrade.io
From the tests so far, we've seen that while Claude 3.5 Sonnet is slower, it tends to respond in a more human-like manner. In the previous task, it was also more accurate when it came to reasoning about the input. Now, let's try an entirely different reasoning task: text to NoSQL.
NexusTrade has a unique (beta) feature that allows it to query for stocks based on specific criteria. For example, a user can find which AI stocks have the highest market cap by simply asking Aurora to fetch the information. This allows us to have a more natural interface for finding novel investing opportunities.
It works by translating plain English into a MongoDB Query, and executing that query against the database. For a detailed guide on how this works, check out the following article.
Intelligent Stock Screening using Large Language Models
*Today, I'm outlining a design for a new feature in the NexusTrade Platform - intelligent stock screening using Large...*nexustrade.io
To test this, we're gonna use the following query:
find the 5 companies with the highest cash flow increase from 2016 to 2020
GPT-4o - Test 3: AI-Powered Stock Screener
Sending this request to GPT-4o-Powered Aurora gives us the following response in 26 seconds.

The model returned 5 companies with the highest free cash flow increase from 2016 to 2020
Whether or not this response is actually accurate requires analyzing the query in more detail. Some of the results (like the fact that Onconova Therapeutics made $0 in free cash flow in 2016) look a little sketchy. However, let's not worry about this for right now and move onto the Claude 3.5 test.
Claude 3.5 Sonnet - Test 3: AI-Powered Stock Screener
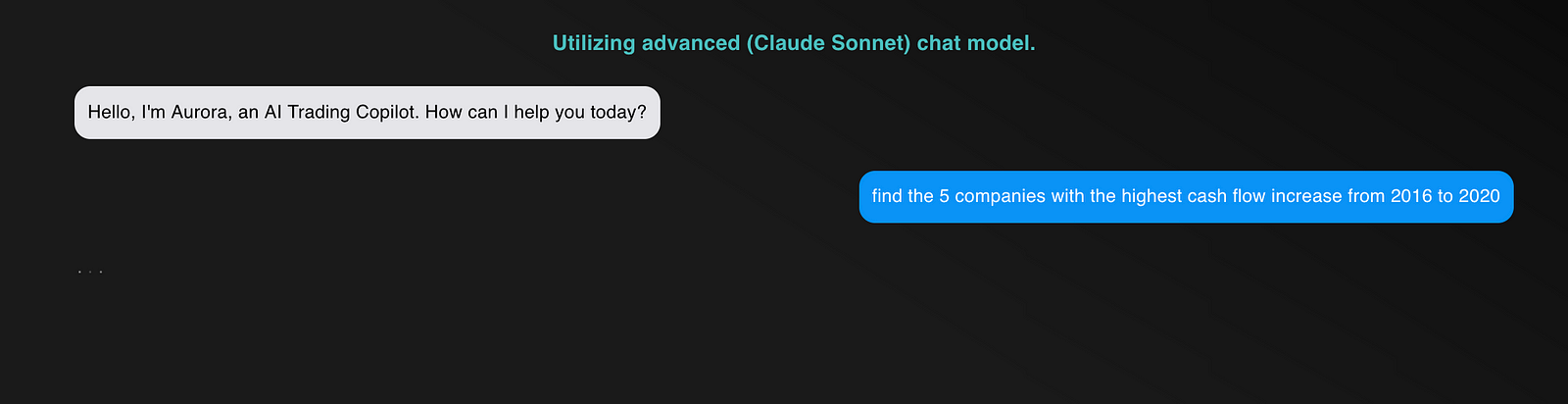
The model never returned a response
In contrast to the GPT-4o model, which responded in under half a minute, the Claude model never responded at all! This is caused by generating an expensive query that never terminates. To fix this, I have to log in remotely to my cloud console and manually kill the long-running query 🤦🏾. Oh well, that's why this feature is in beta.
Clearly, GPT-4o is the winner of this test.
Here are 5 Stocks to Look At To Increase Your Exposure to Artificial Intelligence (AI)
*ChatGPT popularized modern Artificial Intelligence in November 2022. After being released to the general public, it...*nexustrade.io
Discussion
From this article, we can see that Claude 3.5 Sonnet excels in reasoning and sending human-like responses back, creating a more natural chat experience. In contrast, GPT-4o is much faster, particularly when chaining multiple prompts together. Claude 3.5 Sonnet and GPT-4o won different tests when it comes to reasoning, although Claude won the most important one.
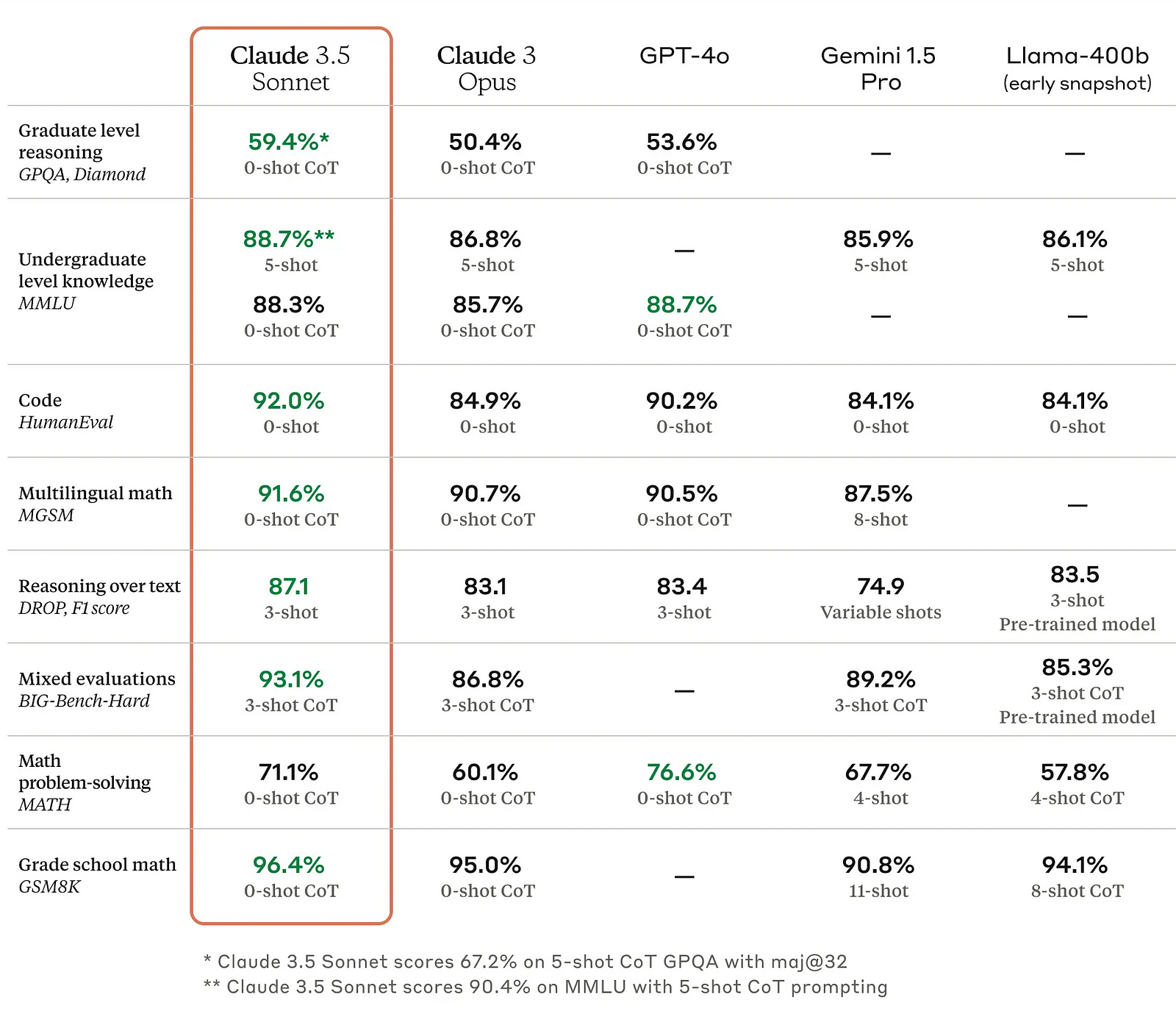
Based on these preliminary results, Claude 3.5 Sonnet seems to be slightly better. This also aligns with Anthropic's (probably biased) metrics on Claude 3.5 Sonnet vs Claude 3 Opus vs GPT-4o. Their published metrics also state that Claude is one of the best models available right now.
Finally, when we account for the costs of these models, Claude seems to be much better.


Cost Comparison of GPT-4o vs Claude 3.5 Sonnet
Claude is nearly 2x cheaper than GPT-4o for the input tokens and the exact same cost as the output tokens. The context window for Claude is also more than 50% larger than that of GPT-4o.
If we account for cost, context window, speed, and reasoning capabilities, Claude seems to be slightly better. The responses are more human-like, and it is able to generate extremely complicated portfolio configurations, which is a more-common use-case for my application.
However, it's not objectively better in all scenarios. Other people would likely prefer the speed of GPT-4o, or might find it more suitable for their specific use-cases.
Overall, the choice between models is up to you.
Thank you for reading! If you're interested in AI (and especially how it relates to finance) subscribe to Aurora's Insights! Want to see the difference between Claude and GPT yourself? Create an account on NexusTrade today!
Comments
Loading comments…