Photo by Myriam Jessier on Unsplash
Whether you're a market researcher, a pricing analyst, or an entrepreneur seeking insights, web scraping from e-commerce platforms can provide a wealth of data that holds the potential to drive informed decision-making in your business. However, navigating the complex landscape of web scraping requires more than just technical prowess --- it demands a nuanced understanding of the intricacies of web scrapers.
In this article, we'll delve into the five essential tips that will equip you with the technical know-how to efficiently gather data. Each of these tips will tackle five hurdles you may face when scraping e-commerce websites and how to get around them, so that you can make the most of e-commerce web scraping efforts.
Whether you're a seasoned data scientist, a startup decision maker or just a curious individual seeking a competitive edge, the insights gathered here will help in significantly improving the efficiency of your e-commerce scraping efforts. Without further ado then, let's dive right in!
1. Make Use of Geo-Targeting
If you're scraping e-commerce sites to gain data-driven insights for your business, geo-targeting a specific location or several different locations can be extremely important. Collecting comparative data about products from different regions can allow you to identify untapped opportunities, analyze competition, and make informed decisions about new markets. Conversely, with location-specific data, you can create targeted marketing campaigns or pricing strategies that resonate with customers' unique needs and interests in that specific region.
However, scrape e-commerce websites long enough and you're inevitably bound to run into geo-location blocks. Based on your IP address, some websites limit access altogether to only certain geo-locations. For example, if you reside in the UK and wish to examine and compare price listings for a product in the US, websites may prevent you from doing so. Websites can also customize and restrict content and information based on the location, thus limiting the data you have access to.
The simplest way to get around geo-location blocks is by implementing proxies into your existing scraping script and rotating them as per your use case (based on the location you need to access). By masking your IP address, proxies allow your scrapers to appear as if they were real users browsing from various locations worldwide, which helps circumvent geolocation blocks.
But there's a catch. Modern e-commerce websites incorporate more sophisticated IP blocking mechanisms. Free proxies, while good for one-time projects, may not get the job done if your project requires automating the data collection process for continuous fresh insights. Free proxies (procured from data centers) are easily detectable and most websites these days maintain a list of IPs from data centers to block. For this reason, it's worth looking into high-quality ethically-vetted residential proxies, which are real residential IPs provided by Internet Service Providers and are significantly less likely to get flagged as suspicious.
💡 Pro Tip: Incorporating IP rotation manually into your scraping script can also be a hassle but is crucial if you're looking to gather data at scale in an uninterrupted manner. You could consider going with a more advanced tool which offers high-quality residential proxies as well as automated IP rotation right out of the box, and can be easily integrated into your existing Puppeteer/Selenium/Playwright script.
2. Avoid IP Blocks and Bot-Detection Mechanisms
When an e-commerce site notices an unusual amount of traffic from your IP address, which is a regular thing if you're trying to automate the data collection process, the next course of action for that site is to limit the number of requests an IP can make in a given time frame. This is known as rate-limiting and can pose a significant challenge to your ability to gather fresh, continuous, and accurate data.
Along with that, websites also make use of header information to track your "browser fingerprint" and incorporate bot-detection mechanisms to flag and block IPs if their behavior is found to resemble that of a web crawler instead of a genuine user. This too can throw a wrench into your web scraping efforts.

💡If you're curious to know more about bot-detection and other anti-scraping measures, check out this article here.
Just like geo-location blocks, to successfully bypass rate limits, you can use proxies and rotate them after a couple of requests. Free data center proxies may not always cut it for the same reasons as mentioned before, so make sure to use residential proxies if required.
Bypassing bot-detection mechanisms based on header information, however, is trickier. The gist of what happens here is that whenever you send a request to a website's server, it includes a User-Agent header. This header contains information about the requesting client's software, device, and operating system. However, bots and scrapers usually have custom or uncommon User-Agent strings that deviate from the typical pattern of a legitimate user, allowing websites to flag them.
The simplest solution is to manually modify the User-Agent header in your scraping script to mimic a commonly used web browser or device, making requests appear more like those of legitimate users. However, this is a bit of a stopgap measure as there's no way to tell exactly which parts of a User-Agent string a specific website is checking.
A more robust solution is provided by the Scraping Browser which you can integrate in your existing Selenium/Puppeteer/Playwright scripts. The Scraping Browser utilizes an unlocker infrastructure which can analyze target site requirements on the fly and generate an appropriate User-Agent string for each, complete with HTTP2's handling of advanced header field compression and server push.
This gives you the flexibility to tailor the generated User-Agents to meet the specific requirements of your target site, effectively creating User-Agent strings that closely resemble legitimate user traffic.
3. Bypass CAPTCHAs
Speaking of blocks, one of the most common blocks you'll encounter scraping an e-commerce site is a CAPTCHA. If you want to see how common they are, check out this thread here, or this one here...or this one here (yes, there are plenty more).
Most e-commerce websites make use of CAPTCHAs as an anti-bot/scraping mechanism. Since CAPTCHAs tend to be interactive challenges meant to be solved by human beings, when your script comes across these, they no longer know how to proceed. And you guessed it. Your automated uninterrupted scraping process meets an abrupt end.
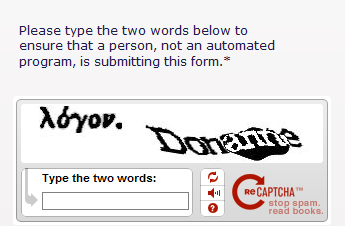
How to get past CAPTCHAs then? Well, there are a number of ways, with dedicated tools being available for this in the form of third-party libraries. But you'd still need to integrate these into your existing tech stack which can be challenging (and sometimes, these tools are not 100% reliable as websites can update their CAPTCHA mechanisms).
When it comes to bypassing CAPTCHAs, the most foolproof method is to strike at the cause rather than the symptoms (like reCAPTCHA). What does this mean? CAPTCHAs are generally generated based on browser/device fingerprints and when the website suspects that this "fingerprint" may be that of a bot rather than a genuine user. The best method to bypass CAPTCHAs then is to be able to successfully emulate browser/device fingerprints so that the website doesn't flag your activity as suspicious.
This is exactly where the Scraping Browser shines because its unlocker infrastructure is able to emulate browser fingerprint information including plugins, fonts, browser version, cookies, HTML5 canvas element or WebGL fingerprint, Web Audio API fingerprint, operating system, screen resolution, and more. In cases where a CAPTCHA may still be generated, its CAPTCHA-solving technology can still take care of them. Moreover, it's a managed service, so you don't have to worry about updating your code manually each time the website updates its CAPTCHA-generation mechanism.
4. Take Dynamic Websites Into Account
In 2023, dynamic websites are becoming more popular, and they pose a problem to web scrapers. Dynamic websites are websites that generate content and present information to users in real-time, often in response to user interactions or other data inputs. Unlike static websites, which display the same content to all users and don't change unless manually updated, dynamic websites customize their content based on various factors, such as user preferences, database information, and real-time events.
The main problem with dynamic websites is that the code and content are not automatically loaded when the user or scraper enters the site, and as a result, there's virtually nothing to scrape. For static websites, this is usually not a problem, as all the content is usually ready once the page is loaded. But dynamic websites usually retrieve their data from a database or external source, and they choose which data to retrieve due to the interactions or inputs of the user/scraper.
How to get around this? Well, in general, you could just use Selenium configured specifically to use a real browser window. When you do this, you can control your web browser and automatically extract data from dynamic websites by writing just a few lines of code. However, using a headful browser with a full GUI (like in this instance) slows the process down and usually creates performance issues. Headless browsers are much faster but are far more easily detectable by bot-detection mechanisms.
But what if you could have the best of both worlds? The Scraping Browser provides exactly that, being a full-featured, GUI-enabled headful browser, with an added twist: it runs on Bright Data's own servers. You merely connect to it via a WebSocket URL, using the Selenium/Puppeteer/PlayWright API to connect to it remotely (you can find instructions here). This gives you all the speed, and parallelization abilities of headless browsers, with the benefits of headful browsers --- namely, being harder to detect --- without ever having to worry about performance or scaling.
5. Make Sure the Scraped Data is in a Desired Format
When scraping data from multiple websites, a sometimes ignored but crucial choice involves selecting the format to store your collected data. Depending on your requirements and inclinations, you have various options at your disposal, including CSV, JSON, or XML. Each format carries its own set of merits and drawbacks, spanning readability, compatibility, and file size.
Consider CSV, which stands as a straightforward, widely accepted format seamlessly integrable into spreadsheet applications. However, it might not faithfully preserve data structure or hierarchy. In contrast, JSON emerges as a nimble, versatile format capable of housing intricate and nested data, though it might necessitate more parsing and manipulation. XML offers structured data with validation potential, yet its verbosity and heft could be notable.
Carefully weighing these attributes can guide your decision-making process. Sometimes it's worth going with a ready-made off-the-shelf low-code scraping tool that allows you to gather structured data in a wide variety of formats such as JSON, NDJSON, CSV, or Microsoft Excel.
This flexibility allows you to switch between data formats according to your need and use case, without needing to rely on additional third-party libraries for converting the data. Additionally, since the data is already delivered in a clean and structured manner, you don't have to spend additional time and resources on cleaning unstructured data.
Bonus Point: Use Datasets
This is a bit of a cheat code. If you need reliable and accurate data from e-commerce websites but don't want to go through all the trouble of running and maintaining a web scraper, you could simply acquire or request for ready-made datasets.
When requesting for datasets, it helps to choose reliable and well-reputed providers who also abide by major data protection laws such as the EU's GDPR and the CCPA.

To get hold of a dataset, all you have to do is set up the project, approve the schema the data will be delivered in, specify the scope and frequency of the data you want, and you'll get a personalized subscription plan based on your needs.
Data formats in JSON, NDJSON, and CSV, will be delivered via Snowflake, Google Cloud, PubSub, S3, or Azur, and you'll be able to Initiate requests via API for on-demand data access.
Conclusion
In this article, we looked into five tips to be able to scrape e-commerce websites in an unhindered manner and make the most of our scraping operations. Each of these five tips tackled five problems you're likely to encounter when scraping prominent e-commerce websites.
Depending on the scope of your project and your use case, you can either go with individual solutions for these problems or go for a more comprehensive approach with the Scraping Browser which takes care of all of these problems at once. The Scraping Browser also comes with a free trial so feel free to check it out to see if it suits your web scraping needs.
Scraping e-commerce websites can be complicated and tedious sometimes, but by adhering to these five expert tips, you can navigate the complexities of scraping e-commerce websites with finesse and precision and ensure an uninterrupted scraping process that delivers fresh and accurate data.
Happy scraping!
Comments
Loading comments…