This tutorial will show you how to utilize the Python Requests module using a proxy server. In order to avoid their IP addresses being blocked by websites, developers sometimes utilize many proxies for security and anonymity. Other advantages of proxies include their ability to get around filters and restrictions.
Feel free to learn more about proxy servers and how they work before getting started with the tutorial.
Also, if you want to know more about and try the best-performing proxies in the industry, you can find out more here.
Prerequisites and Installation
This guide is for Python users who want to scrape from behind a proxy. Follow along with the tutorial to get the most out of it. Here are the prerequisites for the tutorial:
-
Since the tutorial is all about using the requests module behind a proxy, you must have Python installed in your system. If not, install it for your operating system from here.
-
You should have some experience with Python. As a beginner, you can learn about the requests module here.
-
Check if the requests module is installed in your system using the command:
pip freeze
The above command will list down all the installed dependencies with their versions. If you don't find the requests module in the list, you can install it using the command below:
pip install requests
How to use Python Requests?
Let us learn how to use the requests package with a simple example.
import requests
url = "https://httpbin.org/ip"
response = requests.get(url)
To make a web request using Python, first, you need to import the requests library. Then you can make an HTTP GET request using the get() method from the requests library. You can store the response that you get from the server in a variable.
In order to read the response from a server, you can use response.text. If the server responds with a JSON response, the requests library has a built-in method response.json() to read JSON-formatted responses.
print(response.json())
Output:
{'origin': '171.76.87.42'}
In the output, you can see the origin IP address is printed.
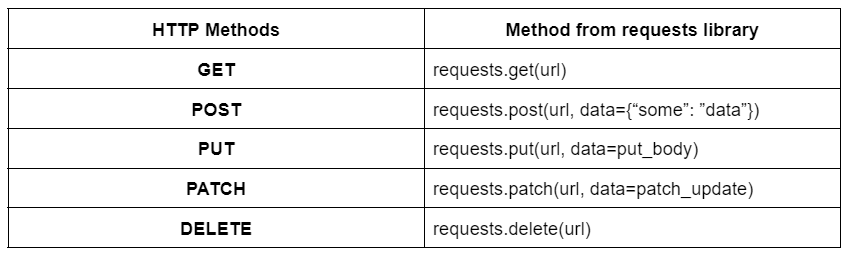
Similar to the get() method, you have several other methods in the requests library. Some of the most popular are:
How to use a Proxy with Python Requests
In order to use a proxy with Python requests, you'll need to pass it while making any request. Let us learn how we can do it.
-
Similar to the above example, import the requests library at the top.
-
Next, define the HTTP and HTTPS connections in a proxies dictionary. This variable needs to include a dictionary that associates a protocol with the proxy URL. Create a variable for the URL of the website you are scraping as well.
-
Create a response variable as the last step that makes use of any of the requests methods. The method will accept two arguments: the URL variable you defined and the dictionary you specified.
import requests
proxies = {
'http': '204.185.204.64:8080',
'https': '204.185.204.64:8080',
}
url = "https://httpbin.org/ip"
response = requests.get(url, proxies=proxies)
print(response.json())
In the above example, the proxies dictionary contains URLs for two separate protocols: HTTP and HTTPS. Their values map to the same URLs with the same ports. However, they can also be different.
Output:
{'origin': '204.185.204.64'}
You can see that the output now shows the origin IP address that is passed in the proxies dictionary.
Note: In the above example, we are using the GET method, but the same proxy setup can also be used for the other HTTP methods.
How to use Proxy Authentication?
The following syntax can be used to modify your code if authentication is required:
proxies = {
'http': 'username:password@204.185.204.64:8080',
'https': 'username:password@204.185.204.64:8080',
}
How to use Proxy Sessions?
You might also want to scrape from websites that use sessions. In that case, a session object would need to be created. Creating a session variable and assigning it to the requests.Session() method will enable you to achieve this.
Similar to before, you would then use the requests method to send your session proxies, but this time you would only pass in the url as the argument.
import requests
session = requests.Session()
session.proxies = {
'http': '204.185.204.64:8080',
'https': '204.185.204.64:8080',
}
url = "https://httpbin.org/ip"
response = session.get(url)
print(response.json())
Notice in the example above that instead of using requests.get(), session.get() method is used.
Output:
{'origin': '204.185.204.64'}
How to use environment variables?
In some cases, you might be reusing the same proxy for each request. Instead of defining the proxies dictionary every time, you can set environment variables for the proxies.
To set the environment variables, use the below command:
export HTTP_PROXY='204.185.204.64:8080'
export HTTPS_PROXY='204.185.204.64:8080'
Now, even if you don't define the proxies within your code, the request will be made using the proxies from the environment variables.
import requests
url = "https://httpbin.org/ip"
response = requests.get(url)
print(response.json())
Output:
{'origin': '204.185.204.64'}
Rotating proxies with Python Requests
Until now, you have seen how to use one proxy. Some developers prefer to use more than one proxy. It's a good practice to use more than one proxy whenever you find yourself constantly scraping from a website because there's a good probability your scraper will be blocked, which will result in the banning of your IP address. So it's better to use rotating proxies to avoid getting banned.
A rotating proxy is a proxy server that gives each connection a different IP address from the proxy pool. You must have a pool of IPs available in order to rotate IP addresses. You can utilize paid services or free proxies that you can find online. But in most cases, you can't rely on free proxies if your application depends highly on scraped data.
How to rotate IPs using Python Requests?
You need a list of free proxies before you can start rotating your IP addresses. Let's now write a script that selects and rotates through proxies.
-
As always, import the requests library at the top of the script. In addition to that, import the random library to choose IP addresses randomly.
-
Create a list of IP addresses and a url variable.
-
Now, within a while loop, choose an IP address randomly from the list of IP addresses and create a dictionary called proxies using the chosen IP address. Make use of this proxies dictionary while making the request. As per your requirement, you can break the loop after the request is made.
Here's the Python script for your reference:
import random
import requests
ip_addresses = [
"198.59.191.234:8080",
"165.154.233.164:8080",
"45.79.90.143:44554",
"71.86.129.131:8080",
"45.79.158.235:1080",
"185.125.125.157:80",
"204.185.204.64:8080"
]
url = "[https://httpbin.org/ip](https://httpbin.org/ip)"
while True:
try:
proxy = random.choice(ip_addresses)
proxies = {"http": proxy, "https": proxy}
response = requests.get(url, proxies=proxies)
print(f"Response: {response.json()}")
if url.startswith("https"):
print(f"Proxy currently being used: {proxies['https']}\n")
else:
print(f"Proxy currently being used: {proxies['http']}\n")
except Exception:
print("Error, checking with another proxy\n")
Notice in the above script, you're printing the IP address being used in each request.
Output:
Error, checking with another proxy
Error, checking with another proxy
Error, checking with another proxy
Response: {'origin': '204.185.204.64'}
Proxy currently being used: 204.185.204.64:8080
Error, checking with another proxy
Response: {'origin': 165.154.233.164'}
Proxy currently being used: 165.154.233.164:8080
Error, checking with another proxy
Response: {'origin': '204.185.204.64'}
Proxy currently being used: 204.185.204.64:8080
Now you can simultaneously rotate and scrape!
Should you use free proxies?
Free proxies can appear tempting due to a perception of ease. You just need to locate the desired place and website. If you're an individual using proxies just for learning purposes or small tasks, then they are a good choice for you.
However, if you're using proxies for business purposes, you should not go with free proxies. First off, I would recommend giving this article by the CEO of Proxyway a read — it goes into detail about the key points to look for when choosing a proxy provider.
But in any case, here are a few reasons why using free proxies for business purposes may be a bad idea:
-
Most free proxies don't support HTTPS: Surprisingly, around 80% of free proxy servers do not support HTTPS connections, despite the fact that the HTTPS protocol ensures that your connection is encrypted. Practically speaking, this implies that it is simple to monitor all of the data you send. So, free proxies are a bad choice if data privacy is a concern in any manner.
-
Cookies might get stolen: Since cookies are used to save your login information, protecting them is crucial. However, if you set up a proxy server to act as a middleman between you and a website, the owners of that proxy server have an easy way to steal cookies as they're being created. This would provide them the ability to log in to the highly sensitive websites you've visited as well as to impersonate you online.
-
Low-quality service: Sadly, even after taking all of the above-mentioned risks, the reward is insufficient. Due to both a lack of financing and the potential for high concurrent usage, free proxies are typically much slower than premium ones.
In short, free proxies are a high-risk, low-reward service when all these elements are taken into account. When compared to free proxies, premium proxies are actually the complete opposite. They are absolutely secure, quick, trustworthy, and genuine. Most provide a range of options depending on the use case, whether you want more advanced Residential Proxies or the usual Datacenter Proxies.
💡 Note: If you do not know what residential proxies are and why you may need them, you can learn more here. For more on how residential proxies and datacenter proxies differ, go here.
All of this enables extensive customization that is very important to your business. Additionally, a premium service gives you access to cutting-edge, ever-evolving solutions.
Bright Data is one of the leading web data platforms in the world that provides such premium proxy services. It provides you with a powerful way to browse anonymously from anywhere in the world.
If you are an individual or a business that relies highly on data, you should definitely check out Bright Data. Bright Data offers a variety of quick, highly secure, quality, and ethical proxy services (including powerful residential proxies) with an unending uptime.
→ Learn more about the different types of proxy services offered by Bright Data
Additionally, Bright Data offers excellent pricing choices, such as Pay per use. When you choose Bright Data's premium proxy solutions, you'll be frequently introduced to various developments like artificial intelligence (AI) and machine learning (ML), which significantly boost the effectiveness of proxies, particularly in industries like web scraping.
Here are the proxy services you get with Bright Data:
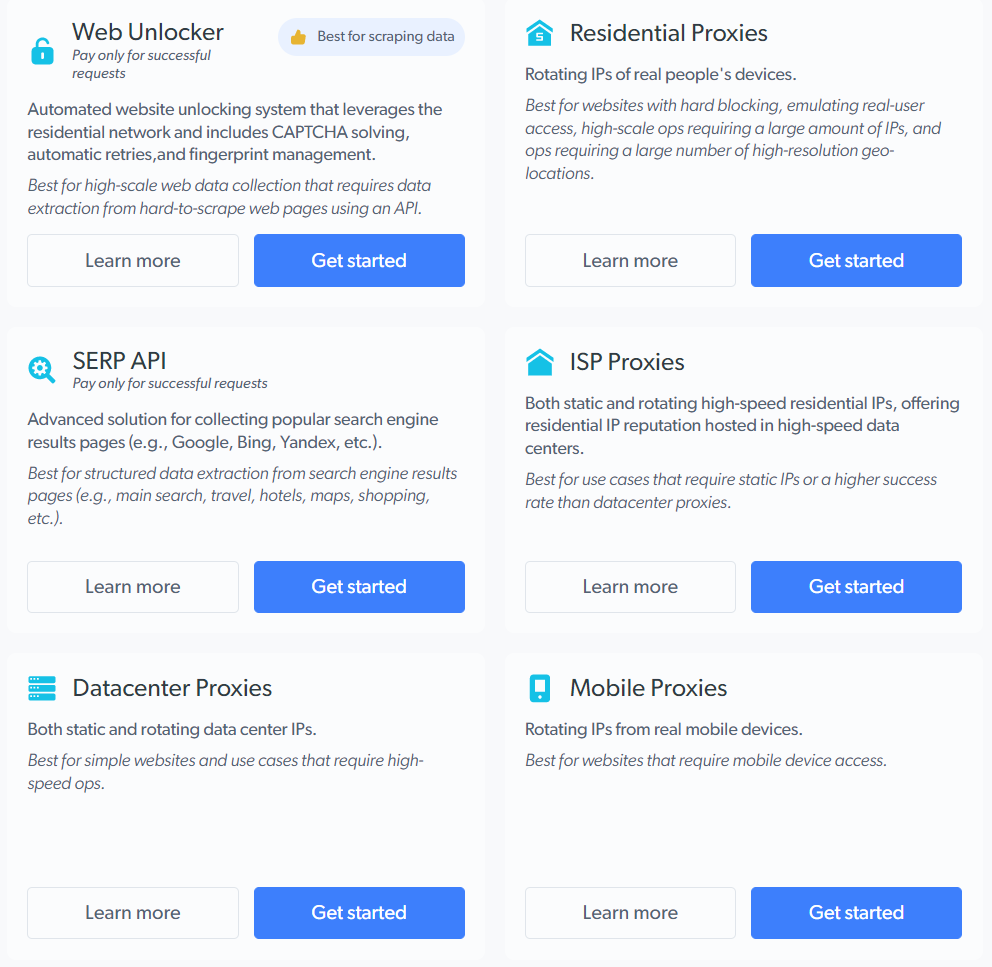
You can choose any of them as per your need without worrying about the problems you face with free proxies.
How to use Bright Data Proxy Service with Python?
As we already discussed why you should not rely on free proxies for business purposes, let us learn how to use Bright Data’s proxy service with Python. It’s actually quite simple, so let’s dig in.
For the sake of this tutorial, we will use ISP Proxies. Register for a free trial by clicking on ‘Start free trial’ and entering your details (you can use your organizational or personal Gmail ID to register for a trial).
Once you’re done, continue with the steps below.
- On the ‘Welcome’ page, click on ‘View proxy products’ under Proxies & Scraping Infrastructure.
- Click on ‘Get Started’ underneath ISP Proxies, this will redirect you to create a new proxy.
- Enter the details as per your need and click on Add Zone to create a proxy.
- Once the proxy is created, you can see the access parameters similar to below:
-
Click on the **Download IPs list **link to download the list of IPs allocated to you. The IPs will contain your proxy URL, port, username, and password separated by a colon(:). The format of each IP is: proxy_url:port:username:password.
-
While making a request, you need to authenticate to the proxy. Thus, a sample Python script will look like this:
import requests
proxies = {
'http': 'lum-customer-hl_abcdef12-zone-isp-ip-85.28.52.81:[password123@zproxy.lum-superproxy.io](mailto:password123@zproxy.lum-superproxy.io):22225',
'https': 'lum-customer-hl_abcdef12-zone-isp-ip-85.28.52.81:[password123@zproxy.lum-superproxy.io](mailto:password123@zproxy.lum-superproxy.io):22225',
}
url = "[https://httpbin.org/ip](https://httpbin.org/ip)"
response = requests.get(url, proxies=proxies)
print(response.json())
Output:
{'origin': '85.28.52.81'}
That's it! We just used Bright Data's Proxy Service to make a successful request.
Conclusion
Even though it may be exciting to immediately begin scraping with your fancy new proxies, there are still a few important things you need to be aware of. To begin with, not all proxies are created equal. There are several varieties, but the three most common are elite proxies, anonymous proxies, and transparent proxies.
The easiest way to avoid being discovered is to utilize an elite proxy, whether it is paid for or available for free. Anonymous proxies might be worthwhile if you just intend to use a proxy for privacy-related purposes. Transparent proxies expose your true IP address and the fact that you are using a proxy server, so it is not advisable to use one unless there is a specific reason to.
Now that everything is clear, it's time to start scraping with a proxy in Python. So go ahead and start making all the requests you can think of!
Comments
Loading comments…