What does GraphQL look like in a world that is transitioning from monolithic architectures to microservices?
In an ideal version of this world, your monolithic backend would be modularized and factored into discrete services with well-defined boundaries. You'd have a GraphQL server (graphql-js, Apollo Server, graphql-yoga, etc.) for each backend, connecting to databases and other APIs to resolve the data they need to serve, and each frontend would use some implementation of a GraphQL client (Apollo Client, Relay, urql) for easy querying/mutating/caching data.
Here's the problem, though: you're using GraphQL all wrong.
Instead of taking advantage of GraphQL's capability to consolidate data retrieval into a single request, you're distributing the data-fetching logic across the client instead - querying large amounts of data from a bunch of different graphs, and then aggregating it into a cohesive view in the client layer. You're needlessly complicating your client-side code, adding network overhead, introducing consistency issues (different parts of data being at different states), and ...basically, undermining GraphQL itself.
Microservices are hard enough. Let's not sabotage it for ourselves.
Instead, let's talk about federated GraphQL as a solution to this, and see how WunderGraph Cosmo can help you implement federated graphs that augment your modular, microservices-based development, help you scale up and move fast without breaking things - and if you're coming from Apollo GraphOS? Migrate over with just one click.
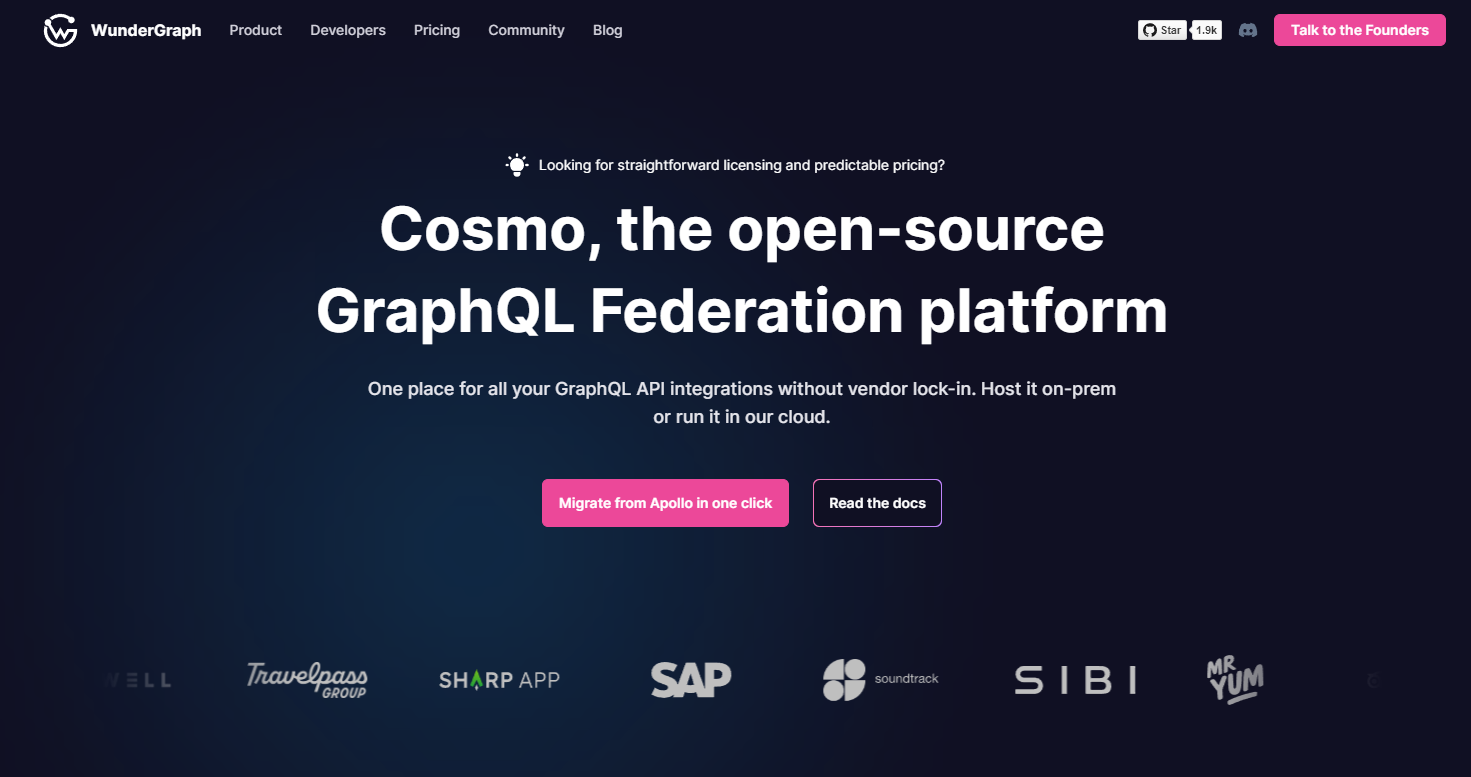
"Unified, but Decoupled."
Federation - an open architecture and specification created by Apollo - asks a simple question. What if you had a single, unified graph for all your data, seamlessly combining distributed services (with their own schema, server, and data) into a cohesive whole?
- Frontend devs win because they'd now have the simplicity of making requests to only one conceptual API for all the data that any client would need, rather than querying different graphs for different parts of the final data, and performing expensive, manual data composition in the client layer.
- Backend devs win because this approach means loose coupling between microservices - the individual graphs which contribute to the central, unified graph - meaning they can independently implement, maintain, and ship different schemas of their graph on their own release cycles, without being tightly coupled to other services. This flexibility allows teams to innovate and respond to requirements without waiting for a central release cycle.
- The organization as a whole wins because when you have a central graph, any new data you expose becomes instantly available to all teams - all you have to do is hook it up to the central graph. This creates emergent development opportunities where each team can adapt on the fly, and think of new, organic uses from this organizational data "pool", without needing to develop bespoke API/services for data.
To be clear, we're not talking about creating yet another monolith. Multiple independent GraphQL APIs (aka "subgraphs", each representing a distinct microservice with its own schema and data sources), are combined to form a unified GraphQL API that can be orchestrated with a Router/Gateway, the latter acting as a central entry point for client requests, and responsible for query decomposition, execution distribution, and result aggregation.
The Gateway (aka Router) analyzes the incoming queries against a "super" schema composed of all subgraph schemas, determines which microservices are responsible for each field, and dispatches the appropriate subqueries to these microservices. Each microservice resolves its own subqueries and returns the data. The Gateway then aggregates this data, and assembles a single response that conforms to the original query's structure. This response is then sent back to the client.
💡 If you were wondering, yes: federated graphs can, in turn, be federated, i.e. act as subgraphs themselves, adding to a bigger picture. Also, since they act as a single GraphQL API surface, you could use them in a conventional API Gateway/Backend-for-frontend setup, together with other, non-GraphQL data sources.
A federated GraphQL architecture is also a win re: progressive adoption of microservices. Throw a Federation gateway in front of your monolithic GraphQL API - then begin gradually shifting data logic from the monolith to the new microservices. Meanwhile, clients can query these federated sections through the unified schema, even though the data is now sourced from microservices. Your clients are none the wiser, being decoupled and completely blind to what's going on behind the Gateway.
When Apollo Federation is Not Enough
While federated GraphQL (and the Apollo Federation spec) undoubtedly revolutionizes how microservices-based systems can exist and scale within a GraphQL ecosystem, it's essential to recognize that there's more to using GraphQL in an enterprise environment than just composing a unified API.
What if you wanted:
- ...to deploy changes many times a day without worrying about breaking production - ensuring proposed changes to a subgraph wouldn't negatively impact other subgraphs, or existing clients?
- ...an intuitive user interface to explore and manage these subgraphs, federated graphs, schemas, and metrics?
- ...to create multiple variants of a federated graph, e.g. one for dev, one for prod?
- ...to automatically collect operational metrics across subgraphs, providing valuable insights into the system's health and usage patterns?
- ...to monitor which queries were causing the most load on the server, identify optimization opportunities, and address potential bottlenecks?
- ...do all of this while maintaining complete autonomy over your data?
The issue goes further than just the technical limitations of Apollo Federation. There's the elephant in the room: its license. Federation V2 is under the Elastic V2 license, which is an inherently prohibitive, enforceable, non-open source license:
- You cannot be a business that offers Federation as a hosted/managed service.
- You cannot incorporate Federation technology (or use its internal libraries) in your own software.
- It prohibits "resale" - meaning you cannot be a business that sells technology built using Federation, or even one that sells dedicated support for Federation setups, for example.
Now, credit where credit is due - Apollo has done a great job championing GraphQL as a whole - the Apollo Server and Client libraries are still MIT, as is the rest of their GraphQL catalog (apollo-rs, the rover CLI, and more). The hundreds of GraphQL libraries under the Apollo organization on GitHub is proof enough of them having done great work at opening up the GraphQL ecosystem since its inception.
But there's no denying that these limitations make it difficult for Federation to gain widespread enterprise adoption. The demand is clearly there, but Apollo Federation being owned and controlled by a single vendor actively holds back the ecosystem in this regard, at least.
And these technical and licensing limitations in the distributed GraphQL ecosystem are exactly what WunderGraph Cosmo was built to solve.
Introducing WunderGraph Cosmo
WunderGraph Cosmo is an open-source (Apache 2.0 License) platform for GraphQL Federation, without vendor lock-in. It is a fully self-hostable solution built on open standards that includes everything you could possibly want for building, connecting, and managing Federated Graphs at scale - routing, schema checks to prevent breaking changes, distributed tracing, analytics, and more, all in one platform.
With it, you can build modular, microservices-based architectures that can adapt and evolve over time, and scale while they're at it.
The Cosmo stack is opinionated, and optimized for maximum efficiency and performance. It includes:
- the Studio (GUI web interface) and the wgc (command-line tool) for managing the platform as a whole - schemas, users, and projects - and accessing analytics/traces.
- the Router as the component that actually implements GraphQL Federation, routing requests and aggregating responses.
- the Control Plane, the heart of the platform, providing the core APIs that both the Studio/CLI and the Router consume.
Cosmo supports Federation V1 and V2 (and standard monolithic GraphQL APIs, of course), and, critically, allows you to be flexible with your deployment, with no restrictions.
Want to fully DIY your architecture? Cosmo lets you retain full control over your data and run the entire platform locally, or on-premises, deployable to any Kubernetes service (AWS, Azure, or Google). Want a managed solution without worrying about infra? Host only the Router, and Cosmo will take care of everything else with dedicated infrastructure for each customer - security, upgrades, OTEL, SSO, global edge deployments and more - on a per-request pricing model.
The Architecture
1. The Cosmo CLI
Cosmo's command-line interface - wgc --- lets you manage the Cosmo platform as a whole - making it easy to create, publish, update, delete, or fix (with OpenAI integration) schemas, run validation checks on them, create new projects, manage users, and so on.
You install wgc through NPM like so:
npm install -g wgc
or
npx -y wgc@latest
Set the COSMO_API_KEY and COSMO_API_URL (the URL of your Control Plane) environment variables, and you're ready to use wgc to build, maintain, or otherwise manage GraphQL APIs seamlessly - whether subgraphs or federated graphs. The best part? All wgc commands interacting with the Cosmo platform can be used as part of your CI.
With the Cosmo CLI, creating federation-ready graphs is as simple as:
npx wgc subgraph create [subgraphName] --label [labelName] --routing-url [url]
Where:
labelNameis a key-value pair separated by a = sign (e.g. team=A) that identifies the exact subgraphs to be chosen for composition. This string can use logical AND and OR, and you can specify multiple labels with a comma. (e.g.--labels team=A,env=staging)urlis the service URL that the subgraph will be accessible at.
The labels and the intuitive Label Matching system enables you to create multiple environments - dev, staging, production, and so on - for each graph. For example, you could create a development schema like so:
npx wgc subgraph create messages --label team=A,env=dev --routing-url=http://localhost:4001/graphql
This schema could have its Message type include the verboseResponse field for testing various messaging scenarios in dev.
type Message @key(fields: "id") {
id: ID!
content: String!
sender: User!
recipient: User!
verboseResponse: Boolean!
}
And then create a production schema like so:
npx wgc subgraph create messages --label team=A,env=prod --routing-url=http://localhost:4001/graphql
This schema is streamlined, omitting the verboseResponse field in production.
type Message @key(fields: "id") {
id: ID!
content: String!
sender: User!
recipient: User!
}
Now, you can create two entirely different environments (or variants) of your federated graphs using the Cosmo CLI
For development
npx wgc federated-graph create production --routing-url http://your-dev-url/graphql --selector env=dev
For production
npx wgc federated-graph create production --routing-url http://api.yourapp.com/graphql --selector env=prod
Where selector is used to specify which labels should be used to choose subgraphs for federation.
Since each federated graph is a different router instance, each such environment you create would automatically have its own federated schema, change history, and metrics. Cosmo lets you create variations of your enterprise graphs to cater to different development and production needs, while maintaining your core data relationships.
2. The Studio
This is the user-friendly web interface that is the primary way to interact with, explore, and manage the graphs that you create. Think of it as a full-fledged admin dashboard - but for your Federated graphs - that combines a schema registry, and schema visualization, validation, and observability in one interface.
Inside the Studio, you can
- View all the federated graphs and subgraphs you own,
- Manage how your subgraphs are chosen for federation based on key-value pairs called Labels,
- See the latest state of your federated graph's schema, as well as the schema of its subgraphs, and download each as a .graphql file.
- See if there were any errors while composing multiple subgraph schemas into a federated one (such as type/field/enum mismatches), or if a proposed version of the federated schema was a breaking change (cannot go live without breaking existing functionality). In either case, here you can also view the exact reason for the error (and when it occurred), so it can be fixed.
- See a detailed history of all changes made to your federated graph's schema, in chronological order. Additions to types, fields, directives, or any other elements show up in green, while deletions show up as red. This is critical in understanding how your enterprise's federated graph has evolved over time, and helps you debug issues quicker.
- View a fine-grained breakdown of traffic to your federated graph, including all requests made to the router, organized (and filterable) by the operation performed, its date, the client making the request, and errors, if any.
- Trace the path taken by a request through the federated graph, the actual operation performed in the request, and errors, if any.
- Use an interactive GraphiQL Playground connected to your federated graph's router to explore your schema, write and execute GraphQL queries and mutations against it, to troubleshoot, replicate results, and optimize your operations.
3. The Router
The Cosmo Router is the central entry point to your federated GraphQL architecture. It is powered by [graphql-go-tools](https://github.com/wundergraph/graphql-go-tools), a GraphQL engine that is an open-source (MIT License) alternative to the Apollo Gateway (and is the fastest and most reliable implementation for Federation V1.), is fully stateless and designed to function independently, with the sole reliance being on a high-uptime CDN to load Router configuration, and is customizable with your own Go code.
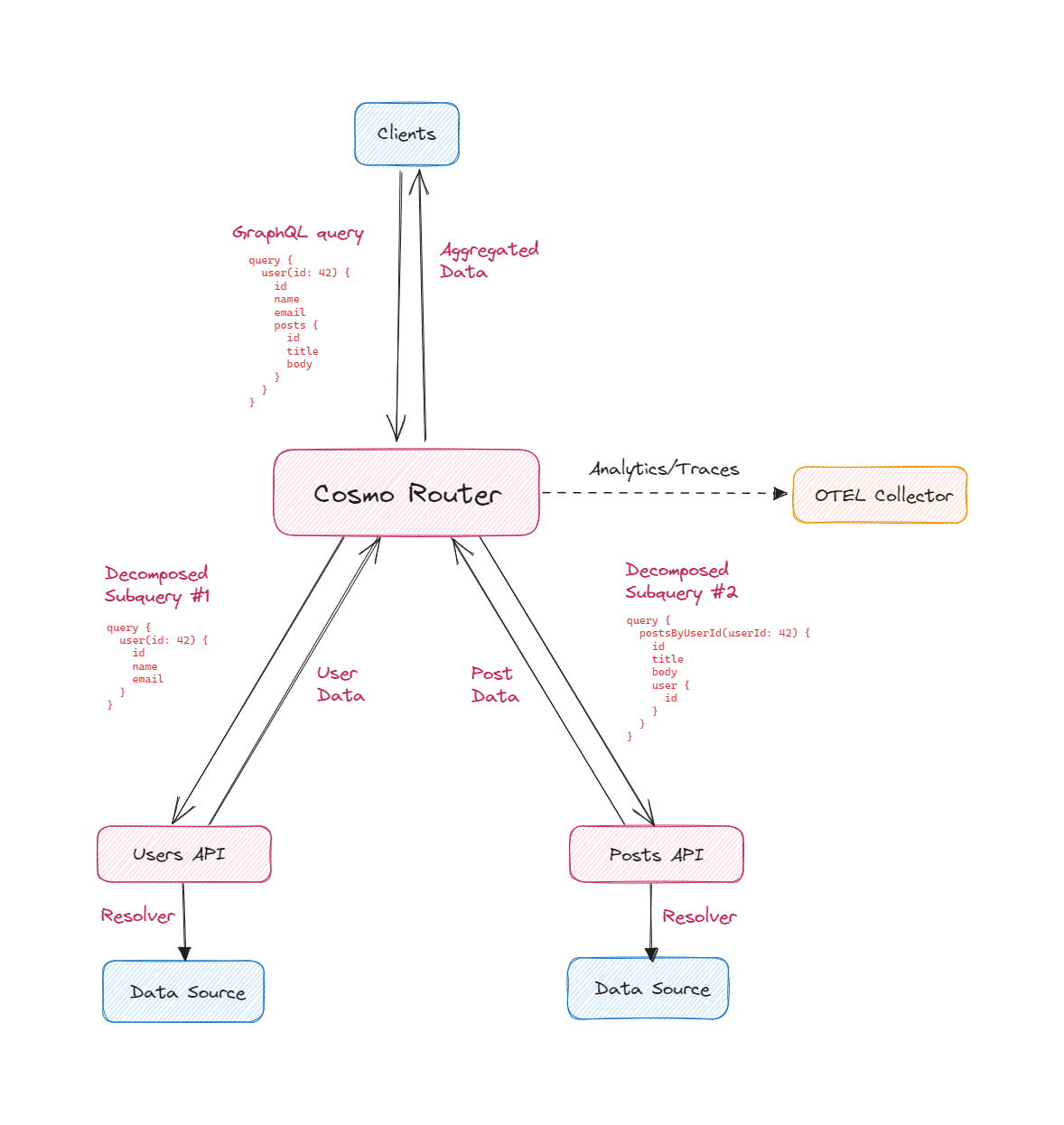
When a query arrives at the Router, it examines the query's fields, and using the Federated graph's schema (which includes the types, fields, and metadata of each subgraph schema) determines which microservices are responsible for providing the requested data. It then decomposes the client query into subqueries, routes them to the relevant microservices, collates the results it gets back from them, and combines and assembles that data into a cohesive response to be sent back to the client.
With Cosmo's Router, you also get built-in support for Prometheus - the battle-tested, open-source (Apache License) service monitoring system - and R.E.D metrics, meaning you'll have fine-grained insights into router traffic, the error/success rates or the average request/response times/sizes of specific operations, and the performance of your router in general.
4. The Control Plane
The Control Plane is what makes everything tick. It handles the communication with your routers, and exposes two core APIs:
- The Platform API - This is consumed by both the CLI (
wgc) and Cosmo Studio to do what they do - fetch, visualize, and manage your organization's graphs, publish schemas, run schema checks, attempt schema fixes with OpenAI, perform logging and analytics, orchestrate admin tasks, and more. - The Node API - This is consumed by the Router node(s) to register itself on first run, which allows it to report on the status and health of the router fleet.
Being the heart of Cosmo, the Control Plane also houses the environment variables that make all of Cosmo's integrations work together - the Clickhouse provider for analytics, the Postgres database that Cosmo uses for everything, OpenAI, auth, and Keycloak instances for SSO.
Working With Cosmo
When you're using federated GraphQL for microservices, what you're trying to do is build a large, seamless data pool for your organization that all your teams can pull from, for emergent use cases.
Cosmo was built to streamline just that.
With it, you create your organization, add users, set up JWT-based auth if you want, and then get started on creating subgraphs (or connect an existing one) with a single command using the CLI - using labels to organize them as you please - and then use their individual schemas to create a "super" schema. Each such Federated graph is a new physical Router or Gateway, ready to be queried by your clients.
Then, you can use Cosmo Studio to examine it and its subgraphs, make a few test queries with the GraphiQL Explorer, see metrics and analytics roll in for each request, down to fields and types of individual, decomposed subqueries.
You could even use your existing OpenTelemetry setup to push analytics data from your microservices (subgraphs) to the Cosmo platform, and combine them with Cosmo's distributed tracing from the Router for fine-grained insights into the lifecycle of every request, making sure you have all the data you need to track down performance/latency issues and optimize your services.
What if you wanted to add more subgraphs down the line? Or change existing subgraph schemas to add more fields/types/directives? No problem at all - add or change schemas as you want, then use the Cosmo CLI to run validation checks on the new, proposed schema, inspect the results of said validation checks in the Studio to make sure nothing goes wrong, and get detailed feedback to fix things when they do.
Migrating from Apollo GraphOS
If you're coming from Apollo's managed solution for federated GraphQL - GraphOS - moving to Cosmo's fully open source solution is as easy as copying over your project's API key from Apollo Studio, using the Migrate From Apollo option in your cosmo.wundergraph.com dashboard to paste it in, and running the docker run command it generates. That's it! It's that easy.
Here's a more complete migration guide.
In Summary...
Federation allows each microservice to maintain its own data graph while also contributing to an overarching schema (that forms a federated graph), and with it, teams can expose their data in a standardized and controlled manner, promoting data sharing without compromising team autonomy
But enterprise use cases require much more than just a unified API surface.
WunderGraph Cosmo addresses those needs - making sure you worry about nothing but growing your organization. Add the data you need, and see it available immediately to every team and client. And Cosmo will add everything else you need to grow, at every stage : graph visualization, metrics and traces, and schema checks and breaking change detection features that let you iterate rapidly without running into errors in production, and most importantly - do it with complete autonomy over your data if you so choose.
You have the option to self-host Cosmo completely, using Kubernetes, retaining full control of your data for compliance purposes, or just take the managed option where you run stateful components of the Cosmo platform on their cloud, while running the stateless, independent Cosmo Router on your own infrastructure. Find out more here.
Comments
Loading comments…